「データマイニングと機械学習って、結局何が違うの?」「ビッグデータとの関係はどうなっているの?」——この疑問を持つ方は非常に多いです。
実際、データマイニングと機械学習はよく似た文脈で使われるため、混同されがちです。しかし両者は目的が異なります。データマイニングは「データの中から未知のパターンを発見する」ための手法であり、機械学習は「発見したパターンをもとに予測や自動処理を行う」ための技術です。
本記事では、ビッグデータ・データマイニング・機械学習の3つの概念を図解で整理し、それぞれの関係性、代表的な手法、2026年のAI最新動向、そして実務での活用方法までを体系的に解説します。
ビッグデータ・データマイニング・機械学習の関係を図解で整理
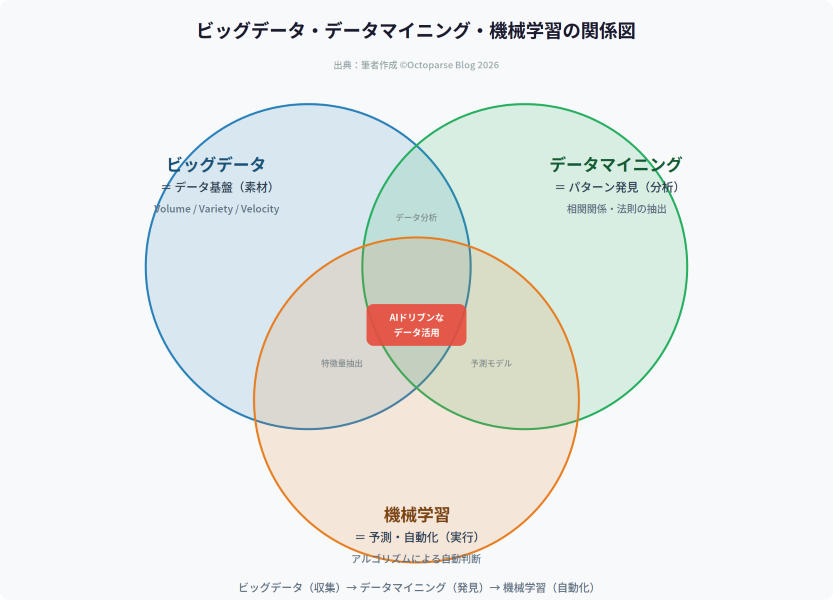
まず最も重要なのは、3つの概念の「役割の違い」を理解することです。
ビッグデータは「素材」です。 膨大な量・多様な形式・高速で生成されるデータ群そのものを指します。
データマイニングは「発見」です。 ビッグデータの中から、人間がまだ気づいていないパターンや相関関係を掘り当てる手法を意味します。
機械学習は「自動化」です。 データマイニングで発見されたパターンを学習し、それに基づいて予測や判断を自動で実行する技術です。
つまり、ビッグデータ → データマイニング → 機械学習という流れで、データが「素材」から「価値」に変換されていきます。
| 項目 | ビッグデータ | データマイニング | 機械学習 |
|---|---|---|---|
| 役割 | データ基盤(素材) | パターン発見(分析) | 予測・自動化(実行) |
| 目的 | データを蓄積・管理する | 未知の法則や相関を見つける | 発見した法則で予測・判断する |
| 人間の関与 | 収集・整備 | 分析結果の解釈・意思決定 | モデル設計後は自動実行 |
| 代表技術 | Hadoop、クラウドDWH | クラスター分析、アソシエーション分析 | ディープラーニング、ランダムフォレスト |
| 身近な例 | コンビニのPOSデータ | 「おむつとビール」の相関発見 | Netflixのレコメンド機能 |
ビッグデータの基礎知識をさらに詳しく知りたい方は、ビッグデータの定義と活用メリットの記事もあわせてご覧ください。
ビッグデータとは?2026年の「5つのV」で理解する
ビッグデータとは、従来のツールでは管理・分析が困難なほど量が大きく、種類が多様で、生成速度が速いデータ群のことです。かつては「3つのV」(Volume、Variety、Velocity)で特徴づけられていましたが、2026年現在はVeracity(正確性)とValue(価値)を加えた「5つのV」が標準的な定義です。
ビッグデータを構成するデータは、構造化データ(Excelの表やデータベース)、非構造化データ(画像・動画・SNS投稿)、半構造化データ(JSON・XML・ログファイル)の3種類に分類できます。
また、総務省の分類では、データの主体によってオープンデータ(政府公開データ)、産業データ(企業のノウハウやM2Mデータ)、パーソナルデータ(個人の購買・位置・健康データ)の3つに分けられています。
ビッグデータの身近な活用事例については、ビッグデータ活用事例15選で業界別に詳しく紹介しています。
データマイニングとは?目的・手法・活用事例
データマイニングとは、膨大なデータの中からデータ間の相関関係やパターンを発見する手法のことです。名前の由来は、鉱山(mine)から貴重な鉱石を掘り出す作業に例えたものです。
機械学習との最も重要な違いは、データマイニングの最終出力が「発見」であるのに対し、機械学習の最終出力が「予測・自動処理」である点です。データマイニングで見つかったパターンを「どう活かすか」の意思決定は、あくまで人間が行います。
データマイニングの代表的な手法
アソシエーション分析 — 「Aを買った人はBも買う傾向がある」という購買パターンを発見する手法。有名な「おむつとビール」の事例がこの分析から生まれました。ECサイトのレコメンドや小売店の棚割り最適化に活用されています。
クラスター分析 — 類似した特徴を持つデータをグループ化する手法。顧客セグメンテーション(高級志向/コスパ重視/機能重視など)に活用されることが多く、マーケティング施策の基盤となります。
決定木分析 — データをツリー構造に分岐させて、特定の結果に至るパターンを可視化する手法。「どの属性の顧客が解約しやすいか」といった分析に使われます。
回帰分析 — 原因と結果の関係性を数値化する手法。「広告費を増やすと売上はどれだけ伸びるか」といった予測に直結します。
ビッグデータの分析ツールについてはビッグデータ分析ツール28選も参考になります。
データマイニングの活用事例
小売業: POSデータの分析で、時間帯・曜日・天候と購買パターンの相関を発見し、品揃えやプロモーションを最適化。
金融業: クレジットカードの取引データから不正利用パターンを検出し、リアルタイムで警告を発するシステムに活用。
医療: 電子カルテの膨大なデータから、特定の症状と疾患の相関を発見し、早期診断の精度向上に貢献。
機械学習とは?3つの学習タイプと代表アルゴリズム
機械学習とは、データから法則やパターンを学習し、それに基づいて予測や判断を自動的に実行する技術です。データマイニングが「人間の意思決定を支援する」のに対し、機械学習は意思決定そのものを機械が行う点が根本的な違いです。
機械学習の基本用語をより詳しく知りたい方は機械学習の8つの基本キーワードの解説記事も参照してください。
3つの学習タイプ
| 学習タイプ | 概要 | 代表アルゴリズム | 身近な活用例 |
|---|---|---|---|
| 教師あり学習 | 正解ラベル付きデータで学習 | 線形回帰、ランダムフォレスト、SVM | 迷惑メール判定、株価予測 |
| 教師なし学習 | 正解なしでデータの構造を発見 | k-means、主成分分析 | 顧客セグメント、異常検知 |
| 強化学習 | 試行錯誤で最適な行動を学習 | Q学習、Deep Q-Network | ゲームAI、自動運転 |
ディープラーニング(深層学習)との関係
ディープラーニングは、機械学習の一手法です。多層のニューラルネットワークを使い、画像認識・自然言語処理・音声認識などで圧倒的な精度を実現しています。2026年現在、ChatGPTやGeminiなどの生成AIもディープラーニングが基盤技術です。

データマイニングと機械学習の違いを徹底比較
データマイニングと機械学習は重なる部分が多いものの、目的と最終出力が異なります。

重要なのは、両者は対立概念ではなく補完関係にあるという点です。実務では、データマイニングで発見したパターンを機械学習モデルに組み込み、予測精度を高めるというワークフローが一般的です。
ビッグデータ×データマイニング×機械学習で得られる3つの価値
価値1:あらゆることが数値で可視化される
クレジットカードの取引履歴は購買データとして記録され、ウェアラブルデバイスは心拍数や歩数をデジタル化し、スマートフォンのGPSは行動パターンを追跡しています。ビッグデータをデータマイニングで分析すれば、今まで見えていなかった傾向や相関が数値として可視化されます。
価値2:行動パターンから未来を予測できる
消費者の行動には一定のパターンがあります。平日の通勤経路、休日の買い物パターン、季節ごとの需要変動——こうしたパターンをデータマイニングで発見し、機械学習に学習させることで、未来の行動を予測できるようになります。
小売業における需要予測や、価格調査の自動化は、その代表的な実務応用です。
価値3:サービスやプロモーションの最適化
予測モデルを活用すれば、プロモーションを展開すべきタイミングや、ターゲットとすべき顧客セグメントをデータに基づいて判断できます。たとえば、3月に旅行ニーズが高まることがデータマイニングで判明すれば、2月末にホテルの早期予約キャンペーンを実施する、といった施策が可能です。
2026年注目:生成AI時代のデータマイニングと機械学習
生成AIがデータマイニングの「民主化」を加速
2026年、ChatGPTやGeminiなどの生成AIに「この売上データを分析して、顧客の購買パターンを見つけて」と自然言語で指示するだけで、専門知識がなくてもデータマイニングの恩恵を受けられる環境が整いつつあります。
これまでデータサイエンティストの領域だったデータマイニングが、生成AIを介して誰でも活用できるようになったことは、2026年の最も大きな変化の一つです。
AIとWebスクレイピングの融合についても、最新動向をまとめています。
AIエージェントによる「収集→マイニング→学習→実行」の自律化
さらに進んだ動きとして、AIエージェントがデータの収集→マイニング→機械学習モデルへのフィードバックまでを自律的に実行する仕組みが登場しています。OctoparseのMCP AI機能は、このAIエージェント連携を実現しており、「競合ECサイトの価格データを毎日収集し、値下げパターンをマイニングして、最適な価格調整を提案する」といった一連のプロセスを自動化できます。
ビッグデータ収集を始める具体的な方法
データマイニングも機械学習も、元となるビッグデータがなければ始まりません。しかし「データをどうやって集めればいいか分からない」という方も多いでしょう。
Web上の公開データを自動収集する
ビッグデータの第一歩として最も取り組みやすいのが、Web上に公開されているデータの自動収集です。ECサイトの価格情報、口コミサイトのレビュー、求人情報、政府のオープンデータなど、データマイニングや機械学習の素材となるデータは、インターネット上に膨大に存在しています。
Octoparseでノーコードのデータ収集
Octoparseは、プログラミング不要でWebデータを自動収集できるクラウド型ツールです。URLを入力するだけでAIがページ構造を自動解析し、取得すべきデータを検出します。
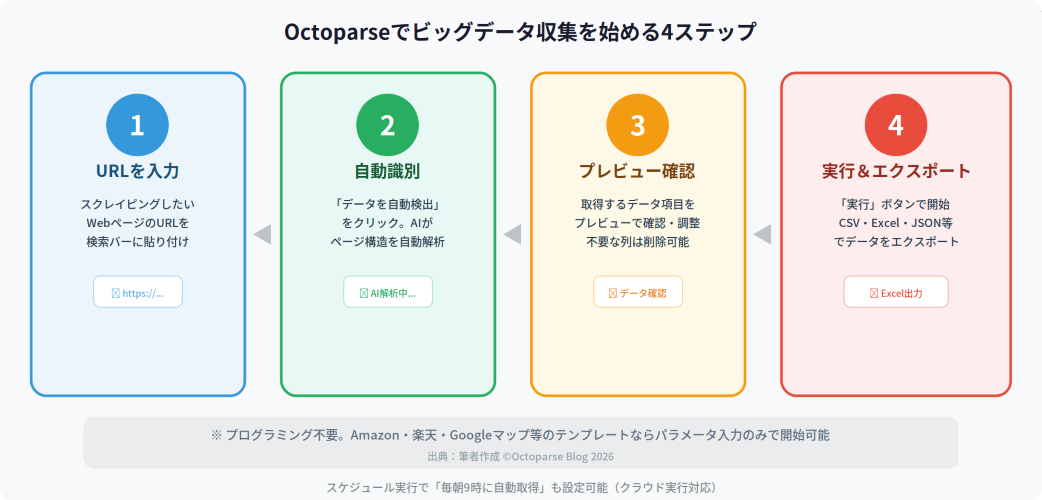
ステップ1: OctoparseにスクレイピングしたいページのURLを入力。
ステップ2: 「Webページのデータを自動検出」をクリック。AIがデータ構造を自動解析。
ステップ3: データプレビューで取得項目を確認・調整。
ステップ4: 「実行」でデータ取得を開始。CSV・Excel・JSONなどでエクスポート。
Amazon、楽天、Googleマップなど主要サイト向けのスクレイピングテンプレートも用意されており、パラメータを入力するだけで即座にデータ収集を開始できます。
ノーコードでのデータ収集方法についてさらに詳しく知りたい方は、解説記事もご参照ください。
収集したデータは、ExcelやCSVにエクスポートした後、Pythonの機械学習ライブラリ(scikit-learn、TensorFlowなど)やBIツールに読み込んで、データマイニングや機械学習に活用できます。Webスクレイピングの基本手順も参考になります。
よくある質問(FAQ)
Q1. データマイニングと機械学習の最も大きな違いは何ですか?
最も大きな違いは「最終出力」です。データマイニングの出力は「人間が解釈するための知見・パターン」であり、最終的な意思決定は人間が行います。一方、機械学習の出力は「予測モデル」であり、モデル構築後は機械が自動で判断・実行します。
Q2. データマイニングに機械学習は必須ですか?
必須ではありませんが、実務では多くの場合に機械学習のアルゴリズムがデータマイニングに活用されています。クラスター分析や決定木分析は機械学習の手法でもあり、両者の境界は重なっています。
Q3. ビッグデータがないとデータマイニングはできませんか?
小規模なデータセットでもデータマイニングは実施可能です。ただし、一般的にデータ量が多いほど有益なパターンを発見できる可能性が高まります。Web上の公開データをOctoparseなどのツールで自動収集すれば、ビッグデータの構築は個人や中小企業でも始められます。
Q4. 非エンジニアでもデータマイニングや機械学習は始められますか?
はい。2026年現在は、生成AI(ChatGPT、Geminiなど)に自然言語で分析を依頼するだけでも基本的なデータマイニングが可能です。データの収集段階では、Octoparseのようなノーコードツールを使えばプログラミングは不要です。
Q5. データマイニングの結果を機械学習に活かすにはどうすればいいですか?
データマイニングで発見したパターン(例:「この属性の顧客は解約しやすい」)を、機械学習モデルの特徴量として組み込みます。これにより、予測モデルの精度が向上し、より的確な自動判断が実現できます。
まとめ:3つの概念を「知る」から「使う」へ
正直に言うと、ビッグデータ・データマイニング・機械学習の違いを調べ始めたとき、筆者自身も「結局全部同じようなものじゃないの?」と思っていました。教科書的な定義を読んでもピンとこなかったのです。
腹落ちしたのは、実際に自分でデータを触り始めてからでした。
最初にやったのは、ECサイト3社の商品レビュー500件をOctoparseで自動収集すること。これがビッグデータ(の小さな版)です。次に、そのレビューの中から「星1のレビューに共通するキーワード」を探しました。これがデータマイニング。すると「配送遅延」「サイズ違い」という2大不満パターンが浮かび上がりました。
最後に、このパターンをもとに「新しいレビューが投稿されたとき、不満レビューかどうかを自動判定する」仕組みを作ってみました。これが機械学習です。
教科書の定義だけでは見えなかった3つの概念の「つながり」が、たった500件のレビューデータで体感できたのです。
つまり、ビッグデータは素材、データマイニングは発見、機械学習は自動化。この3つは独立した概念ではなく、1つのデータ活用プロセスの中の3つのステージです。
まだ実際にデータを触ったことがない方は、まずOctoparseで身近なWebサイトのデータを100件でも集めてみてください。データの「手触り」を感じた瞬間に、ビッグデータもデータマイニングも機械学習も、一気に自分ごとになるはずです。
データ収集の第一歩を踏み出すなら → Octoparse 無料ダウンロード

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力。
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出。
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始。
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握。
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫。
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール。