近年、「ビッグデータ」の注目に伴い、ビッグデータを活用するための手段として、「データマイニング」にもよく耳にします。「データマイニング」とは、そもそもどのようなものなのでしょうか?
データマイニングとは
データマイニング(Data mining)とは、その言葉の示す通り、膨大なデータから有効な情報を採掘(マイニング)する技術です。大量のデータを統計学や人工知能などの分析手法を使って、データの相関関係や隠れたパターンなどを見つけるための解析方法です。
データマイニングはデータサイエンスの分野における重要な技術です。Glassdoorの「アメリカの仕事ランキングTOP50」のリストでは、データマイニングは、2018年から2021年にかけてアメリカで第1位と評価されています。
その上、2018年の17000件の求人情報と比べて、求人の件数は2年間で160%大幅に増加しました。データサイエンティストやデータ分析スキルを持っている人に対する需要は今後数年間で増加し続けると予想することができます。
この記事では、データマイニングについての基本的なことから、データマイニングに必要なスキルについてご説明します。
コンピュータサイエンススキル
1. プログラミング/統計言語:R、Python、C ++、Java、Matlab、SQL、SAS、Unixシェル/ awk / sed…
データマイニングはプログラミングに大きく依存していますが、データマイニングに最適な言語はどちらという疑問についての結論はありません。もちろん、どちらかというと、扱うデータセットの次第です。KD Nuggetsの調査によると、RとPythonはデータサイエンスに最も人気のプログラミング言語です。
| より多くのリソース:データサイエンスのためにどの言語を学ぶべきか [Freecode Camp]Rにおけるデータマイニングアルゴリズム [Wikibooks]データマイニングに最適なPythonモジュール [KD Nuggets] |
2. ビッグデータプロセッシングフレームワーク:Hadoop、Storm、Samza、Spark、Flink
プロセッシングフレームワークは、不揮発性メモリからデータを読み取り、データをデータシステムに取り込むように、システム内のデータを計算します。これは、大量の個々のデータポイントから情報を抽出し、洞察を得るプロセスです。batch-only、stream-only、hybridの3つに分類できます。
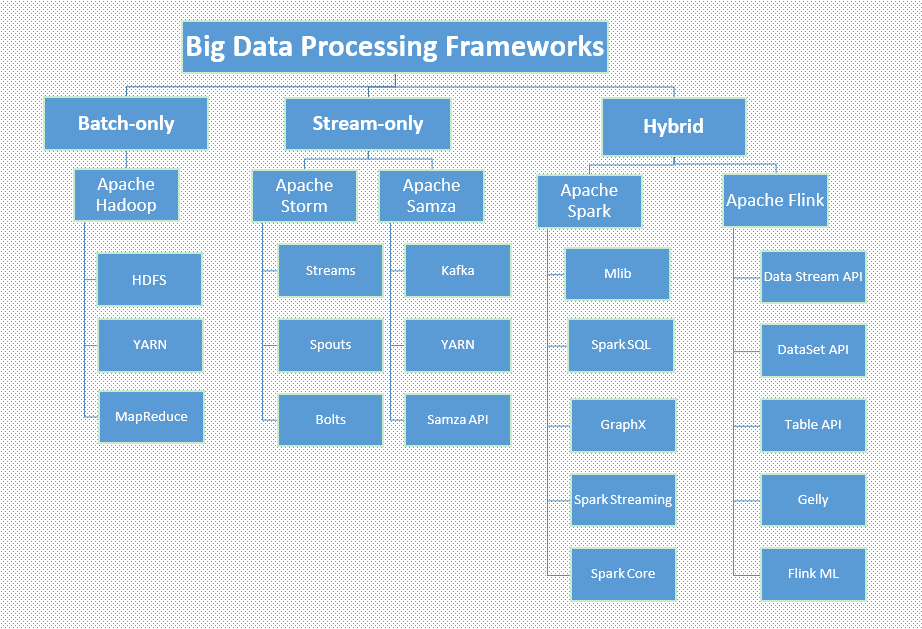
HadoopとSparkは今まで最も実装されているフレームワークです。Hadoopは、時間に左右されないバッチワークロードに適したオプションであり、他のものよりも実装コストが低いです。一方、Sparkは混在するワークロードに適したオプションであり、ストリームの高速バッチ処理とマイクロバッチ処理を提供します。
| より多くのリソース:Hadoop、Storm、Samza、Spark、Flink:ビッグデータフレームワークの比較 [Digital Ocean]データマイニングのためのデータプロセッシングフレームワーク[Google Scholar] |
3. オペレーティングシステム:Linux
Linuxはデータマイニング科学者に人気のあるオペレーティングシステムで、より安定で効率で大規模なデータセットを操作することができます。Linuxの一般的なコマンドについて知っていて、LinuxにSpark分散型機械学習システムを導入できれば、それはプラスになります。
| より多くのリソース:なぜデータサイエンスとRにLinuxを使うべきなのか [Samurai Blog] |
4. データベースの知識:リレーショナルデータベースと非リレーショナルデータベース
大規模なデータセットを管理および処理するには、SQLやOracleなどのリレーショナルデータベース、または非リレーショナルデータベースに関する知識が必要です。非リレーショナルデータベースの主な種類は:列:Cassandra、HBase;ドキュメント:MongoDB、CouchDB;キー値:Redis、Dynamo。
統計とアルゴリズムのスキル
5. 基本的な統計知識:確率、確率分布、相関、回帰、線形代数、確率過程…
データマイニングの定義を思い出してください。データマイニングはコーディングやコンピュータサイエンスに関するものだけではなく、複数の分野の間にある接点であることがわかっています。統計学は、データマイナーにとって不可欠な基本的な知識です。これにより、質問を特定し、より正確な結論を導き、因果関係と相関関係を区別し、さらに発見事項の確実性を定量化することができます。
| より多くのリソース:データサイエンスを行うために知っておくべき統計学 [Quora]データマイニングのための統計手法 [Research Gate] |
6. データ構造とアルゴリズム
データ構造には、配列、連結リスト、スタック、キュー、木構造、ハッシュテーブル、セットなどがあります。一般的なアルゴリズムには、ソートアル、検索、動的計画法、再帰などがあります。
データ構造とアルゴリズムに熟達すれば、データマイニングに非常に役立ちます。これは、大量のデータを処理するときに、より創造的で効率的なアルゴリズムソリューションを思い付くのに役立ちます。
| より多くのリソース:データ、構造、およびデータサイエンスパイプライン [IBM Developer]Coursera:データ構造とアルゴリズム [UNIVERSITY OF CALIFORNIA SAN DIEGO] |
7. 機械学習/ディープラーニングアルゴリズム
これはデータマイニングの最も重要な部分の1つです。機械学習アルゴリズムは、タスクを実行するように明示的にプログラムされることなく、予測または決定を行うためにサンプルデータの数学モデルを構築します。そして、ディープラーニングは、より幅広い機械学習手法の一部です。機械学習とデータマイニングは常に同じ方法を採用し、かなり重複します。
| より多くのリソース:PythonおよびRコードを使用した機械学習アルゴリズムの要領 [Analytics Vidhya]素晴らしい機械学習フレームワーク、ライブラリ、およびソフトウェアのキュレーションリスト(言語別) [Github josephmisiti] |
8 自然言語処理
自然言語処理(NLP)は、コンピュータサイエンスと人工知能のサブフィールドとして、コンピュータが人間の言語を理解し、解釈し、操作するのを助けます。NLPは、単語のセグメンテーション、構文および意味分析、自動要約、およびテキスト含意に広く使用されています。大量のテキストを処理する必要があるデータマイナーにとって、NLPアルゴリズムを知ることは必須のスキルです。
| より多くのリソース:データサイエンティスト向けの10のNLPタスク [Analytics Vidhya]素晴らしい機械学習フレームワーク、ライブラリ、およびソフトウェアのキュレーションリスト(言語別) [Github josephmisiti]オープンソースのNLPライブラリ: Standford NLP; Apache OpenNLP; Naturel Language Toolkit |
その他
9. プロジェクト経験
プロジェクト経験はあなたのデータマイニングスキルを一番楽な証明です。DataCampのチーフデータサイエンティスト、デービッドロビンソン氏は次のように述べています。「私にとって最も効果的な戦略は公共事業を行うことでした。私は博士号の後半にブログを書き、多くのオープンソース開発を行いました。これらは私のデータサイエンススキルの公開証拠を与えるのを助けました。」
10. コミュニケーションとプレゼンテーションのスキル
データマイナーはデータを扱うだけでなく、データから引き出された結果や洞察を他の人、さらにはマーケティングチームなどの非技術者にも説明する責任があります。ですから、データの結果を解釈し、物語を口頭で、書面で、そしてプレゼンテーションでうまく伝えることができるはずです。




