Booking.comからホテル名、料金、住所、星評価、口コミスコア、設備、画像URLなどを効率よく収集するなら、ノーコードのOctoparseを使う方法が手軽です。プログラミング不要で宿泊施設リストを作成でき、競合調査や価格比較、旅行市場の分析にかかる手作業を大幅に削減できます。
本記事では、Booking.comスクレイピングで取得できるデータをはじめ、Python・公式API・Octoparse・AIツールによる収集方法を比較します。各方法の費用、技術的な難易度、データの柔軟性、サイト変更への対応力も整理しているため、自社の目的に合った方法を判断できます。
さらに、スクレイピング時の注意点やよくある疑問も解説します。Booking.comのデータを活用して、ホテルリスト作成や市場調査、競合分析を効率化したい方は、ぜひ参考にしてください。
| データ項目 | 取得例 |
|---|---|
| ホテル名 | ホテルニューオータニ東京 |
| 所在地/住所 | 東京都千代田区紀尾井町4-1 |
| 星評価(スター数) | 5つ星 |
| レビュースコア | 8.7(クチコミ2,341件) |
| 1泊あたりの料金 | ¥28,000~ |
| 部屋タイプ | デラックスツイン 他 |
| 設備・アメニティ | Wi-Fi、駐車場、プール 他 |
| 画像URL | https://cf.bstatic.com/xxxxx.jpg |
| 詳細ページURL | https://www.booking.com/hotel/jp/xxxxx.ja.html |
Bookingスクレイパーとは?
Booking.comスクレイピングとは、Booking.com上に公開されているホテル名・価格・評価・住所などの情報を、専用ツールを使って自動的に収集・整理する作業のことです。
手作業でのコピー&ペーストは時間がかかるうえ、件数が増えるほどミスが発生しやすくなります。そこで使われるのが「Webクローラー」と呼ばれる自動収集プログラムです。仕組みの詳細は、ゼロからWebクローラーを構築する方法で解説しているので、基礎から理解したい方はあわせてご覧ください。
本稿では、プログラミング知識ゼロでもBooking.comから宿泊施設リストを作成できるノーコードツール Octoparse(オクトパース)を軸に、Python・公式API・AIツールとの違いまで、実務で使える形で整理します。
https://www.octoparse.jp/template/booking-com-hotel-listings-scraper
Booking.comからスクレイピング可能なデータ一覧は?
Booking.comの掲載ページ(検索結果ページおよび宿泊施設詳細ページ)から取得できる主なデータは以下の通りです。
・ホテル名/施設名 ・住所/所在地 ・星評価(スターランク) ・レビュースコアと件数 ・1泊あたりの料金 ・部屋タイプ ・設備/アメニティ(Wi-Fi、駐車場、朝食有無など) ・空室状況 ・画像URL ・詳細ページURL
これらはすべて「宿泊施設リスト」としてそのままExcelやCSVに整理できる形で取得可能です。なお、レビュー本文だけをまとめて収集したい場合は、専用のレビューだけを個別に収集できるテンプレートを使うと効率的です。
いずれもBooking.com上で一般公開されている情報のみが対象で、ログイン後にしか見られない個人情報(会員限定価格や予約者情報など)は対象外です。
Booking.comをスクレイピングする方法は?
Booking.comのデータ収集方法は、大きく分けて「プログラミングで自作する」「ノーコードツールを使う」の2種類があります。それぞれの特徴を、実際に試した内容をもとに解説します。
PythonでBooking.comからデータを収集する
Booking.comは検索結果ページをスクロールすると新しいデータが動的に読み込まれる『無限スクロール』型のサイトです。そのため、Requestsのような静的取得ライブラリでは全件を取得できず、Selenium等のブラウザ自動化ツールで実際の画面操作をシミュレートする必要があります。
以下はPythonでBooking.comをスクレイピングする詳しく操作手順でご確認ください。
Step 1:Booking.comのAPI認証情報を取得する
Booking.comのAffiliate Partnerとして、APIキーとAffiliate IDの情報を取得します。またDemand APIの利用には、両方の認証情報が必要です。
Step 2:Pythonの作業環境を作成する
ターミナルまたはコマンドプロンプトで、以下を順番に実行します。
仮想環境を有効にします。Windowsの場合:
macOS・Linuxの場合:
Step 3:APIキーを環境変数に保存する
プロジェクトフォルダ内に.envというファイルを作り、以下を記述します。
APIキーをPythonコードへ直接書かないことで、認証情報の誤公開を防げます
Step 4:ホテルを検索するコードを作成する
booking_search.pyというファイルを作り、以下のコードを貼り付けます。
YOUR_CITY_IDは、検索対象地域のBooking.com City IDへ置き換えます。 最初は本番環境ではなく、公式のSandbox環境を使用します。本番利用時はURLを次のように変更します。
Step 5:コードを実行する
ターミナルで次のコマンドを実行します。
Step 6:検索結果を整理する
Step 4の最後にあるprint(result)を、以下のコードへ置き換えます。
APIの契約内容やレスポンス仕様によって、取得できるフィールドは異なります。最初にJSONを確認してから、必要なキーを指定してください。
Step 7:ExcelとCSVへ保存する
Step 6のコードの末尾に、以下を追加します。
再度コードを実行します。
実行後、プロジェクトフォルダに次のファイルが作成されます。
booking_hotels.csv
booking_hotels.xlsx
Step 8:ホテルの詳細情報を取得する
検索結果から取得したホテルIDを使い、住所、設備、写真、客室情報などを取得します。booking_details.pyを作成し、以下を入力します。
YOUR_HOTEL_IDを、検索APIで取得したホテルIDへ置き換えます。
Step 9:複数ページを取得する
レスポンスにnext_pageが含まれている場合、次のページを取得できます。
この方法は取得ロジックを完全にカスタマイズできる自由度の高さが魅力ですが、Booking.comのサイト構造が変わるたびにコードを修正する保守コストが発生し、Python未経験者には現実的なハードルが高い点に注意が必要です。
ノーコードスクレイピングツールOctoparseでデータを収集しホテルリストを作成する
次は、実際にOctoparseでホテルリストを作成した手順を紹介します。より詳細なスクリーンショット付き手順はヘルプセンターの公式チュートリアルでも確認できます。
下準備として宿泊先と宿泊日を指定したURLを取得します。Booking.comにアクセスしたら宿泊地・チェックイン・チェックアウト・宿泊人数を指定して「検索」をクリックし、表示されたページのURLをコピーします。今回は次のような条件を指定しました。
- 京都市
- 11月11日(金)チェックイン
- 11月13日(日)チェックアウト
- 大人2人

URLをコピーしたらOctoparseを起動します。最初に表示されたページの入力欄にコピーしたURLを貼り付け、「抽出開始」をクリックします。
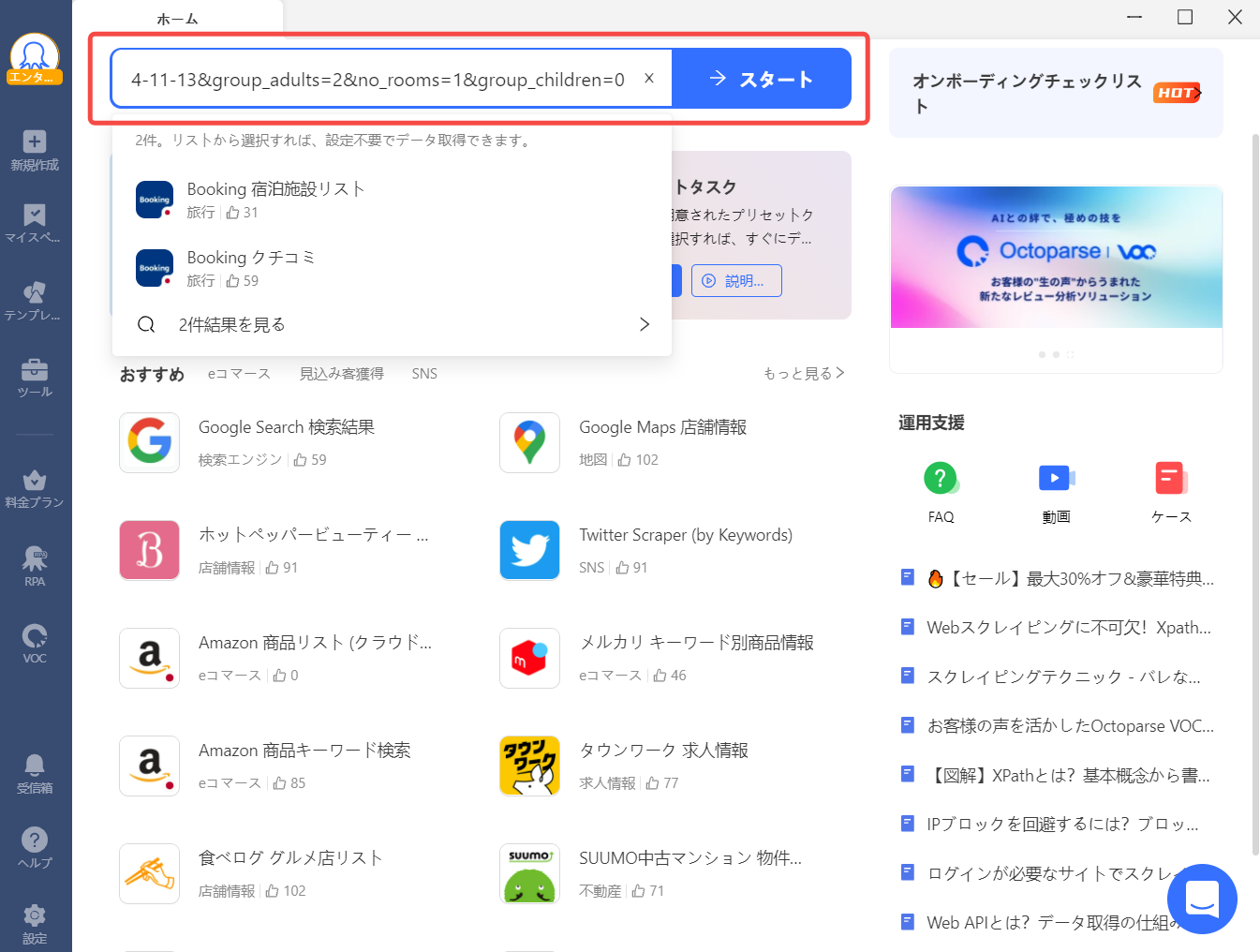
少しするとURLで指定したページが表示されるので、「Webページを自動識別する」をクリックします。
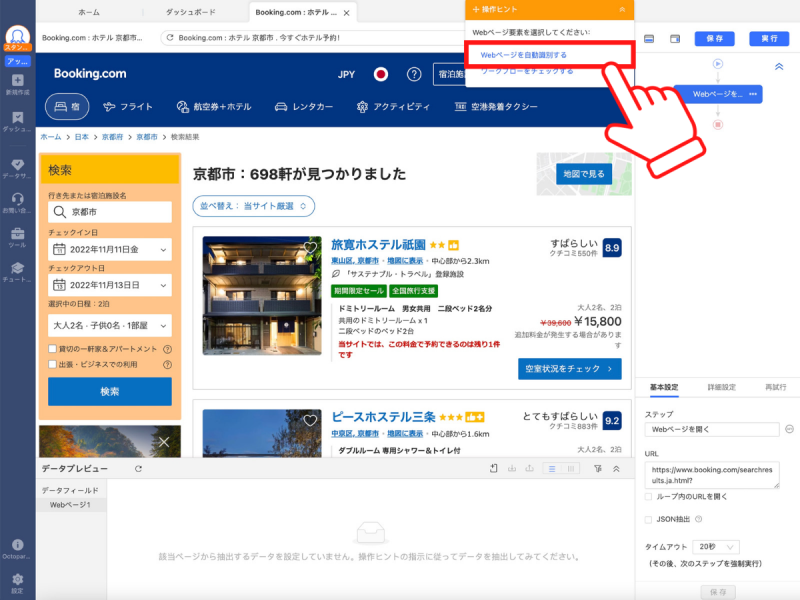
Octoparseがページを自動識別し、ホテルリストを作るプログラムを生成してくれるので、そのまま「ワークフローを生成」をクリックします。
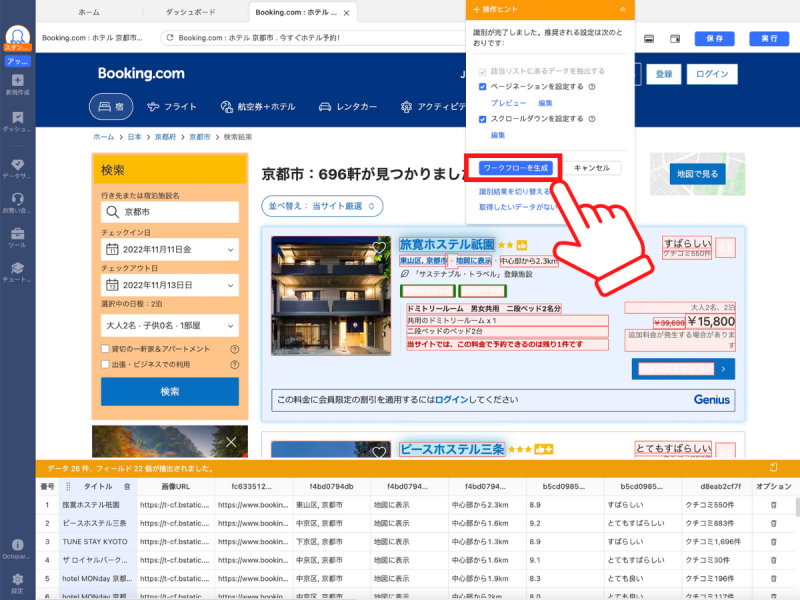
ここで、「ページネーション」の確認を行いましょう。ページネーションとは「次のページに移動するボタンをクリックする」という指示部分です。ページネーション設定が間違っていると正しく情報収集できないので、実行前に確認しておきます。画面右側にワークフローが表示されているので、ページネーションの枠内にある「次のページをクリック」をクリックします。
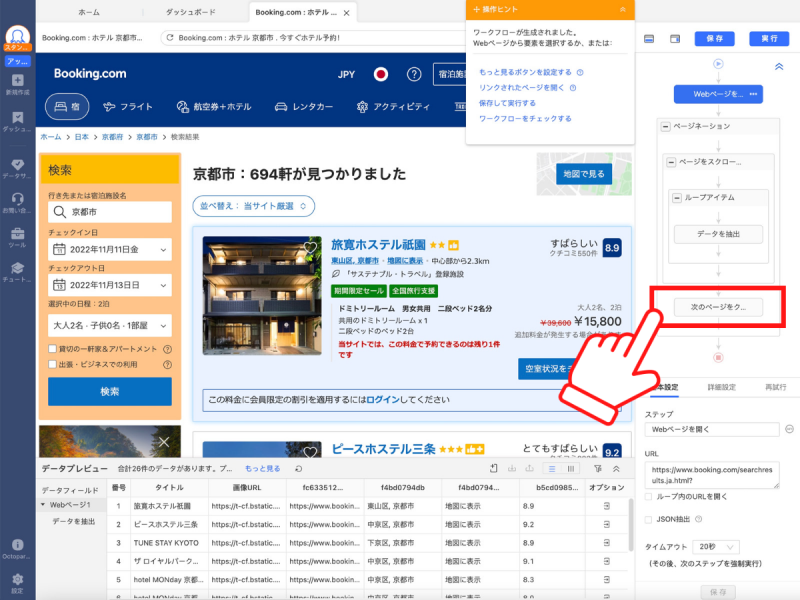
クリックすると次のページが移動するので、画面下部までスクロールしてページが正しく移動しているかを確認します。
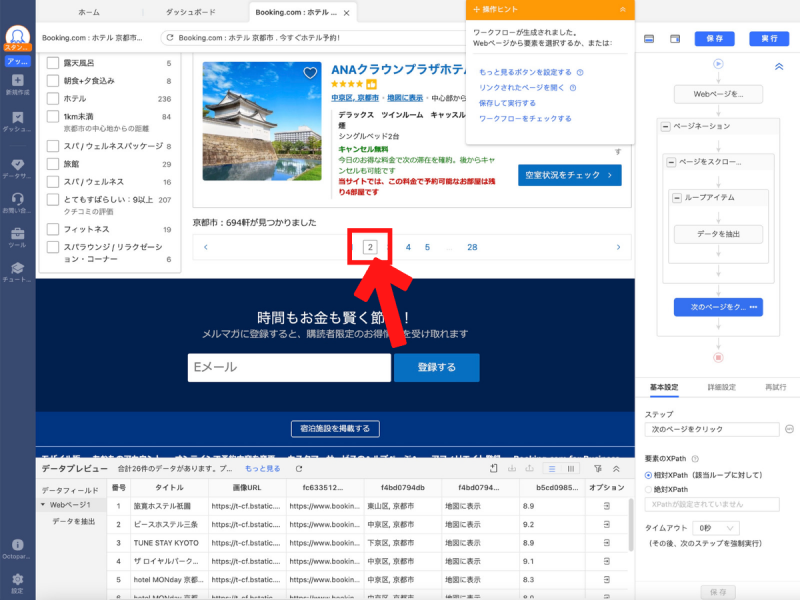
1ページ目から2ページ目に移動しているので、この時点でページネーションに問題はありませんね。続けて「ページネーション」をクリックしてみます。
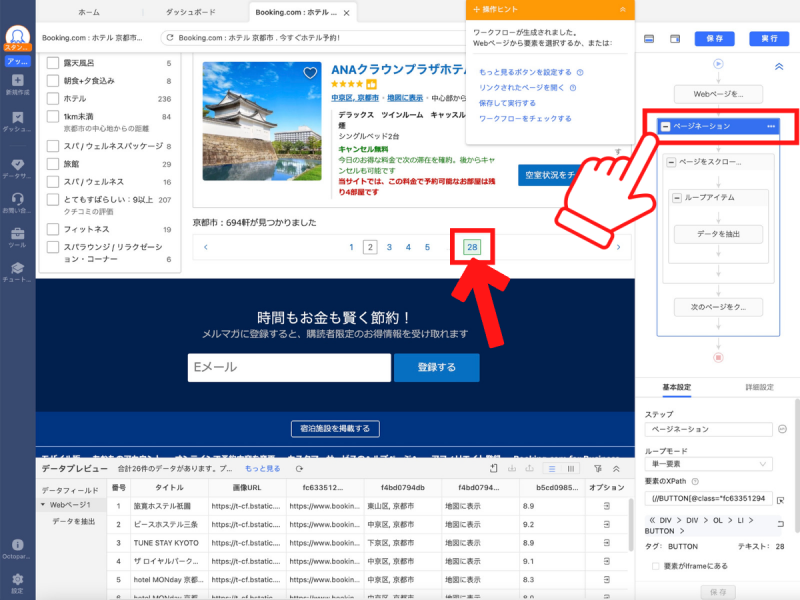
するとどうでしょう。3ページ目ではなく28ページ目が緑色で表示されていますね。これは、「ページネーションとして28ページ目のボタンが設定されています」という意味です。
つまり、このままWebスクレイピングを続けると1ページ目から2ページ目、次に28ページ目に移動することになります。ページネーションを正しく機能させるために、少し調整しましょう。
画面右側のワークフローで「ページネーション」を選択したまま、その画面下部にある「要素のXPath」を指定します。入力欄の右側にあるボタンをクリックしたら、画面上部に「クリックしてページ要素を~」という文言が表示されるのを確認してください。さらに「次のページに移動するボタン」に該当する部分をクリックします。
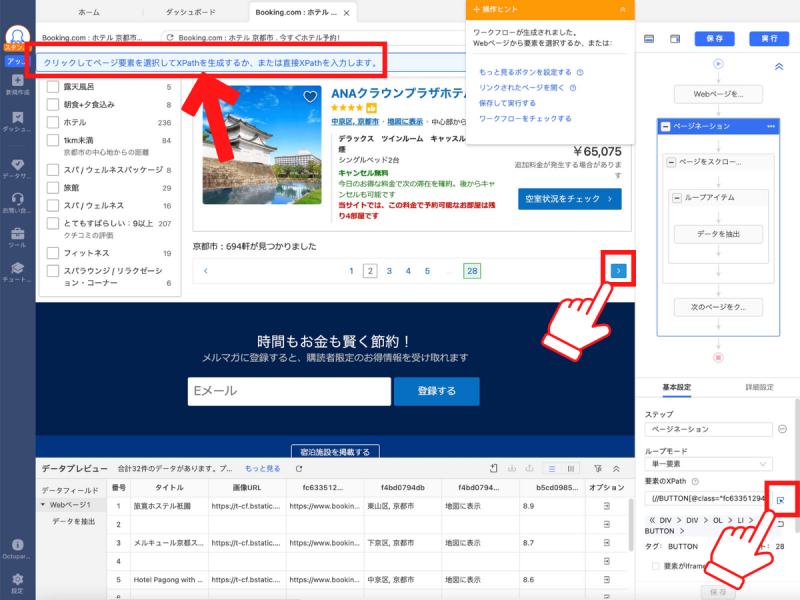
ボタンをクリックする際は、テキスト部分ではなくボタンの枠部分をクリックしましょう。テキスト部分を選択するとボタンとして認識されない可能性があります。
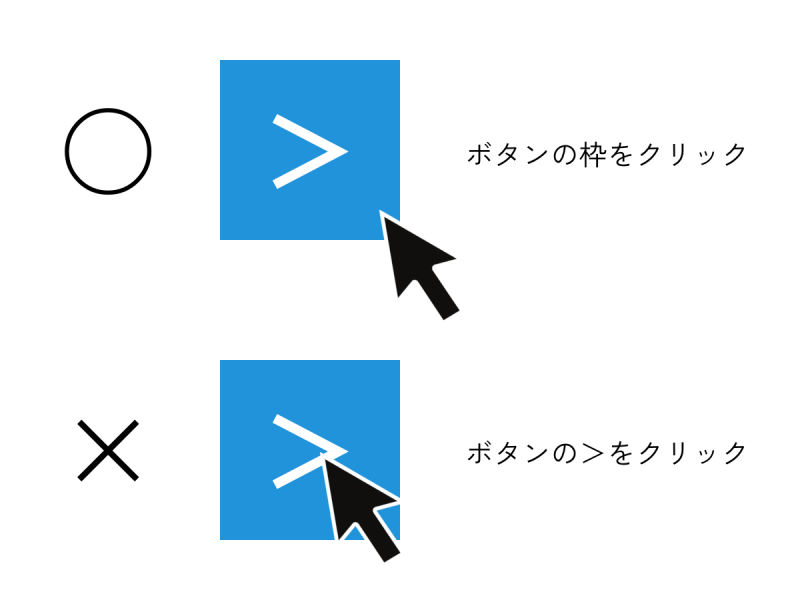
選択したボタン部分が緑色で表示されれば設定はOKです。画面右下の「保存」をクリックし、先ほどと同じ手順でページネーションが正しく機能しているか確認します。
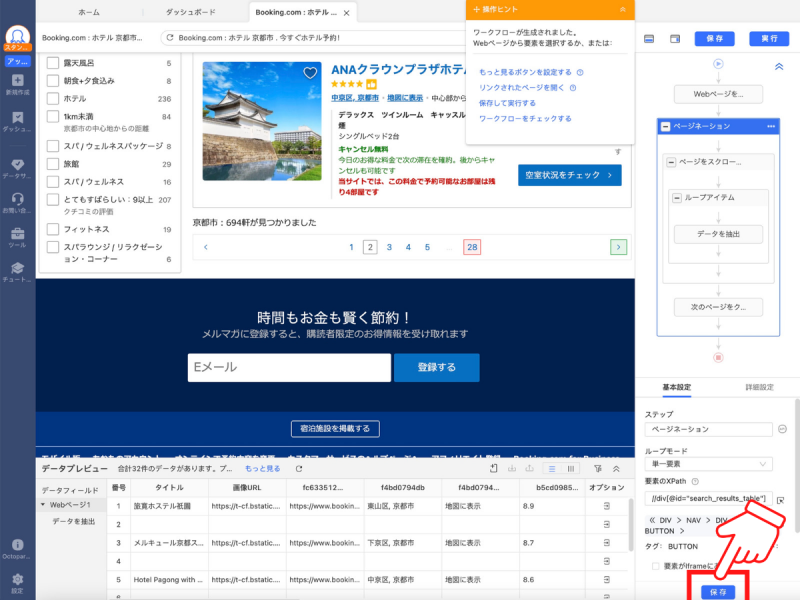
この状態でもWebスクレイピングを実行できますが、ホテルリストの情報項目を少し調整してみます。収集する情報項目のタイトルが適切ではないので、タイトル部分をダブルクリックして修正していきます。
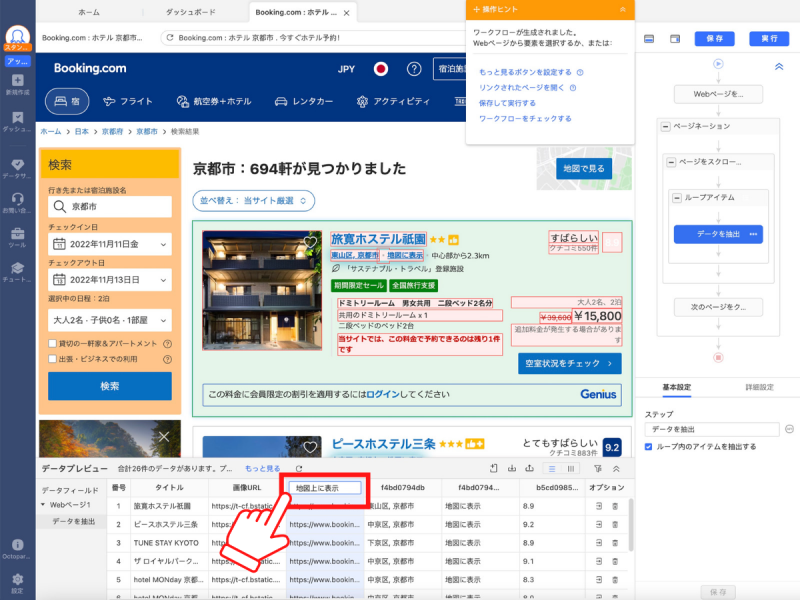
さらに見やすいホテルリストを作るために、データの再フォーマットも行いましょう。再フォーマットしたい情報項目のタイトル横にある「三点リーダー」をクリックします。
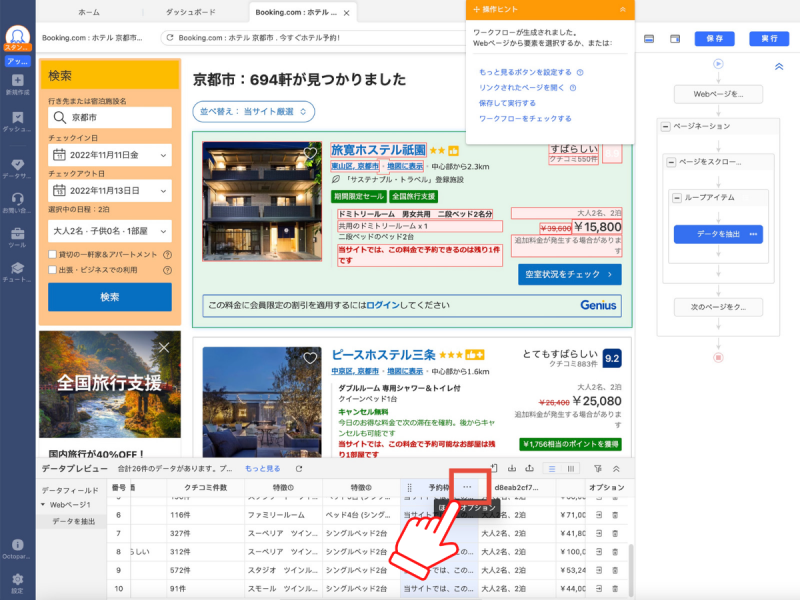
「データを再フォーマット」をクリックします。
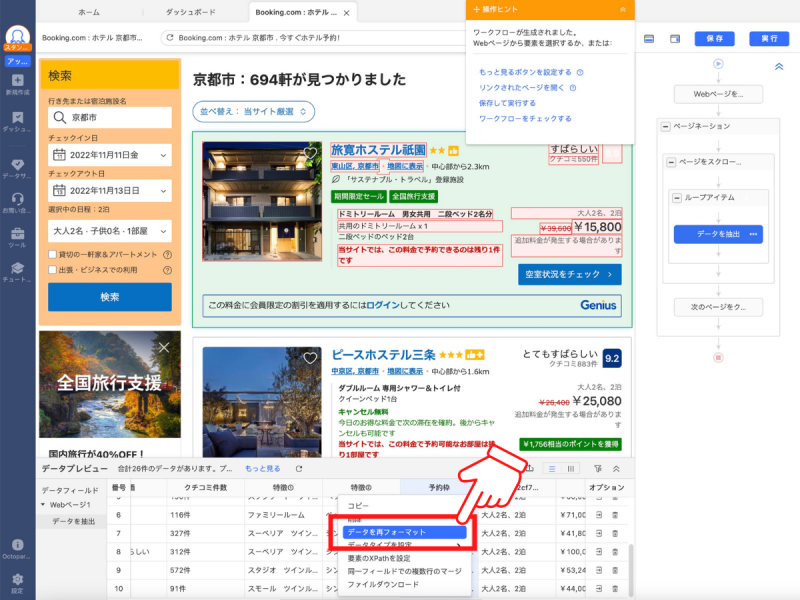
「ステップを追加」をクリックします。
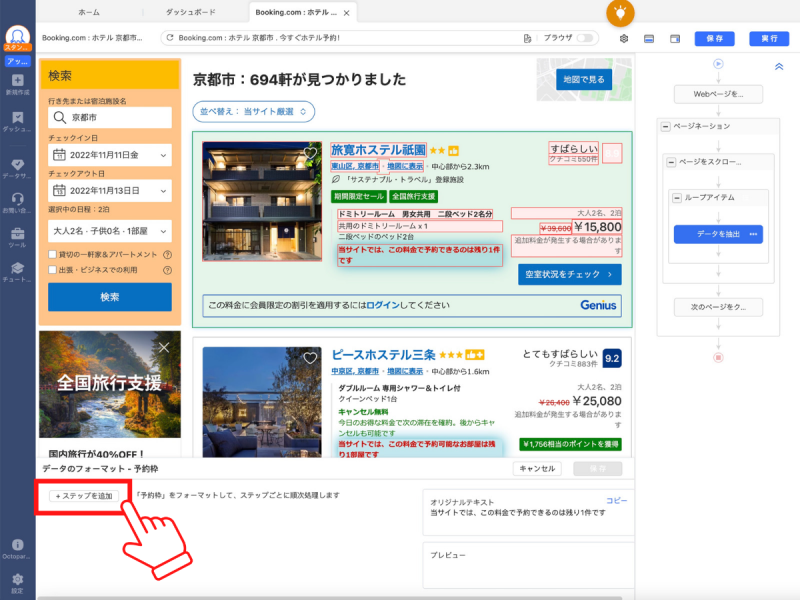
「置換」をクリックします。
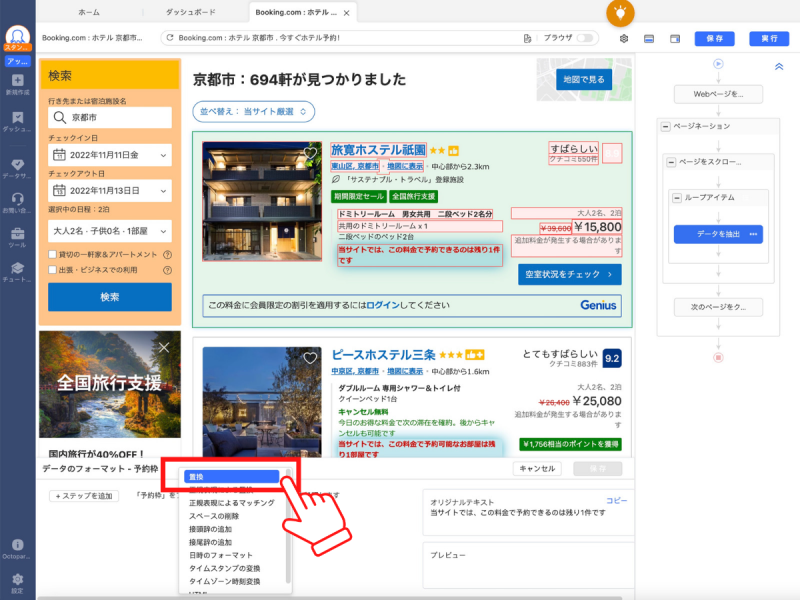
置換フォーマットのページが表示されるので、各種項目を入力します。今回は「当サイトでは、この料金で予約できるのは「残り」というテキストを検索文字列に入力し、置換文字列は空白のまま保存しました。
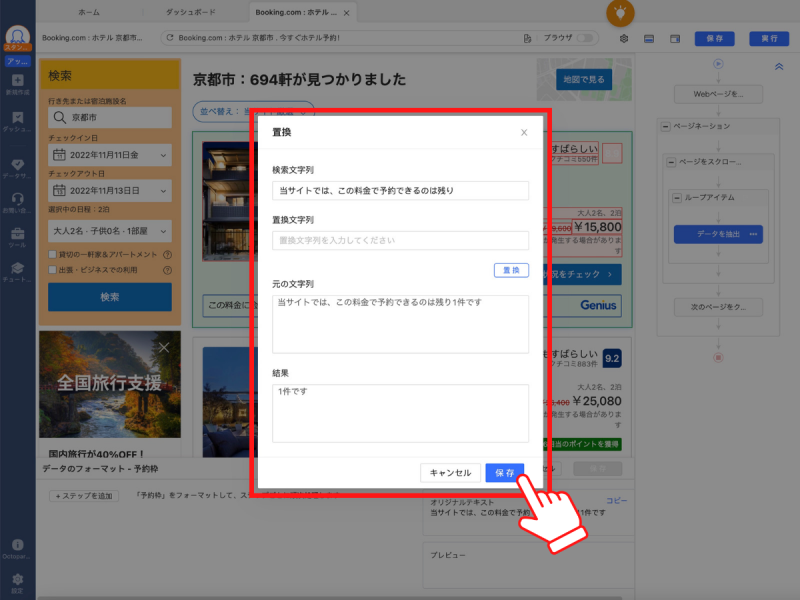
すると「当サイトでは、この料金で予約できるのは残り」のテキストが削除され、予約枠の情報項目では「○件です」とだけ表示されるようになります。「です」も余計なので、同じ手順で削除して「○件」とだけ表示されるように調整しました。最後に「保存」をクリックすれば、再フォーマットは完了です。
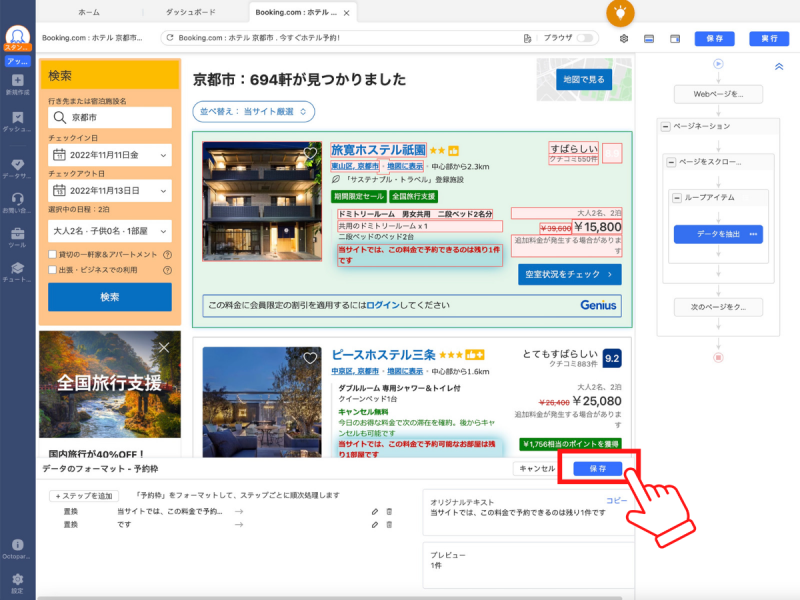
以上でWebスクレイピングの実行環境が整ったので、画面右上の「保存」実行」を順番にクリックします。
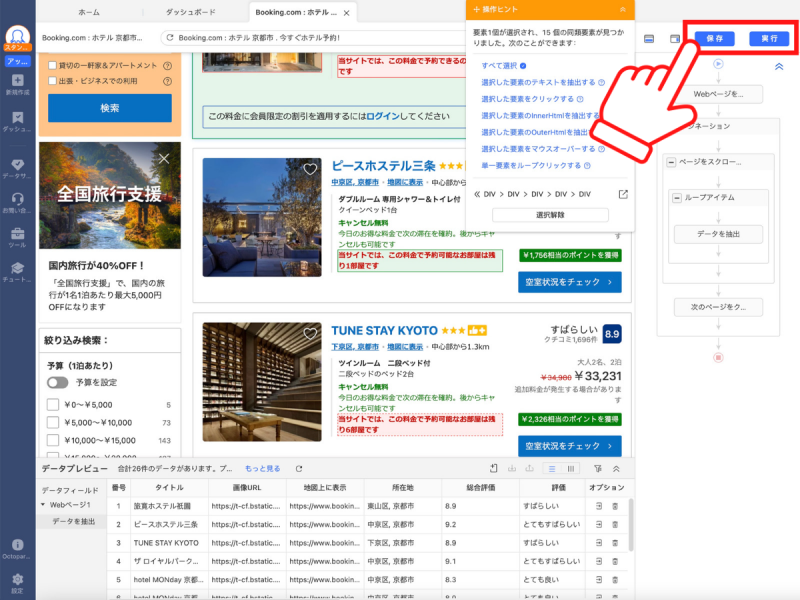
タスクの実行方法を選択する画面が表示されるので、任意の方法を選択します。今回はローカル抽出の「通常モード」を選択しました。抽出したホテルリストをクラウドに保存できるクラウド抽出は、有料プランでご利用いただけます。
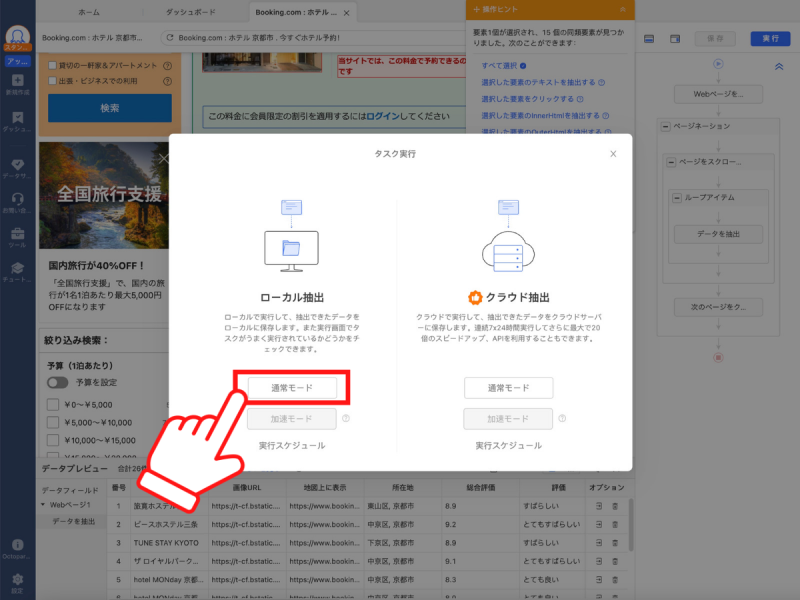
今回は約700件分のホテルリストをわずか3分19秒で作成できました!Webスクレイピングが完了したらデータのエクスポートを選択し、「唯一データ」をクリックします。
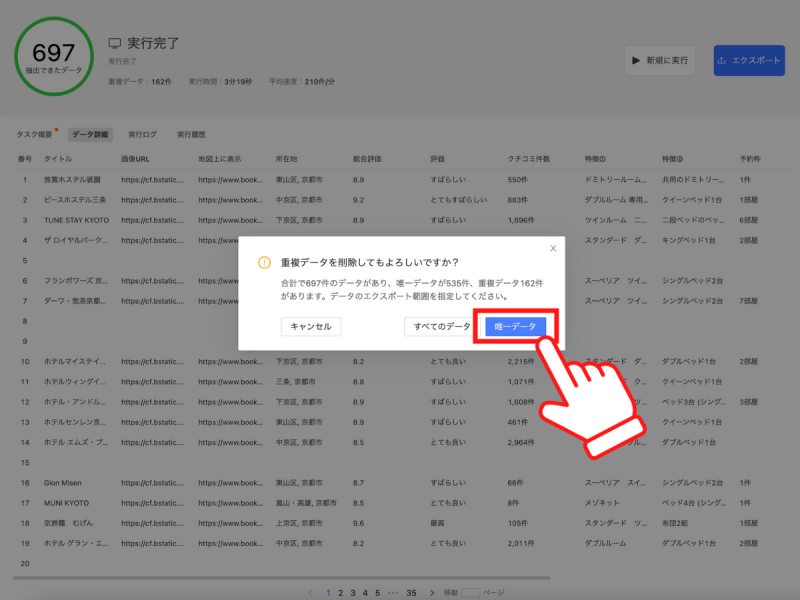
最後にダウンロードしたいファイル形式を選択し、「はい」をクリックするとホテルリストがダウンロードされます。
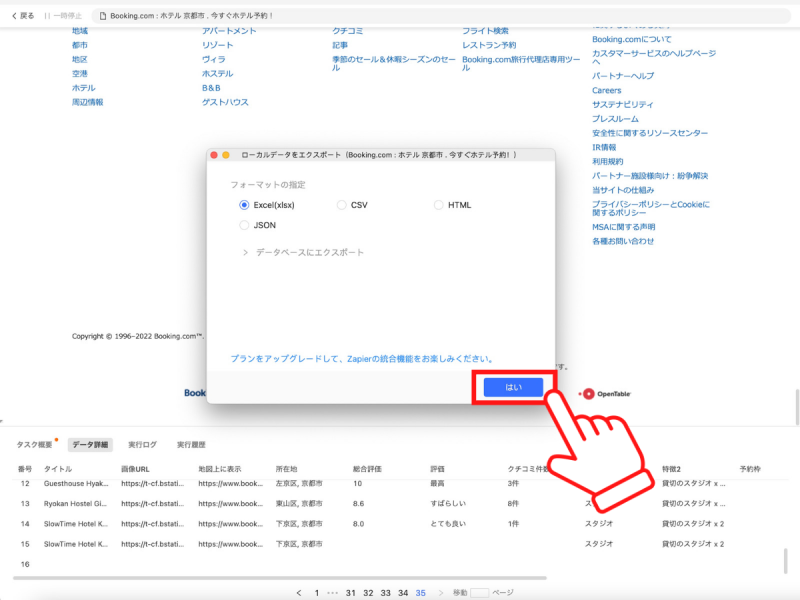
こちらが体裁を整えたホテルリストです。
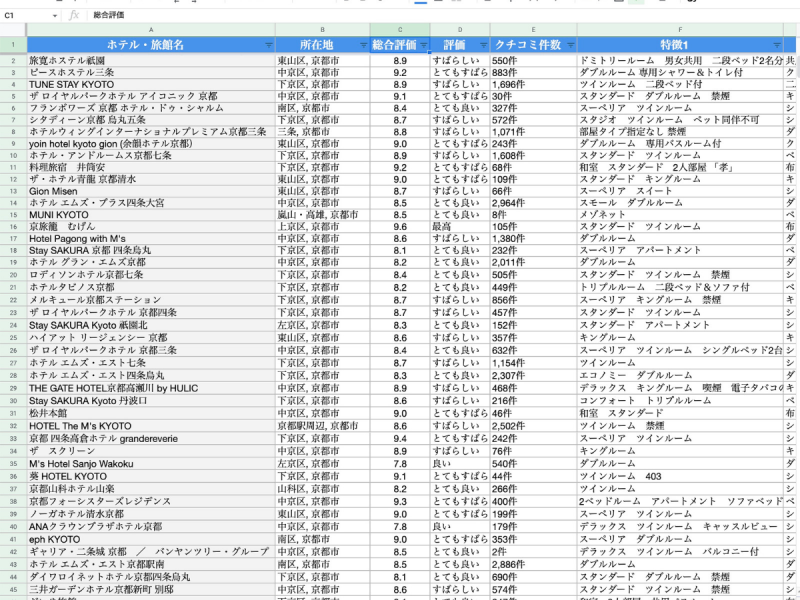
いかがでしょうか?Webスクレイピングを実行するプログラムをゼロから作りましたが、Octoparseがあればごく簡単に作ることができました。しかも、約700件分のホテルリストを3分19秒で作成できたので、手作業にかかる時間を圧倒的に短縮できます。
ダウンロードしたホテルリストはフィルタ機能を使って、評価順や価格の安い順に並べ替えたりして、条件にマッチした宿泊先を探してみましょう。
関連記事
なぜOctoparseでBooking.comをスクレイピングするのをお勧めですか?
Octoparseは、プログラミングの知識がなくても利用できるノーコードのデータ収集ツールです。Booking.comのような宿泊施設情報、料金、口コミ、空室状況などを効率的に収集したい場合でも、画面上の操作だけでデータを抽出し、ExcelやCSV形式で整理できます。また、Octoparseではさまざまな業務シーンに対応したデータ収集テンプレートを提供しており、ホテル価格の比較、競合調査、口コミ分析、旅行市場のリサーチなど、幅広いビジネス用途に活用できます。
ページ構造が複雑なサイトや、標準テンプレートだけでは対応しきれないケースでも、カスタマイズテンプレートサービスを利用することで、自社の目的に合わせたデータ収集が可能です。手作業での情報収集にかかる時間を大幅に削減し、より重要な分析や意思決定に集中できる点が、Octoparseを活用する大きなメリットです。Python自作と比較した場合のOctoparseの優位性は、次の4点に整理できます。
- コード不要:クリックとドラッグだけでワークフローを作成でき、Web操作ができれば誰でも扱える
- 自動識別機能:ページ構造をAIが解析し、データ項目の候補を自動で提案してくれるため、初期設定の手間が最小限で済む
- クラウド実行とIPローテーション:大量ページを収集する際も、ブロックされにくい環境を利用できる
- スケジュール実行:料金変動を継続的にウォッチしたい場合、定期実行を設定するだけで自動的に最新データを収集できる
初期のホテルリスト作成だけでなく、継続的な価格モニタリングまで見据えるなら、保守コストの低さがOctoparseを選ぶ最大の理由になります。

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール
Booking.com APIとは
Booking.com APIとは、Booking.com社が提供する、宿泊施設データや空室・価格情報をシステム間で直接やり取りするための公式インターフェースです。ただし、一般公開された無料APIではなく、旅行代理店やホテル向けOTA連携事業者など、審査を通過した提携パートナー限定で提供される「Booking.com Partner Hub API」が中心です。
個人や中小事業者が『とりあえずデータを試したい』という目的で申請しても、審査のハードルや契約要件(取引実績など)から利用開始までに時間がかかるケースが多く、料金体系もプラン・リクエスト数に応じて変動します。
Booking.com APIを使ったスクレイピングは?
API利用が承認されれば、規約の範囲内で安定的かつ合法的にデータを取得できるという大きなメリットがあります。一方で、取得できるデータ項目や更新頻度がAPI側の仕様に固定されるため、『この項目だけ追加で取りたい』といった柔軟なカスタマイズには不向きです。
そのため実務では、契約済みAPIで基本データを継続取得しつつ、API対象外の項目(競合ホテルの詳細な設備情報や、期間限定のキャンペーン表示など)はOctoparseのようなスクレイピングツールで補完する、という併用パターンもよく採られています。
Booking.comをスクレイピングする方法の比較
ここまで紹介した方法に、近年増えているAI搭載スクレイピング拡張機能、企業向け代行サービスも加え、読者が最も気にする5つの観点で比較します。
| 方式 | 技術ハードル | 費用目安 | データの柔軟性 | サイト変更への対応 | おすすめのユーザー |
|---|---|---|---|---|---|
| Octoparse(ノーコード) | 低(クリック操作のみ) | 無料プランあり/有料は月額7,000円~が目安 | 高(項目の追加や豊富なテンプレートに対応) | 自動識別機能で再設定が容易 | 非エンジニア、マーケター、中小事業者 |
| Python自作(Seleniumなど) | 高(プログラミング必須) | 実質無料(人件費・学習コストは別途必要) | 最も高い(完全なカスタマイズが可能) | サイト変更のたびに手動修正が必要 | エンジニア、独自システムに組み込みたい開発チーム |
| Booking.com API(Partner Hub) | 中(審査・契約が必要) | 契約プランに応じて変動 | 低~中(API仕様に固定) | Booking.com側が保守(自社対応は不要) | OTA連携事業者、正規パートナー契約が可能な事業者 |
| AIスクレイピング拡張機能 | 低(自然言語で指示するだけ) | クレジット従量制が主流 | 中(AIが自動判定するため細部を調整しにくい) | AIが自動再学習するケースが多い | 単発・小規模な調査、非定型ページの収集 |
| エンタープライズ代行サービス | 極めて低(丸投げ可能) | 高額(要問い合わせ) | 中~高(要件次第) | サービス提供者が保守 | 大企業、法務・コンプライアンス体制を外部委託したい組織 |
価格・ハードル・保守性のバランスで見ると、初めてBooking.comのデータ収集に取り組む個人〜中小規模の事業者には、無料から始められコード不要なOctoparseが最も導入しやすい選択肢といえます。
AIスクレイピングとOctoparse MCPの活用
近年はAI スクレイピングと検索されるように、AIに指示を出すだけでデータ収集が完結するツールへの関心が高まっています。Octoparseも自動識別機能でAIによるページ解析を行っていますが、それに加えて、収集したデータを自社のシステムやAIエージェントのワークフローに直接接続したい場合は、Octoparse MCPが選択肢になります。
MCP(Model Context Protocol)とは、AIモデルと外部ツールを安全に接続するための共通規格です。詳しい仕組みはMCPとは何かで解説していますが、簡単に言えば、ChatGPTやClaudeのようなAIアシスタントから直接Octoparseのスクレイピング機能を呼び出し、『Booking.comの東京エリアのホテル価格を集めて』と指示するだけでデータ収集から加工までを自動化できる仕組みです。
継続的な価格モニタリングや、社内の分析基盤に定期的にホテルデータを流し込みたいケースでは、Octoparse MCPの活用を検討する価値があります。導入手順はMCPの導入手順を解説したドキュメントにまとまっています。
Booking.comをスクレイピングする時の注意点は?
Booking.comの利用規約には、営利目的での監視・コピー・スクレイピング・クローリングを無断で行うことを禁じる条項があります。そのため、実務でスクレイピングを行う際は、次の3点を必ず確認してください。
- 公開ページのみを対象にする:ログインが必要な会員限定情報や、個人の予約履歴などは対象外とする
- アクセス頻度を人間の閲覧に近づける:短時間に大量リクエストを送らず、適切な間隔を空けてサーバー負荷を抑える
- 取得データの二次利用範囲を確認する:収集したデータを外部に販売・再配布する場合は、著作権や利用規約への抵触リスクを個別に確認する
スクレイピングの合法性そのものについては誤解も多く、スクレイピングのよくある誤解10選や実施前に確認すべき10の質問で体系的に整理しています。 なお、アクセス過多によるIPブロックへの対処法はブロックされないための対策記事で詳しく解説しています。
Booking.comのスクレイピングに関するよくある質問(FAQ)
Q. Booking.comのスクレイピングは違法ですか?
スクレイピングという行為自体は、公開されている情報を機械的に読み取るものであり、直ちに違法になるわけではありません。ただし、Booking.comの利用規約は営利目的での無断スクレイピングを禁じているため、規約への抵触リスクを理解したうえで、公開情報のみを対象に、サーバーへの負荷を抑えた形で行うことが前提になります。判断に迷う場合は専門家への相談をおすすめします。
Q. プログラミング知識がなくてもBooking.comのデータ収集はできますか?
できます。Octoparseのようなノーコードツールを使えば、URLを入力してクリック操作をするだけで、ホテル名・価格・評価などの宿泊施設リストを自動作成できます。本稿で紹介した手順のとおり、専用テンプレートを使えばさらに短時間で完了します。
Q. Booking.com APIとスクレイピングツールはどちらを使うべきですか?
正規パートナーとして契約でき、決まった項目を安定的に取得したいならAPIが適しています。一方、契約のハードルが高い、または取得したい項目が柔軟に変わる場合は、Octoparseなどのスクレイピングツールのほうが導入しやすく、必要に応じて両者を併用する事業者も少なくありません。
Q. Booking.comのAIスクレイピングとは何ですか?
AIがページ構造を自動で解析し、指示するだけでデータ項目を判別・抽出してくれるスクレイピング手法を指します。OctoparseもAIによる自動識別機能を備えており、さらにOctoparse MCPを使うと、AIアシスタントからの指示でスクレイピングと分析までを一連の流れとして自動化できます。
Q. 収集したホテルリストはどのような形式でダウンロードできますか?
Octoparseで収集したデータは、Excel、CSV、JSON、HTMLなど複数の形式でダウンロードできます。評価順や価格順で並べ替えてから出力することもできるため、比較検討用の宿泊施設リストとしてそのまま活用できます。
まとめ
いかがでしょうか?この記事では、Booking.comのホテル情報とか、口コミとかを一括してスクレイピングする方法を詳しく紹介しました。Booking.comのスクレイピングは、目的に応じて手段を選べば決して難しいものではありません。まずは無料で始められるOctoparseのBooking.com 宿泊施設リストのテンプレートを試し、継続的なデータ収集や自社システムとの連携が必要になった段階で、API契約やOctoparse MCPの活用を検討するのが、コストと手間のバランスが取れた進め方です。まずは実際に手を動かして、ホテルリスト作成の効率化を体感してみてください。
競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール




