データ抽出や自動化を行う際に欠かせない技術の一つが「XPath」です。XPathは、HTMLやXMLドキュメント内から特定の情報を効率的に取得するための言語であり、スクレイピングやテスト自動化、APIレスポンス処理など、さまざまな場面で活用されています。適切に活用することで、複雑なデータ構造からも必要な情報を正確に抽出することが可能になります。
本記事では、XPathの基本的な仕組みから具体的な書き方、よく使われる関数や実践的なユースケースまでを詳しく解説します。スクレイピングや業務効率化を目指す方はもちろん、初めてXPathに触れる方にも役立つ内容となっていますので、ぜひ最後までご覧ください。
Xpathとは
XPathは、HTMLやXMLといったツリー構造のデータから、目的の情報を正確かつ効率的に指定・抽出するための技術です。
この章では、XPathの基本概念とユースケースについて解説します。
XPathの概要と活用例
「XPath」とは、XMLやHTMLドキュメントのツリー構造から特定の要素や属性を指定して抽出するための言語です。Webページは通常HTMLで構成されているため、スクレイピングやデータ取得、XMLデータの検索など、さまざまな場面でXPathが活用されています。
代表的な活用法は次の通りです。
- Webスクレイピングでのデータ抽出
ECサイトの商品情報やニュースサイトの記事タイトルなど、特定のデータを自動で取得する際にXPathが活用されます。
- XMLデータの検索・処理
業務システムやデータ連携処理では、XML形式でデータがやり取りされることが多くあります。XPathを使うことで、膨大なXMLデータの中から必要な情報だけを効率よく抽出できます。
- APIレスポンス(XML形式)の解析
SOAPなどのXMLベースのAPIを利用する場合、レスポンスデータの解析にXPathが用いられます。これにより、特定のステータスコードや結果データを迅速に取得でき、システム間連携や自動処理の精度向上に繋がります。
XPathの仕組み
HTMLやXMLでは、以下のようにタグでデータが囲まれています。
このタグは通常、開始タグ(例:<book>)と終了タグ(例:</book>)で構成されています。XPathを用いてこれらの要素にアクセスする際には、スラッシュ(/)を使用して各レベルを区切り、特定の要素に到達します。
この階層をスラッシュ(/)で区切りながら進むことで、目的の要素を指定します。イメージとしては、PCのフォルダ階層をたどる方法に似ています。
この階層をスラッシュ(/)で区切りながら進むことで、目的の要素を指定します。イメージとしては、PCのフォルダ階層をたどる方法に似ています。
例えば、書籍情報を管理するデータで「author」要素に到達する場合、以下のように記述します。
(例)
| /bookstore/book/author |

Webページの要素をルート(最上位階層)から順に指定する方法は「絶対パス(絶対XPath)」と呼ばれます。しかし、この手法ではパスが冗長になりやすく、サイト構造に変更が加えられた際にXPathの再設定が必要となるケースもあります。
(例)
| /html/body/div/div[1]/div[2]/div/div/span[1]/span[2]/span[3]… |
こうした課題を回避する手段として有効なのが、柔軟に要素を指定できる「相対パス(相対XPath)」です。// を用いることで、ドキュメント内の階層構造に依存せず、対象となる要素を指定することが可能になります。
| //author |
この方法を利用すれば、ページ構成が変更された場合でも影響を受けにくく、XPathの修正作業も簡単になります。XPathを効果的に活用するためには、絶対パスと相対パスを適切に使い分けることが重要です。
XPathを表示させる方法
XPathを活用するには、まず対象となる要素のXPathを取得する必要があります。ここでは、代表的な手段であるGoogle Chromeの開発者ツールを使った取得方法を紹介します。
Google Chromeでは、以下の手順で簡単にXPathを確認できます。
- 対象のWebページをChromeで開きます。
- F12キーを押し、開発者ツールを起動します。
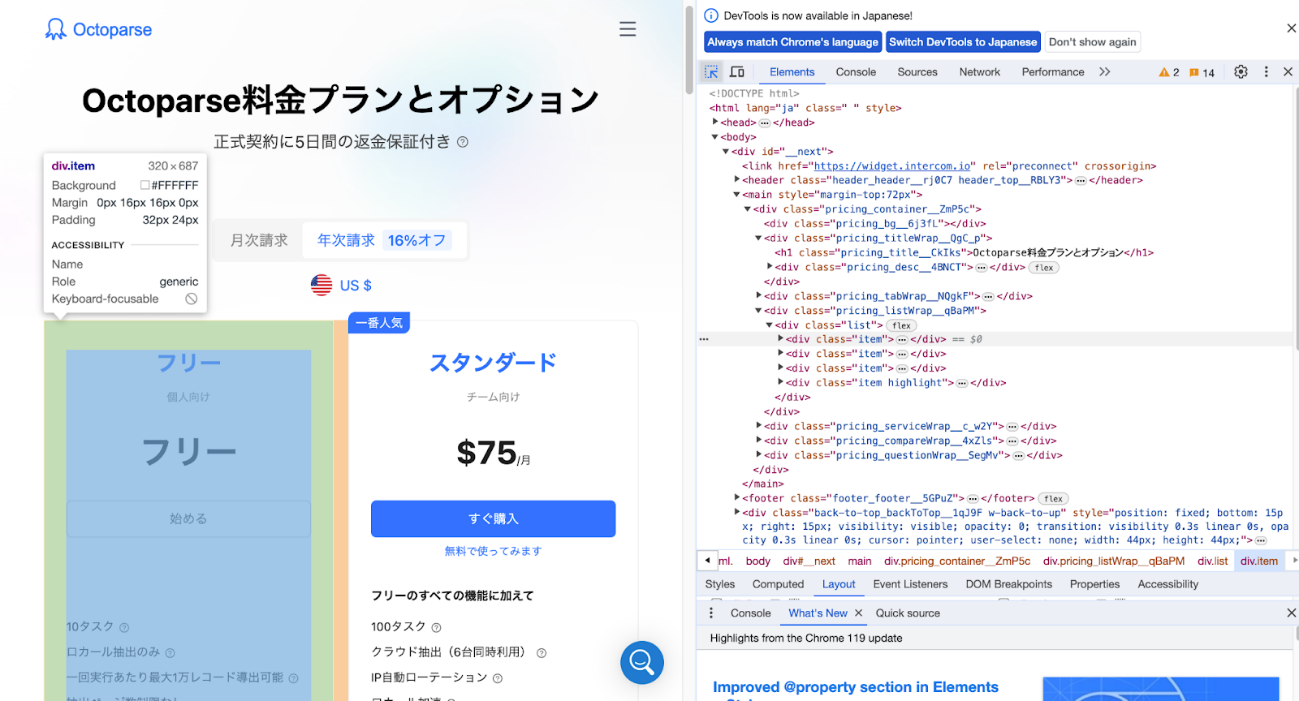
- 取得したい要素上で右クリックし、「検証」を選択します。
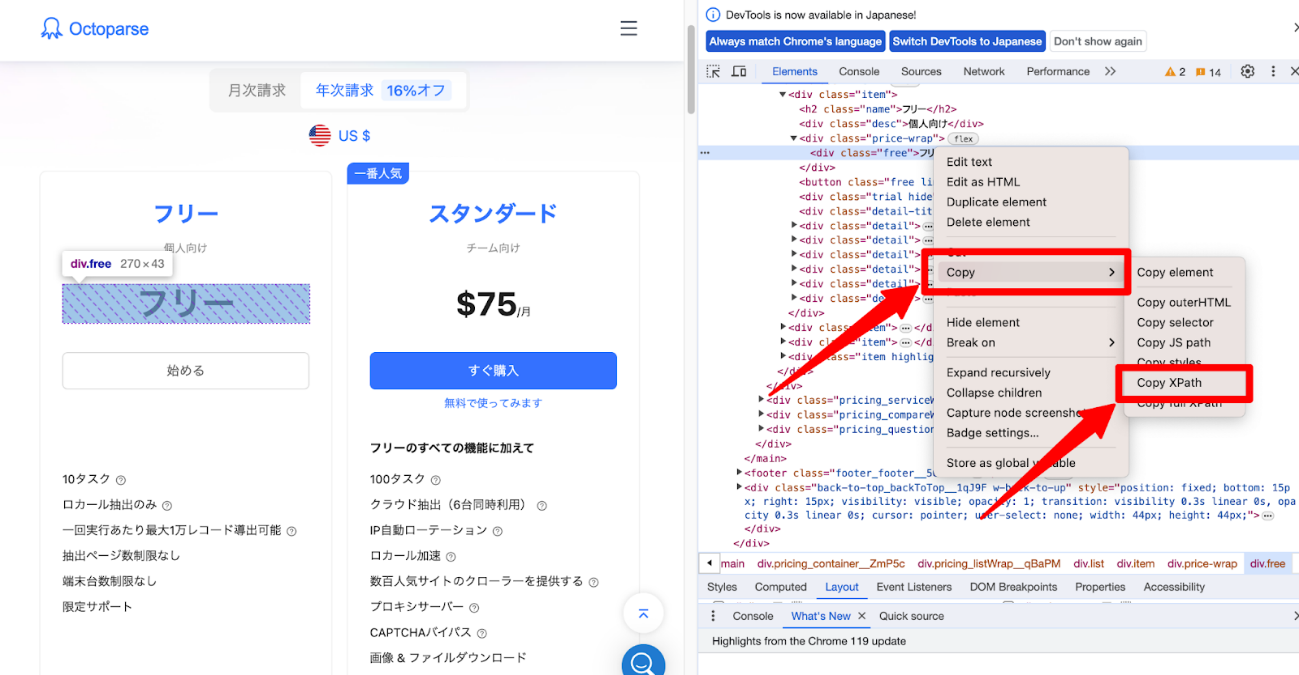
- 開発者ツール内で該当要素を右クリックし、「Copy」→「Copy XPath」を選びます。
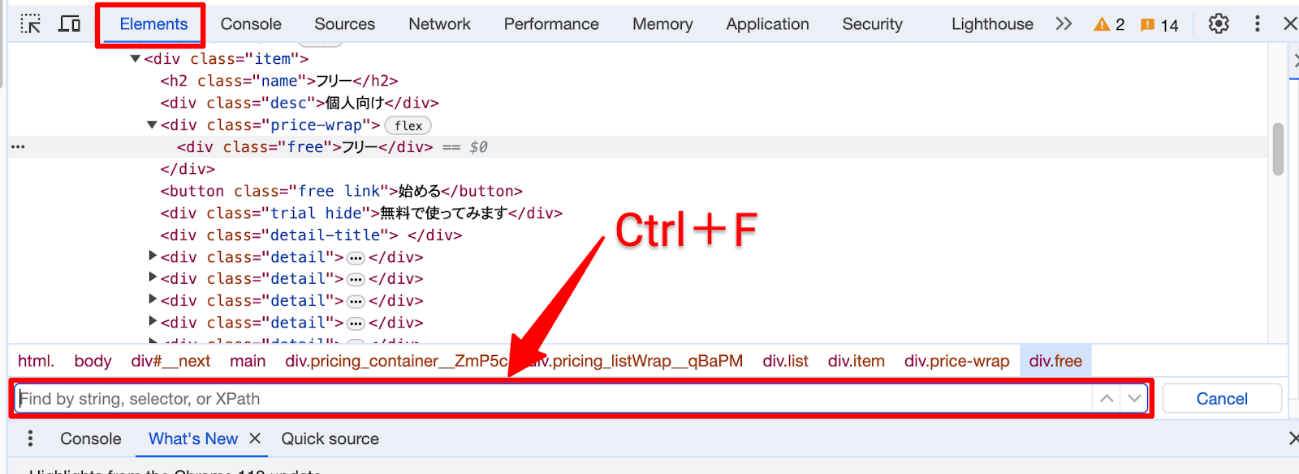
- Ctrl + F を押して検索バーに貼り付け、XPathが正しく機能するか確認する
また、より効率的にXPathを取得・確認したい場合は、XPath Helperなどの拡張機能を活用することで、リアルタイムにXPathの動作確認が可能です。
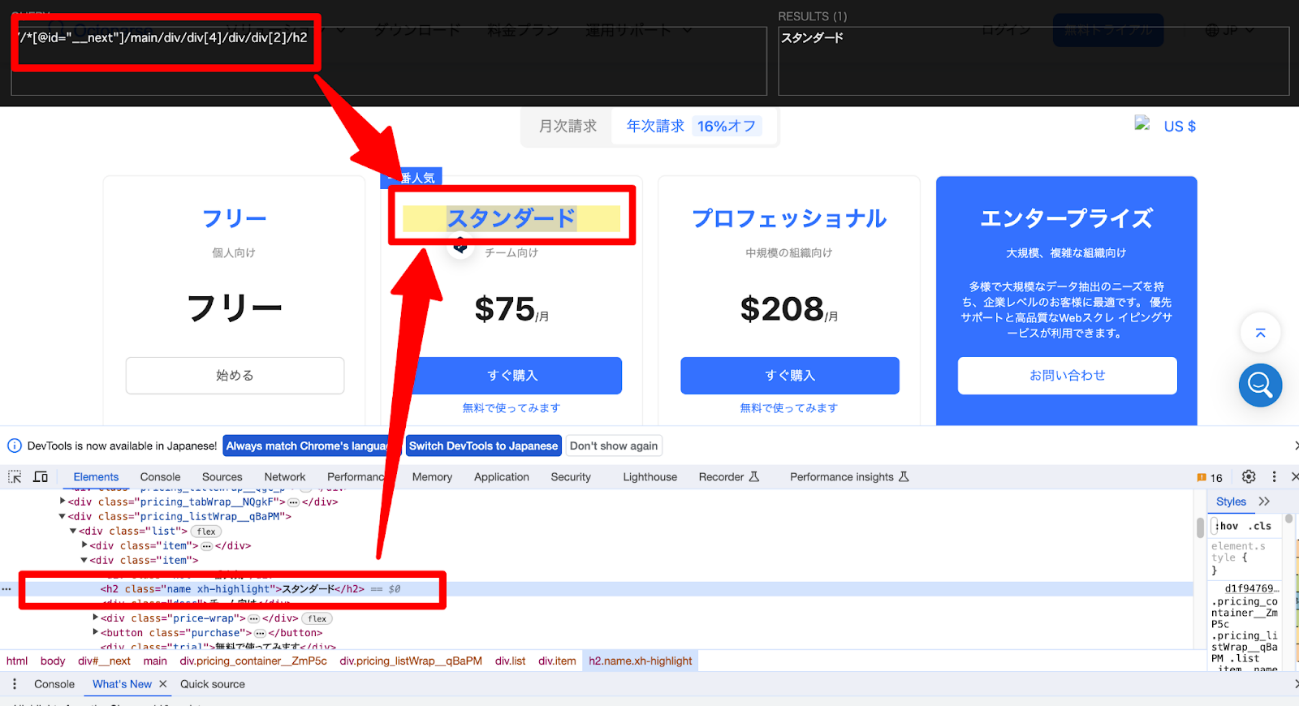
このように、ブラウザの機能とツールを組み合わせることで、精度の高いXPathを簡単に取得できます。
XPathの記述方法
XPathは、単に要素の位置を指定するだけでなく、タグ名や属性、テキストの内容、さらには要素同士の関係性を利用して、柔軟に対象を絞り込むことができます。
ここからは、実務で利用される4つの基本的な指定方法を解説します。これらを習得することで、複雑なHTMLやXMLの構造からでも、必要な情報を正確に抽出できるようになります。
タグ(要素)による指定
XPathの基本は、タグ名を使って要素を指定する方法です。HTMLやXMLはタグで構成されており、タグ名を記述することで該当する要素にアクセスできます。
例として、次のHTML構造を見てみましょう。
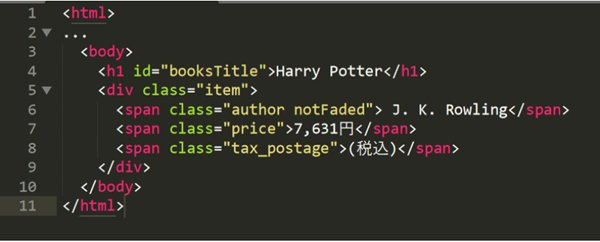
この例では、書籍タイトル「Harry Potter」が<h1>タグ内に記載されています。
ツリー図で示すと次の通りです。
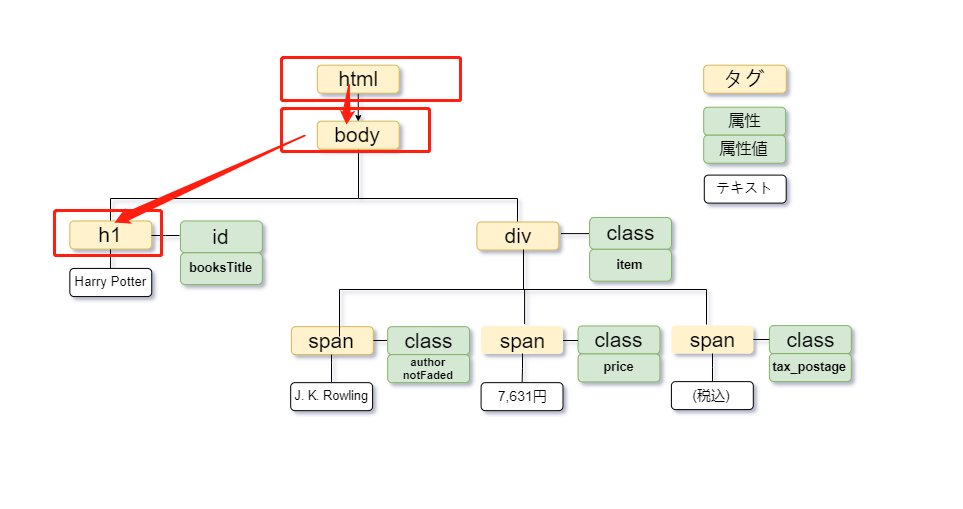
この要素を取得するためのXPathは、ドキュメントのルート(htmlタグ)から順にたどる絶対パスとして、次のように記述します。
| /html/body/h1 |
相対パスで記載する場合は、以下のように記述します。
| //h1 |
タグが複数ある場合は、角括弧[ ]を使って特定のタグを指定します。
例えば、span”7,631円”を取得したい場合、以下のように記述します。
| //div/span[2] |
属性による指定
HTMLやXMLでは、タグに属性(id や class など)が付与されていることが一般的です。XPathでは、この属性を利用することで、同じタグが複数存在する場合でも、特定の要素をピンポイントで指定することができます。
属性を指定する場合は、以下の形式で記述します。
| タグ名[@属性名=”属性値”] |
また、特定の属性値を持つどのようなタグも選択したい場合は以下のように記述します。
| //*[@属性名=”属性値”] |
属性指定の具体例として、まずは対象となるツリー図を確認しましょう。
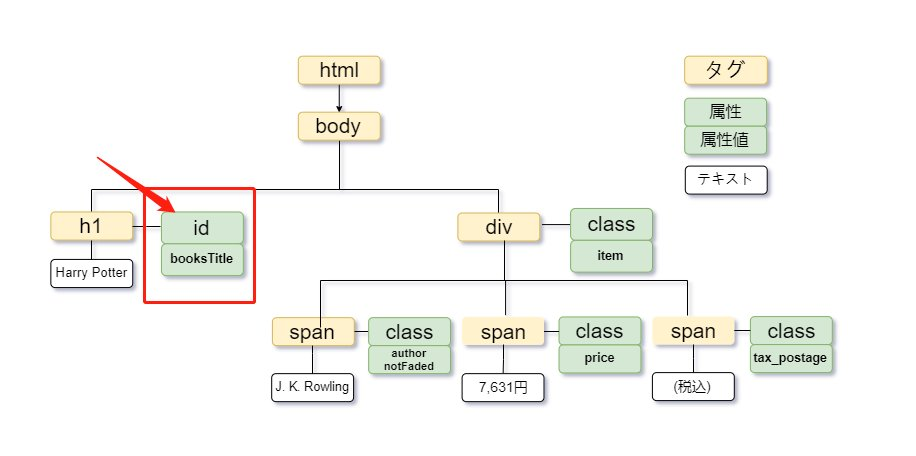
このように、書籍タイトル「Harry Potter」は、h1タグにid属性が付与されています。この要素をXPathで取得するには、次のように記述します。
| //h1[@id=”booksTitle”] |
属性による指定は、複雑なHTML構造の中から的確に必要な情報を抽出するための基本技術です。特に、id属性はページ内で一意に設定されることが多いため、優先的に活用すると良いでしょう。
テキストによる指定
XPathでは、タグ名や属性だけでなく、要素内のテキスト内容を使って特定の要素を指定することも可能です。特に、属性情報が設定されていない場合や、表示されているテキストを基準に抽出したい場合に有効な方法です。
テキストによる指定は、次のような構文で記述します。
| //タグ名[text()=”テキスト内容”] |
例えば、「7,631円」を取得するには、次のように記述します。
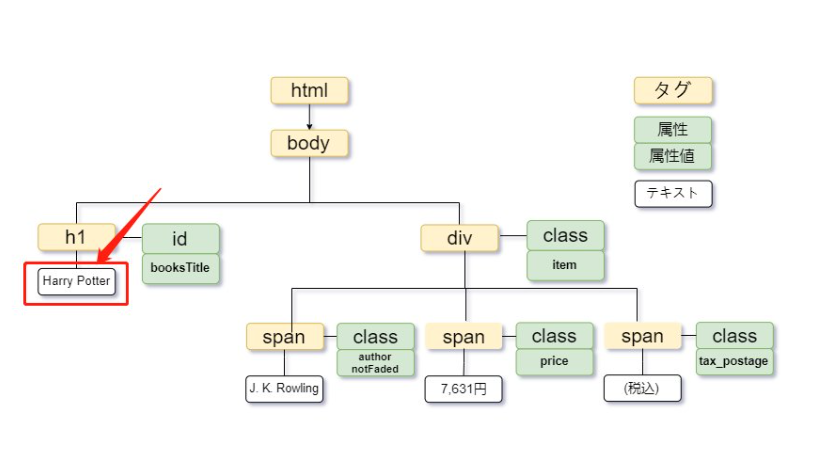
| //h1[text()=”Harry Potter”] |
これにより、テキストが完全に一致する要素をピンポイントで取得できます。ただし、スペースや表記の違いがあると一致しないため注意が必要です。
タグ関係で指定する
XPathでは、タグ同士の親子関係や兄弟関係を利用して要素を指定することも可能です。これにより、特定の位置にある要素や、関連する要素を柔軟に抽出できます。
親子や兄弟関係に基づくXPathの抽象的な構文は以下の通りです。
| 親要素 | //基点要素のタグ名/.. |
| 子要素 | //基点要素のタグ名/子要素のタグ名 |
| 子孫要素 | //基点要素のタグ名//子孫要素のタグ名 |
| より後の兄弟要素 | //基点要素のタグ名/following-sibling::より後の兄弟要素のタグ名 |
| より前の兄弟要素 | //基点要素のタグ名/preceding-sibling::より前の兄弟要素のタグ名 |
再度、ハリーポッターのHTML例から「7,631円」を取得する場合、以下のように指定可能です。
- <div> の子要素として指定する場合
| //div/span[2] |
- <body> の子孫要素として指定する場合
| //body//span[2] |
- author notFaded クラスを持つ要素の直後の兄弟を指定する場合
| //span[@class=”author notFaded”]/following-sibling::span[1] |
- tax_postage クラスを持つ要素の直前の兄弟を指定する場合
| //span[@class=”tax_postage”]/preceding-sibling::span[1] |
このように、タグ同士の関係性を活用することで、属性がなくても柔軟にデータを取得できます。特に、ラベルと値がセットになっている場合や、シンプルなHTML構造に有効な手法です。
XPathでよく使う関数
XPathは、タグ名や属性を使った基本的な指定方法だけでも十分に要素を抽出できますが、実際のWebページやXMLデータは複雑な構造になっていることが多く、単純な記述では対応できないケースもあります。
そこで役立つのが、XPathの関数です。
関数を利用することで、部分一致や柔軟な条件指定、位置の特定など、より高度な要素抽出が可能になります。ここからは、XPathでよく利用される関数を解説します。
contains():特定の文字列を含む要素を指定
XPathのcontains関数は、特定の文字列が含まれている要素を柔軟に指定するための関数です。特に、class属性のように値が一定でない場合や、部分一致で要素を取得したい場面で活用されます。
基本構文は以下の通りです。
| contains(対象, “部分文字列”) |
例えば、次のようなHTMLコードがあったとします。
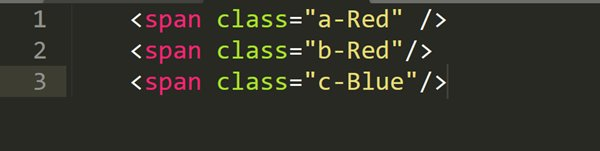
この場合、「class属性に”Red”を含むspanタグ」を取得したい場合は、次のように記述します。
| //span[contains(@class, “Red”)] |
このXPathは、class属性の値に「Red」が含まれるすべてのspanタグを対象とします。上記の例では、1つ目と2つ目のspanタグが該当します。
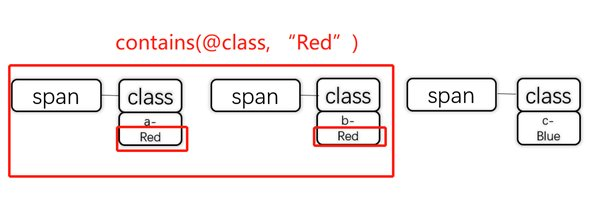
また、先ほどのハリーポッターのHTMLコードのような、クラスが複数設定されているケースでも有効です。
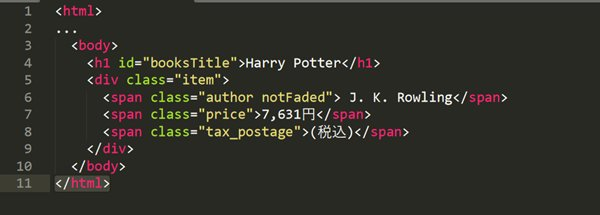
この場合も、以下のように記述することで対象要素を柔軟に取得できます。
| //span[contains(@class, “author”)] |
このように、contains関数は完全一致では対応できない曖昧な条件に対して役に立ちます。特に、命名規則で共通の文字列が含まれる場合や、動的に変化するクラス名のパターンを扱う際に活用しましょう。
position():特定位置の要素を指定する
position関数は、繰り返し構造の中から特定の位置にある要素を取得したい場合に使用します。リストやテーブルのように同じタグが並ぶ場面で、柔軟に要素を絞り込むことが可能です。
例えば、次のようなHTML構造があるとします。
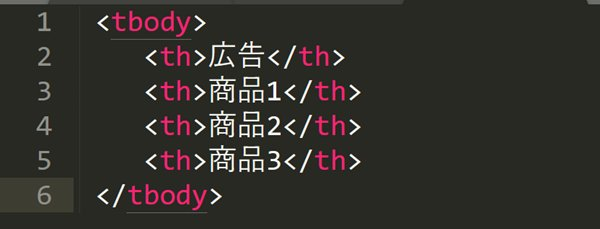
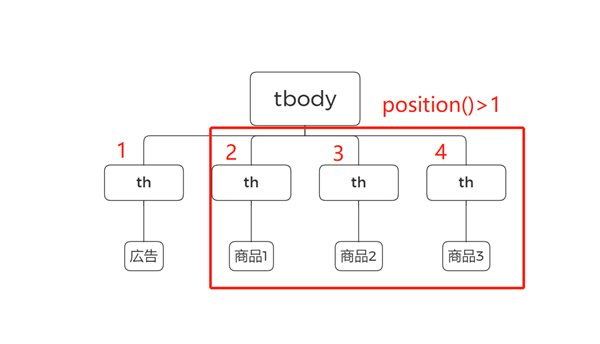
この例では、<tbody>内に4つの<th>タグがあり、先頭の「広告」は除外して、「商品1」「商品2」「商品3」だけを取得したい場合にposition()を使います。
このケースでは、次のように記述します。
| //tbody/th[position() > 1] |
このXPathは、<tbody>直下にある<th>タグのうち、2番目以降の要素をすべて取得可能です。
その他にも、position関数は次のように使い分けができます。
- 特定の位置を指定
//tbody/th[position()=2] → 2番目の要素を取得
- 範囲指定
//tbody/th[position()<=3] → 1〜3番目までを取得
この関数を使うことで、単純なインデックス指定よりも柔軟にリストやテーブルデータを操作できるため、繰り返し構造を扱う際には非常に役立ちます。
and / not / or:複数の条件を指定
XPathでは、and / or / not を使うことで複数の条件を組み合わせ、より柔軟に要素を指定できます。
and関数
andは、「両方の条件を満たす場合」に要素を取得します。
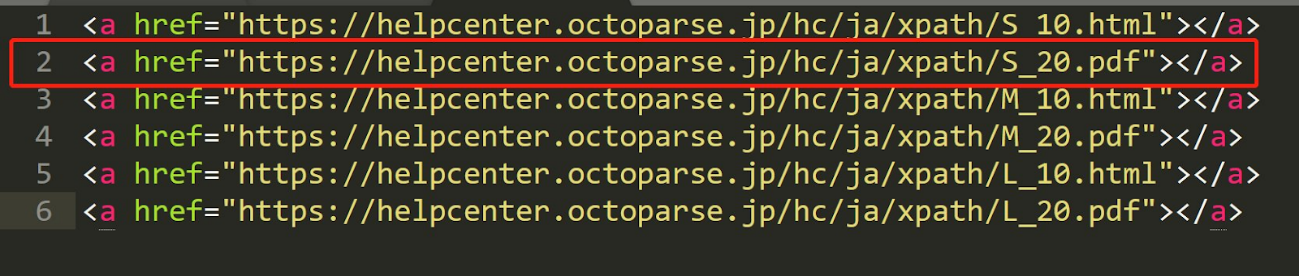
上記HTMLから、「S_20」と「pdf」を含むhrefを取得したい場合は、次のように記述します。
| //a[contains(@href,”S_20″) and contains(@href,”pdf”)] |
not関数
not関数は、「特定の条件を満たさない要素」を指定する際に使用します。
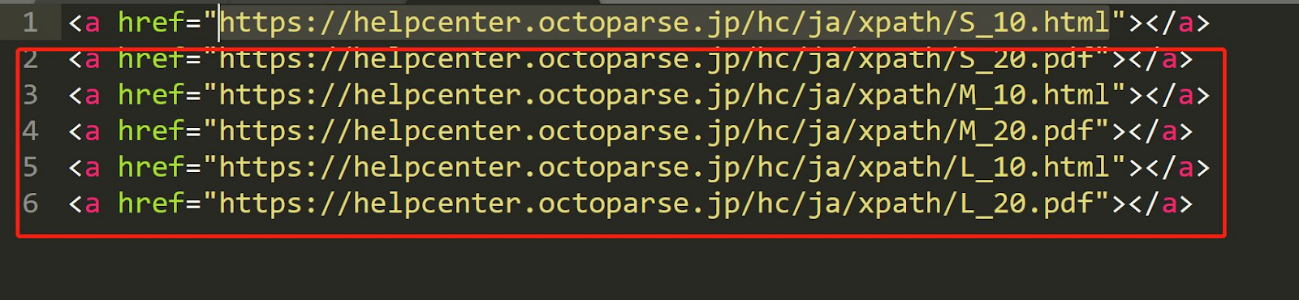
「S_10.html」を含まないhref属性を持つ要素を取得したい場合は、次のように書きます。
| //a[not(contains(@href, “S_10”))] |
or関数
or関数は、「いずれかの条件を満たす場合」に要素を取得します。

MかLを含むhrefを取得したい場合は、以下の通りです。
| //a[contains(@href,”M_”) or contains(@href,”L_”)] |
また、MかL以外のhrefを取得したい場合は、notとorを組み合わせます。
| //a[not(contains(@href,”M_”) or contains(@href,”L_”))] |
まとめ
XPathを活用することで、HTMLやXMLドキュメントから特定のデータを効率よく抽出できます。基本のタグ指定や属性指定に加え、関数やタグ同士の関係性を活用することで、複雑な構造にも柔軟に対応可能です。スクレイピングや自動化、データ処理など幅広い場面で利用されるXPathは、適切に使いこなすことで作業効率を大幅に向上させることができます。
本記事を参考に、ぜひXPathの活用幅を広げてみてください。

ウェブサイトのデータを、Excel、CSV、Google Sheets、お好みのデータベースに直接変換。
自動検出機能搭載で、プログラミング不要の簡単データ抽出。
人気サイト向けテンプレート完備。クリック数回でデータ取得可能。
IPプロキシと高度なAPIで、ブロック対策も万全。
クラウドサービスで、いつでも好きな時にスクレイピングをスケジュール。



