Webスクレイピングは、営業リスト作成、価格調査、競合分析、市場調査などに役立つ便利なデータ収集手段です。一方で、短時間に大量のアクセスを行ったり、対象サイトのルールを確認せずに実行したりすると、403エラー、429エラー、CAPTCHA、IP制限などにより、データ収集が途中で止まってしまうことがあります。
スクレイピングのブロック回避で大切なのは、サイトの防御を無理に突破することではありません。対象サイトへの負荷を抑え、公開情報の範囲を確認し、自然で安定したアクセス間隔に調整することです。本記事では、スクレイピングがブロックされる原因と、安全にブロックリスクを下げるための対策、さらにOctoparseをで設定できる実践的な方法を解説します。
この記事でわかること
- スクレイピングがブロックされる主な原因
- 403・429・CAPTCHAなどのエラーが起きる理由
- ブロック回避の前に確認すべき法務・利用規約・robots.txtのポイント
- 待機時間、プロキシ、User-Agent、Ajaxなどの基本対策
- Octoparseでブロッキング対策を設定する手順
- やってはいけない危険なブロック回避
また、Webスクレイピングの利用に不安を感じる方は以下の記事もあわせてご参照ください。
スクレイピングは違法?Webスクレイピングに関する10のよくある誤解!
スクレイピングとは
スクレイピングとは、Webサイト上のデータを自動的に抽出する技術です。この技術を活用することで、手作業では取得が困難な大量の情報を、短時間で効率的に収集できます。例えば、商品の価格情報やレビュー、競合他社の動向など、さまざまなデータを効率よく取得し、マーケティングやリサーチに活用可能です。
一方で、スクレイピングを行う際には注意も必要です。過剰なアクセスにより対象サーバーへ過度な負荷がかかると、最悪の場合はサーバーダウンを招くおそれがあります。
こうした背景から、Webサイトの所有者側も対策を強化しており、多くのサイトではスクレイピング防止技術が導入されています。その結果として、Webスクレイピングはより困難になっています。また、Webサイト所有者がスクレイピングを悪質であると判断した場合には、損害賠償責任や偽計業務妨害罪に問われるリスクもあります。
スクレイピングのメリット
ルールを守ってスクレイピングを行えば、業務の効率化や意思決定の精度向上につながります。
ここでは、ビジネスやリサーチの現場で注目されている、スクレイピングのメリットをご紹介します。
データ収集効率化
スクレイピングの最大のメリットは、データ収集の効率化です。手作業で行う場合、多くの時間と労力を要するデータ収集も、スクレイピングツールを使えば自動的に短時間で完了します。
例えば、数百件の商品価格を手作業で調査するのは非効率であり、業務委託やアルバイトを使う場合は人件費の負担が発生します。スクレイピングを活用すれば、必要なデータを短時間で一括取得でき、コストを抑えつつ作業の自動化が実現できます。業務の効率化によって、戦略立案や意思決定のスピードも向上します。
APIが共有していないデータを取得できる
多くのウェブサービスはAPIを提供していますが、全てのデータがAPI経由で取得できるわけではありません。スクレイピングを利用すれば、画面上に表示されている情報を直接取得できるため、APIが提供していないデータも取得可能です。
例えば、特定の商品の詳細なレビューや、ユーザーコメントなど、APIでは取得できない情報もスクレイピングであれば収集することができます。これにより、より豊富なデータセットを活用して、精緻な分析やインサイトの獲得が可能となります。
ビジネスや研究で広範に利用できる
スクレイピングは、ビジネスや研究の現場で幅広く活用されています。たとえば、競合分析、市場調査、SEO対策などの分野では、公開されているWebデータをもとに状況を把握し、施策の検討や動向の把握に利用されています。
また、スクレイピングはAI分野においても重要な手段の一つです。自然言語処理や画像認識などのモデルを訓練する際、大量の教師データを収集する必要があり、Web上のデータを効率的に取得する方法として活用されています。
スクレイピングのデメリット
スクレイピングには多くのメリットがある一方で、デメリットも存在します。ここでは、スクレイピングのデメリットをご紹介します。
技術の習得に時間がかかる
スクレイピングを行うためには、ITの知識が必要不可欠です。具体的には、サーバーやプログラミングの理解や、Webページの構造を示すHTMLやCSSの内容を読み解く力が求められます。
また、Webサイトごとに異なるページ構成に対応したスクリプトの作成や、アクセス制限への対策も必要です。これらの作業を実務で活用できるレベルまで習得するには、時間と労力が必要です。そのため、限られた期間で導入し、実用的な成果を上げることは困難と言えるでしょう。
継続的なメンテナンスが必要
スクレイピングは初期構築を行えば終わりというものではなく、継続的なメンテナンスが必要です。多くのWebサイトは、定期的にHTML構造やクラス名、ページ構成を変更しており、それに伴ってスクレイピングスクリプトが正常に動作しなくなる可能性があります。
そのため、スクレイピングを安定的に運用するには、定期的な動作確認やコードの修正が不可欠です。
リソースによる制限
スクレイピングツールを安定して運用するには、利用するPCの処理能力やインターネット環境も重要です。スペックが不足している場合、処理が途中終了する場合やデータが上手く保存されない場合があります。また、動作中はPCを停止できないため、業務に支障が出ることもあります。
他にも、社内LANを利用している場合は、他の業務システムに影響を及ぼす可能性もあるため、スクレイピングを実行する時間帯や頻度には配慮が必要です。安定した運用のためには、ツールの仕様だけでなく、実行環境にも目を向ける必要があります。
スクレイピングでブロックされる主な原因
サイト側がスクレイピングを検知する理由は一つではありません。単純なアクセス頻度だけでなく、IPアドレス、HTTPヘッダー、ブラウザ情報、Cookie、JavaScriptの挙動、クリックやスクロールのパターンなど、複数の要素を組み合わせて判断されることがあります。
| 原因 | よくある症状 | 見直すべきポイント |
| アクセス頻度が高すぎる | 429 Too Many Requests、途中停止、アクセス制限 | 待機時間、同時実行数、ページ送り間隔を調整する |
| 同じIPから大量アクセスしている | IPブロック、403エラー、一定時間アクセス不可 | 取得範囲を分割し、必要に応じてプロキシを利用する |
| User-Agentやヘッダーが不自然 | 403エラー、ページが表示されない | 実際のブラウザに近いUAを使用し、古いUAを避ける |
| Cookieやセッションを維持できない | ログイン後ページが取得できない、毎回認証画面に戻る | 許可された範囲でCookie・セッションを保持する |
| JavaScriptやAjaxの読み込みを待てていない | データが空白、途中までしか取得できない | Ajaxタイムアウト、スクロール、待機条件を設定する |
| 機械的なクリック・ページ遷移 | CAPTCHA、行動分析による制限 | クリック順序やページ送りを自然にし、短時間の連続実行を避ける |
| 隠しリンク・不要要素にアクセスしている | 突然のブロック、想定外URLへの遷移 | 表示されている要素だけを対象にし、XPathを見直す |
| 利用規約やrobots.txtに反している | 警告、アクセス停止、法的リスク | API、オープンデータ、許可された取得範囲を優先する |
ブロック回避の前に確認すべきルール
スクレイピングのブロックを回避したい場合でも、まず確認すべきなのは技術的な設定ではなく、対象サイトのルールです。技術的に取得できることと、業務として安全に取得・利用できることは別です。
- 対象サイトの利用規約でスクレイピングや自動アクセスが禁止されていないか確認する
- robots.txtでクロール方針や禁止範囲を確認する
- 公式API、データ提供、オープンデータがある場合はそちらを優先する
- ログイン後ページ、会員限定情報、有料情報は、契約範囲や利用許諾を確認する
- 個人情報、著作権で保護された文章・画像、機密情報は取得・保存・再利用の可否を慎重に確認する
- 対象サイトに過度な負荷を与えないよう、取得頻度・件数・実行時間帯を調整する
この確認を行うことで、単なる「ブロック回避」ではなく、継続的に運用できる安全なデータ収集体制を作ることができます。
スクレイピングのブロックを回避する10の対策
1. リクエスト間隔を広げる
短時間に大量のページへアクセスすると、サイト側に自動アクセスと判断されやすくなります。まずは実行速度を落とし、ページ遷移・クリック・データ抽出の各ステップに待機時間を入れましょう。固定の1秒間隔で連続アクセスするより、数秒から十数秒の範囲で余裕を持たせる方が安定しやすくなります。
2. 同時実行数を抑える
大量データを取得したい場合でも、同時に多数のタスクを走らせると、対象サイトへの負荷が急増します。まずは小規模なテストを行い、問題がなければ少しずつ件数を増やすのが安全です。クラウド実行でも、対象サイトの応答速度が遅い場合はタスクを分割し、実行時間を分散させましょう。
3. 取得範囲を分割する
検索条件が広すぎるURLや、数万件以上の結果を一度に処理するタスクは、途中停止や制限の原因になります。地域、カテゴリ、日付、ページ番号などでURLを分割し、1回あたりの取得件数を小さくすることで、安定性が上がります。
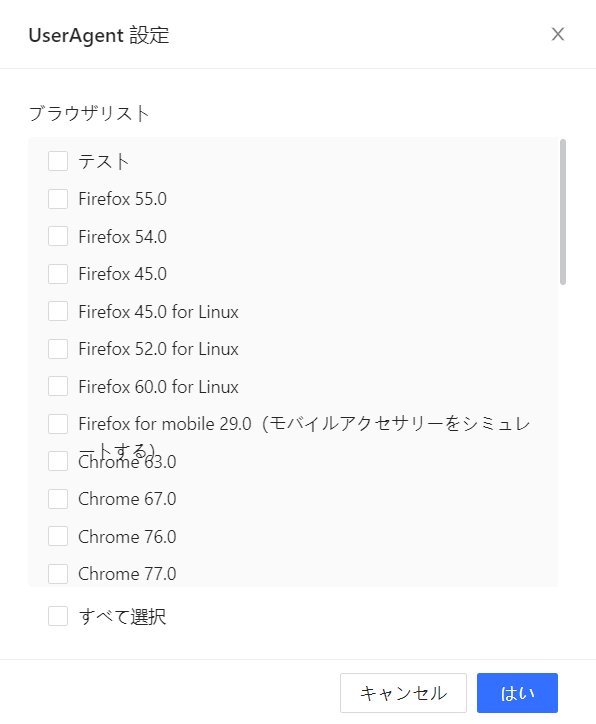
4. User-Agentを適切に設定する
User-Agentは、アクセス元のブラウザや端末情報をサイトへ伝える情報です。古すぎるブラウザ、実在しない組み合わせ、頻繁すぎる切り替えは不自然に見えることがあります。必要に応じて、実際のブラウザに近いUAを使用し、対象サイトの表示に合った環境を選びましょう。
5. Cookieとセッションを正しく扱う
ログインが必要なサイトや、地域・言語・検索条件をCookieで管理するサイトでは、Cookieやセッションを無視するとページが正しく表示されないことがあります。許可された範囲で、セッション情報を保持しながら実行することで、毎回初回アクセスとして扱われる不自然さを減らせます。
6. Ajax・JavaScriptの読み込みを待つ
最近のWebサイトでは、ページを開いた直後にはデータが表示されず、AjaxやJavaScriptで後から読み込まれることがよくあります。この場合、抽出ステップが早すぎると空白データになります。ページ読み込み後の待機、Ajaxタイムアウト、スクロール、特定要素が表示されるまで待機する設定を使いましょう。
7. プロキシやIPローテーションを適切に使う
同じIPから連続して大量アクセスすると、IP単位で制限されることがあります。プロキシやIPローテーションは有効な場合がありますが、負荷の高いアクセスを隠すためのものではありません。待機時間や取得範囲の調整とセットで使い、対象サイトのルールを確認したうえで利用しましょう。
8. 403・429が出たらすぐ再試行しない
403はアクセス拒否、429はリクエスト過多を示すことが多いエラーです。これらが出た直後に何度も再試行すると、さらに強い制限につながる場合があります。処理を一時停止し、待機時間、対象URL、実行頻度、プロキシ設定、UA、Cookieを見直しましょう。
9. 表示されている要素だけを対象にする
非表示リンクや不要なボタンまでクリック対象にすると、通常ユーザーではたどらないURLへアクセスし、Bot判定のきっかけになることがあります。抽出対象やクリック対象は、実際に画面上で確認できる要素に絞り、XPathを慎重に設定しましょう。
関連記事:XPathとは?OctoparseでXPathを利用する方法は?
10. 小規模テストから運用を始める
最初から大量実行するのではなく、数十件から数百件の範囲でテストし、エラー率、空白率、実行時間、対象サイトの応答を確認します。問題がなければ、条件を分けて段階的に増やします。安定運用では「速さ」より「継続性」が重要です。
Octoparseでできるブロック対策設定
Octoparseでは、プログラミングを書かなくても、待機時間、Ajaxタイムアウト、ループ、URLリスト、User-Agent、プロキシなどを設定できます。Pythonコードで細かく実装する前に、まずは以下の順番でタスクを調整してみましょう。
ステップ1:対象サイトのルールと取得範囲を確認する
- 利用規約、robots.txt、APIの有無を確認する
- 取得したいデータ項目を最小限に絞る
- 検索条件やURLを分割し、1回あたりの取得件数を小さくする
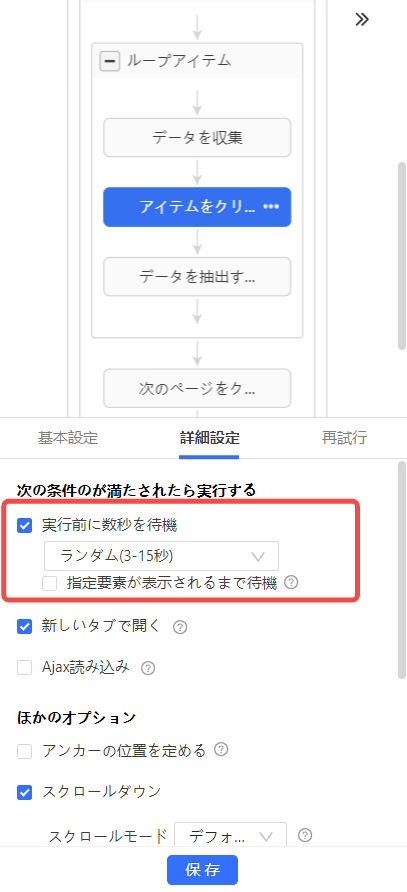
ステップ2:各アクションに待機時間を設定する
- 「Webページを開く」の後に、ページ表示を待つ
- 「次のページをクリック」「もっと見るをクリック」の後に待機時間を入れる
- 「データを収集」の前に数秒の待機を入れ、データが表示されてから抽出する
- 動的サイトでは、特定要素が表示されるまで待機する設定も検討する
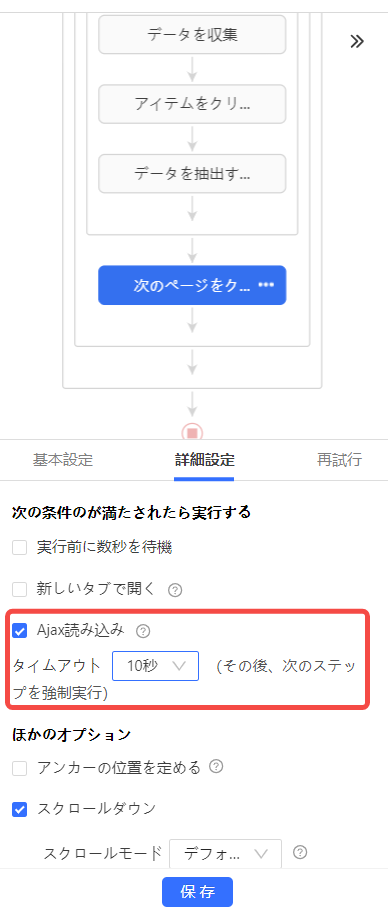
ステップ3:Ajaxタイムアウトを調整する
ページ遷移が発生せず、Ajaxでリストや詳細情報が読み込まれるサイトでは、クリック後の読み込み完了をOctoparseが判断しづらい場合があります。この場合は、対象ステップでAjaxタイムアウトを設定し、短すぎるタイムアウトで空白データにならないように調整します。
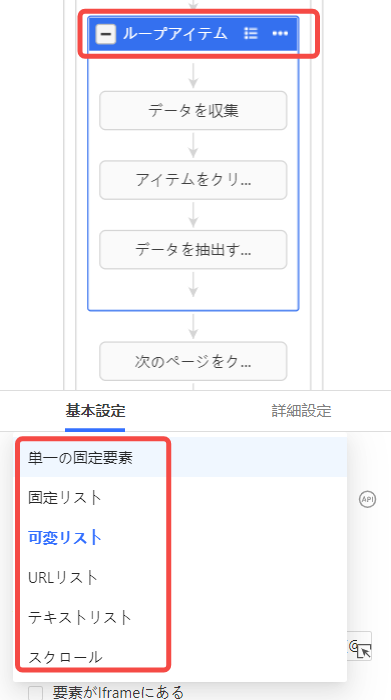
ステップ4:ループ方法を見直す
ページネーション、一覧ページ、詳細ページ、無限スクロールでは、適切なループ設定が異なります。次のページボタンを高速で連打するより、URLリストや条件分割を使った方が安定する場合があります。
ステップ5:User-Agentを確認する
対象サイトがモバイル表示・PC表示で内容を切り替える場合や、特定ブラウザでしか正しく表示されない場合は、タスク設定からUser-Agentを見直します。実在するブラウザのUAを使い、古すぎる文字列や不自然な組み合わせは避けましょう。
ステップ6:必要に応じてプロキシを設定する
アクセス頻度を下げてもIP制限が発生する場合は、Octoparseのブロッキング対策設定でプレミアムプロキシまたはカスタムプロキシの利用を検討します。プロキシの切り替え間隔は、対象サイトの応答や取得量に合わせて調整しましょう。
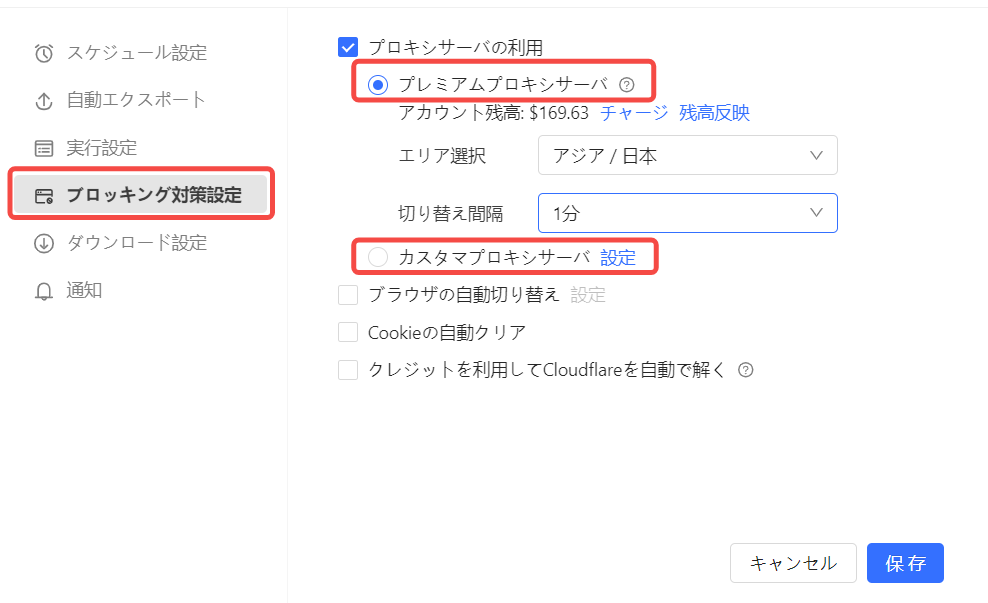
設定方法はこの記事をご覧ください:ブロッキング防止対策
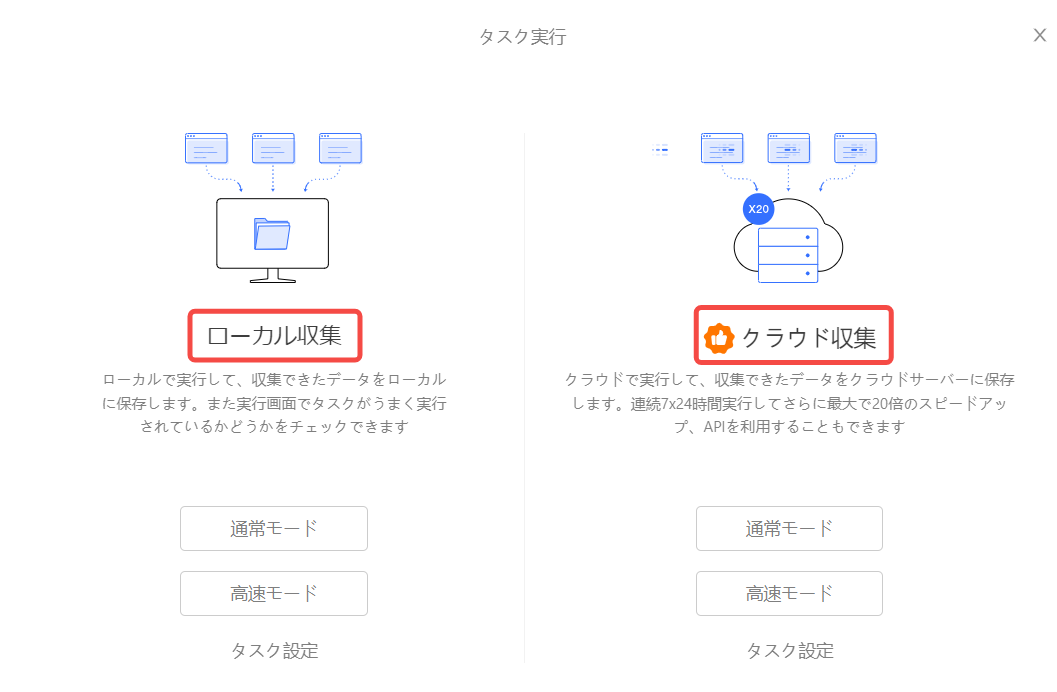
ステップ7:ローカル実行とクラウド実行を使い分ける
ローカルでは取得できるがクラウドでは制限される、またはその逆のケースがあります。対象サイトがクラウドサーバーIPに厳しい場合は、ローカル実行やプロキシ設定を検討します。一方で、長時間の定期収集や大量データ取得では、クラウド実行とスケジュール設定が有効です。
※ハニーポットトラップに注意する
ハニーポットとは、本来はサイバー攻撃者の行動を監視・分析するために設置される「おとり」の仕組みを指します。スクレイピング対策としても応用されており、通常のユーザーには見えないリンクや要素をWebページ内に意図的に配置することで、Botの存在を検出する手法として利用されています。
このようなリンクは、私たち人間は目に見えないためクリックすることはありません。しかし、スクレイピング側はコードとして見つけてしまい隠されたリンクをクリックしてしまうのです。それにより、Webサイト側にBotによるアクセスであると判断され、リクエスト全体がブロックされる可能性があります。
このリスクを避けるためには、HTML構造を事前に確認し、不要なリンクや非表示要素に誤ってアクセスしないような制御が重要です。プログラミングする際には、ブラウザによる目視確認をして実装を行います。
一方Octoparseでは、要素の抽出やクリック操作にXPathを使用することができます。XPathを用いることで、表示状態や属性を条件に指定し、意図しないリンクやトラップ要素を除外することが可能です。これにより、誤ってハニーポットにアクセスするリスクを抑えつつ、正確なデータ抽出を実現できます。
詳しくは、XPathを使用して要素を見つける方法の記事をご覧ください。
403・429・CAPTCHAが出たときの対処法
| 症状 | 考えられる原因 | まず試す対策 |
| 403 Forbidden | アクセス拒否、UA・IP・Cookie・地域制限、利用規約上の制限 | すぐ再実行せず、UA、Cookie、実行環境、対象範囲、規約を確認する |
| 429 Too Many Requests | 短時間のリクエスト過多、同時実行数過多 | 待機時間を長くし、同時実行を減らし、URLを分割する |
| CAPTCHAが表示される | アクセス頻度、IPレピュテーション、行動パターン、ログイン状態の不自然さ | 処理を一時停止し、頻度・件数・プロキシ・実行時間帯を見直す。無理な突破は避ける |
| データが空白になる | Ajax/JavaScriptの読み込み待ち不足、XPath不一致、遅延読み込み | 待機時間、Ajaxタイムアウト、スクロール、XPathを見直す |
| 途中でタスクが停止する | ページ構造変更、次ページボタンの消失、アクセス制限、タイムアウト | ループ終了条件、ページネーション、URL分割、タイムアウトを確認する |
| ローカルは成功、クラウドは失敗 | クラウドIPへの制限、地域差、レンダリング差 | クラウドサーバー切替、プロキシ、ローカル実行、小規模分割を検討する |
やってはいけないブロック回避
ブロック回避という言葉だけを見ると、検知をすり抜けるテクニックに意識が向きがちです。しかし、業務で継続的にWebデータを活用するなら、次のような方法は避けるべきです。
- スクレイピング禁止が明示されているサイトで、制限を回避する目的だけで収集を続ける
- CAPTCHAやログイン制限を無理に突破しようとする
- 個人情報や機密情報を許可なく取得・保存・第三者提供する
- 対象サイトに大きな負荷をかける頻度で実行する
- エラー発生後に待機せず、短時間で何度も再試行する
- 古いUser-Agentや大量のプロキシ切替だけで問題を解決しようとする
安全なスクレイピングでは、対象サイトとの摩擦を減らし、必要最小限のデータを、適切な頻度で、ルールに沿って取得することが重要です。
よくある質問
Q1. スクレイピングのブロック回避は違法ですか?
スクレイピング自体が常に違法というわけではありません。ただし、利用規約に反する取得、個人情報や著作物の無断利用、アクセス制限を無理に突破する行為はリスクがあります。まずは対象サイトの規約、robots.txt、APIの有無を確認しましょう。
Q2. 403エラーが出た場合、プロキシを使えば解決しますか?
プロキシで改善するケースもありますが、万能ではありません。403の原因は、IPだけでなく、User-Agent、Cookie、地域制限、ログイン状態、サイト側の禁止設定など複数あります。まずは原因を切り分けることが重要です。
Q3. 429 Too Many Requests が出たらどうすればよいですか?
アクセス頻度が高すぎる可能性があります。すぐに再実行せず、待機時間を長くし、同時実行数を減らし、URLを分割してください。対象サイトの応答速度が遅い場合は、実行時間帯をずらすことも有効です。
Q4. CAPTCHAが表示された場合も取得を続けてよいですか?
CAPTCHAは、サイト側が自動アクセスを疑っているサインです。まず処理を一時停止し、頻度、件数、プロキシ、UA、取得範囲を見直しましょう。無理な突破を前提にした運用は避けるべきです。
Q5. SeleniumやPlaywrightを使えばブロックされませんか?
ブラウザ操作に近い挙動を再現できるため有効な場合はありますが、必ずブロックされないわけではありません。近年はブラウザフィンガープリントや行動分析も使われるため、速度・頻度・Cookie・実行環境・規約確認まで含めて対策する必要があります。
Q6. Octoparseではどの設定から見直すべきですか?
まずは待機時間と取得範囲の分割を見直してください。次にAjaxタイムアウト、ループ設定、User-Agent、プロキシ、クラウド/ローカル実行環境を確認します。小規模テストで安定性を確認してから本番実行するのがおすすめです。
まとめ
スクレイピングのブロック回避で重要なのは、検知を無理にすり抜けることではなく、対象サイトへの負荷を抑え、ルールを確認し、安定して取得できる設計にすることです。
403、429、CAPTCHA、空白データなどが発生した場合は、まず待機時間、同時実行数、取得範囲、Ajax、User-Agent、Cookie、プロキシ、実行環境を順番に確認しましょう。
Octoparseでは、これらの多くをノーコードで設定できるため、プログラミングに慣れていない方でも、より安全で安定したWebデータ収集を始められます。Webデータを継続的に活用したい場合は、まず小規模なテストから始め、安定性を確認しながら収集範囲を広げていくことをおすすめします。
また、以上で紹介した通り、Octoparseにはプロキシ設定をはじめ、アクセス間隔や実行環境の調整など、安定したデータ取得を支援する機能が用意されています。プロキシの詳細な設定手順や活用方法については、以下の記事もあわせてご参照ください。
プロキシの詳細な設定手順や活用方法については、以下の記事もあわせてご参照ください。
参考:Octoparseヘルプ|どのような場合に追加のプロキシサーバーを使用する必要がありますか?

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール



