PythonでWebスクレイピングを始めたいものの、「何から準備すればよいのか」「どのライブラリを選べばよいのか」と迷う方も多いのではないでしょうか。 本記事では、Webスクレイピングの基礎知識から、Pythonを使って実際にスクレイピングを行う手順、さらに代表的なライブラリの特徴と選び方までをわかりやすく解説します。Python スクレイピングの全体像をつかみたい方にも、python スクレイピング サンプルコードを見ながら理解したい方にも役立つ内容です。
Webスクレイピングとは
Webスクレイピングとは、Webページに掲載された情報をプログラムで取得し、必要なデータだけを抽出・整理する方法です。人手でページを開いてコピーする代わりに、プログラムで同じ処理を自動化できるため、情報収集の効率化や定期的なデータ取得に役立ちます。
Webスクレイピングの利用シーン
・競合サイトの商品名・価格・在庫状況の収集
・ニュースサイトやブログの見出し一覧の取得
・不動産・求人・口コミなどの公開情報の定点観測
・社内で使うためのリサーチデータの整形・集約
Webスクレイピングの仕組み
一般的な流れは、①WebページにアクセスしてHTMLを取得する、②HTMLの構造を解析する、③必要な要素を抽出する、④抽出結果をファイルやデータベースに保存する、という4段階です。Pythonはこの一連の処理に使えるライブラリが豊富で、初心者でも比較的短いコードで始めやすいのが特長です。
Webスクレイピングを実施する際の注意点
Webスクレイピングは便利な技術ですが、対象サイトへの配慮やルールの確認は欠かせません。特に以下の点は事前に確認しておきましょう。
Webサイトの利用規約・著作権を事前に確認する
対象サイトによっては、自動取得を制限していたり、取得後の利用方法に条件を設けていたりします。公開情報であっても、利用規約や著作権、関連法令に反しないように確認してから実施することが重要です。
robots.txtの指示を守る
サイト運営者がクローラー向けに公開している robots.txt には、クロールの可否や対象範囲に関する指示が記載されている場合があります。実務では、対象サイトの運用方針を確認し、不要なアクセスを避ける姿勢が大切です。
リクエスト間隔を適切に設定する
短時間に大量のアクセスを送ると、相手サイトへ負荷をかけたり、アクセス制限の原因になったりします。取得頻度や同時接続数を必要十分に抑え、無理のない間隔で実行しましょう。
PythonでWebスクレイピングを行う手順
Pythonでスクレイピングを行う場合、まずは対象サイト・必要な項目・保存形式を整理してから実装を始めると進めやすくなります。ここでは、基本的な流れを6ステップで紹介します。なお、まずはGUIで取得対象を確認し、運用段階でPython実装へ発展させたい場合は、Octoparseのようなツールでページ構造を把握してからコード化する進め方も有効です。
1. スクレイピング対象サイトを決める 最初に、どのサイトから何を取得するのかを明確にします。ニュース、EC、求人、不動産など、対象によってHTML構造や更新頻度が異なるため、必要なデータ項目もあわせて整理しておきましょう。
2. ライブラリをインストールする Pythonでスクレイピングを行う際は、Requests、Beautiful Soup、Scrapyなどのライブラリがよく使われます。まずは用途に応じて必要なライブラリをインストールします。
3. HTMLをダウンロードする 対象のURLにアクセスし、HTMLを取得します。まずは requests.get() を使って、レスポンスが正常に返るか確認するところから始めると分かりやすいです。
4. HTMLを解析する 取得したHTMLを BeautifulSoup などで解析し、title、見出し、リンク、価格など必要な要素へアクセスできる状態にします。
5. 必要な情報を抽出する find()、find_all()、select() などを使って、必要なデータだけを抽出します。複数項目を取る場合は、あらかじめどのHTML要素から取得するか整理しておくと実装しやすくなります。
6. 抽出したデータを保存する 最後に、取得した結果をテキスト、CSV、JSON、データベースなどへ保存します。後で集計や分析に使うことを考えると、CSVやJSONで保存しておくと扱いやすくなります。
Pythonスクレイピングのサンプルコード
以下は、Requests と Beautiful Soup を使ってページタイトルと見出しを取得し、CSVに保存する基本的なサンプルコードです。このコードは、python スクレイピング サンプルコードとして全体の流れをつかむための入門例です。ここで紹介する「おすすめライブラリ8選」すべてに個別コードが付いているわけではなく、まずは基本の実装イメージを理解することを目的としています。
なお、実際に取得したい要素を見つける際は、ブラウザの開発者ツールでHTML構造やCSSセレクタを確認すると効率的です。まずは title や h1 など分かりやすい要素から試し、そこから必要な項目へ広げていくと理解しやすくなります。
Pythonのスクレイピングでおすすめのライブラリ8選
Pythonには、Webスクレイピングを効率的に行うためのライブラリが複数あります。ここでは、用途別に使い分けやすい代表的なライブラリを8つ紹介します。
Beautiful Soup
Beautiful Soupは、HTMLやXMLの解析に向いた定番ライブラリです。シンプルな記法で扱いやすく、初心者が最初に触れるライブラリとしてよく使われます。
メリット
✓ シンプルな記法で要素を抽出しやすい
✓ 壊れたHTMLにも比較的強い
✓ 学習コストが低い
注意点
・JavaScriptで動的に生成される要素はそのままでは取得しにくい
・大規模なクロールには向きにくい
Scrapy
Scrapyは、クローリングとスクレイピングをまとめて扱いやすいフレームワークです。複数ページの巡回や大規模データ収集に向いています。
メリット
✓ 複数ページの巡回やページネーションに強い
✓ 出力形式を整理しやすい
✓ 大規模案件に発展させやすい
注意点
・初学者には設定項目が多く感じやすい
・小規模案件にはやや重い場合がある
Requests-HTML
Requests-HTMLは、HTTP取得とHTML解析を比較的まとめて扱いやすいライブラリです。シンプルな記述で試したいケースに向いています。
メリット
✓ 比較的シンプルに書ける
✓ 小さな検証や試作に使いやすい
注意点
・大規模案件には向きにくい
・高度なクロール機能は限定的
Selenium
Seleniumは、ブラウザを自動操作するための代表的なライブラリです。ログインやクリック、スクロールなどの操作が必要な動的ページに向いています。
メリット
✓ 動的ページに対応しやすい
✓ フォーム入力やクリック操作を自動化できる
✓ ブラウザ実操作に近い確認ができる
注意点
・処理が重くなりやすい
・環境構築の手間がかかる
Playwright
Playwrightは、複数ブラウザの自動操作に対応したライブラリです。動的コンテンツの取得やブラウザ操作を比較的安定して行いたい場合に向いています。
メリット
✓ JavaScriptを含むページに対応しやすい
✓ 複数ブラウザを扱える
✓ 自動操作の安定性を重視しやすい
注意点
・学習コストはやや高め
・単純な静的ページ取得にはオーバースペックになりやすい
PyQuery
PyQueryは、jQueryに近い感覚でHTMLを扱えるライブラリです。CSSセレクタに慣れている場合は理解しやすいのが特長です。
メリット
✓ CSSセレクタで直感的に書きやすい
✓ HTML操作が分かりやすい
注意点
・情報量はBeautiful Soupほど多くない
・大規模用途には向きにくい
Lxml
Lxmlは、HTMLやXMLを高速に解析したい場合に選ばれやすいライブラリです。速度を重視する場面で有力です。
メリット
✓ 解析速度が速い
✓ XPathを使った抽出がしやすい
✓ 他ライブラリと組み合わせやすい
注意点
・初学者には少し取っつきにくい
・単純な用途ではやや硬く感じることがある
Splash
Splashは、JavaScriptを含むページのレンダリング用途で使われることがあるツールです。レンダリングが必要なケースで検討対象になります。
メリット
✓ 動的コンテンツの取得を補助できる
✓ API経由で扱える
注意点
・構成がやや複雑になりやすい
・用途を絞って検討したほうがよい
プロジェクトに最適なPythonスクレイピングライブラリの選び方
Webスクレイピングプロジェクトでは、目的や規模に応じて適切なライブラリを選ぶことが非常に重要です。それぞれのライブラリには特化した用途や利点があり、プロジェクトの要件に応じて適切なツールを選ぶことが成功の鍵となります。ここでは、プロジェクトの種類やニーズに応じたライブラリの選択基準を解説します。
プロジェクトの規模
プロジェクトの規模に応じて使用するライブラリが異なります。小規模から大規模まで、それぞれに適したライブラリを紹介します。
小規模プロジェクト
シンプルなデータ抽出やHTML解析が中心であれば、Beautiful SoupやRequestsが適しています。これらのライブラリは、設定が簡単で軽量なため、少量のデータ収集やHTMLの構造解析に最適です。初心者でも簡単に使いこなせるAPIを提供しています。
中規模プロジェクト
複数ページにわたるスクレイピングや、複雑なHTML構造の処理が必要な場合は、Scrapyが有効です。Scrapyは、並行処理が可能で、大規模なWebサイトから効率的にデータを収集できます。
大規模プロジェクト
大量のデータを効率的に収集する必要がある場合や、複数のページをクロールしてデータを集める場合は、ScrapyやPlaywrightが最適です。これらのライブラリは分散処理や非同期処理に対応しており、リソースの負担を軽減しながら高効率で作業を進めることができます。
動的コンテンツやJavaScript対応の必要性
JavaScriptが使用されている動的なWebページに対しては、特定のライブラリが適しています。これらのライブラリを使うことで、JavaScriptの処理やブラウザの操作が自動化できます。
JavaScriptによる動的コンテンツ
動的にコンテンツが生成されるWebページや、JavaScriptのレンダリングが必要な場合は、SeleniumやPlaywrightが適しています。これらのライブラリは、ブラウザを自動操作し、JavaScriptによって生成されたコンテンツを正確に取得できます。
ログインやフォームの自動操作
ログイン認証が必要なWebサイトや、ユーザーが入力するフォームを操作する必要がある場合も、SeleniumやPlaywrightが効果的です。これらのツールは、ブラウザでの人間の操作をエミュレートし、フォーム入力やクリックなどのユーザー操作を自動化します。
処理速度やパフォーマンスを重視する場合
大量のデータを高速に収集したい場合や、効率的な処理が求められる場合には、非同期処理や並列処理に対応したライブラリが適しています。
大量データの高速収集
大規模なWebサイトから高速にデータを収集する場合は、非同期処理が得意なScrapyやHTTPXが最適です。これらのライブラリは、複数のリクエストを並列に処理し、データ取得を大幅に効率化します。
軽量でシンプルなリクエスト処理
単純なHTTPリクエストや小規模なデータ取得であれば、Requestsが最適です。軽量かつシンプルなライブラリであり、不要な機能を排除しているため、処理が軽く、パフォーマンス重視のプロジェクトに適しています。
簡単にWebスクレイピングを始めるならスクレイピングツールの活用がおすすめ
Webスクレイピングを行うために、必ずしもコーディングスキルが必要というわけではありません。スクレイピングツールを活用することで、初心者でも手軽にデータ抽出を行うことができます。
ここでは、スクレイピングツールについて解説し、特におすすめのツール「Octoparse」を紹介します。
スクレイピングツールとは
スクレイピングツールは、コードを書くことなく、視覚的なインターフェースを通じてWebスクレイピングを実行できるツールです。以下のような特徴があります。
- 視覚的インターフェース:GUIベースで使えるため、ドラッグ&ドロップで簡単に設定できる。
- ノーコードで設定可能:プログラミングの知識がなくてもデータ抽出が可能。
- 多機能で拡張性も高い:データの自動化やスケジュール実行、動的コンテンツの処理など高度な機能も搭載されているものが多い。
Octoparseの特徴
Octoparse(オクトパス)は、数あるスクレイピングツールの中でも人気の高いソリューションです。初心者にも使いやすく、多機能な点が魅力です。Octoparseの特徴は次のようなものが挙げられます。
- コード不要で簡単に使用可能:GUIベースで操作でき、直感的にスクレイピングの設定ができるため、誰でも簡単にデータを取得可能。
- 動的コンテンツにも対応:JavaScriptで生成された動的コンテンツやログインが必要なサイトからもデータを抽出可能。
- 自動化とスケジューリング:データ抽出をスケジュールして定期的に実行できるため、日々の更新を自動で収集できる。
以下は、自動検出機能を使って数回クリックするだけでタスク(クローラー)を作成できる例です。
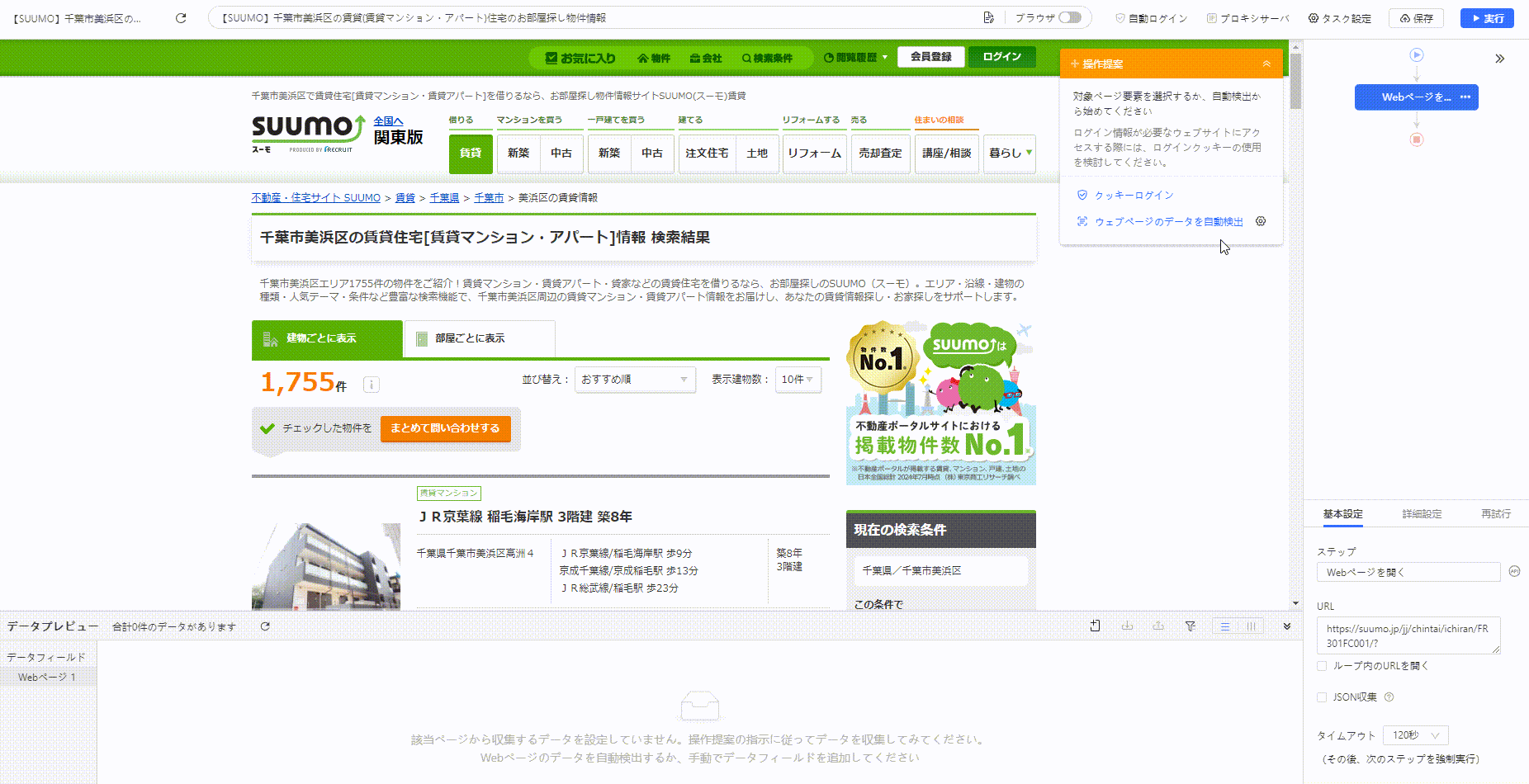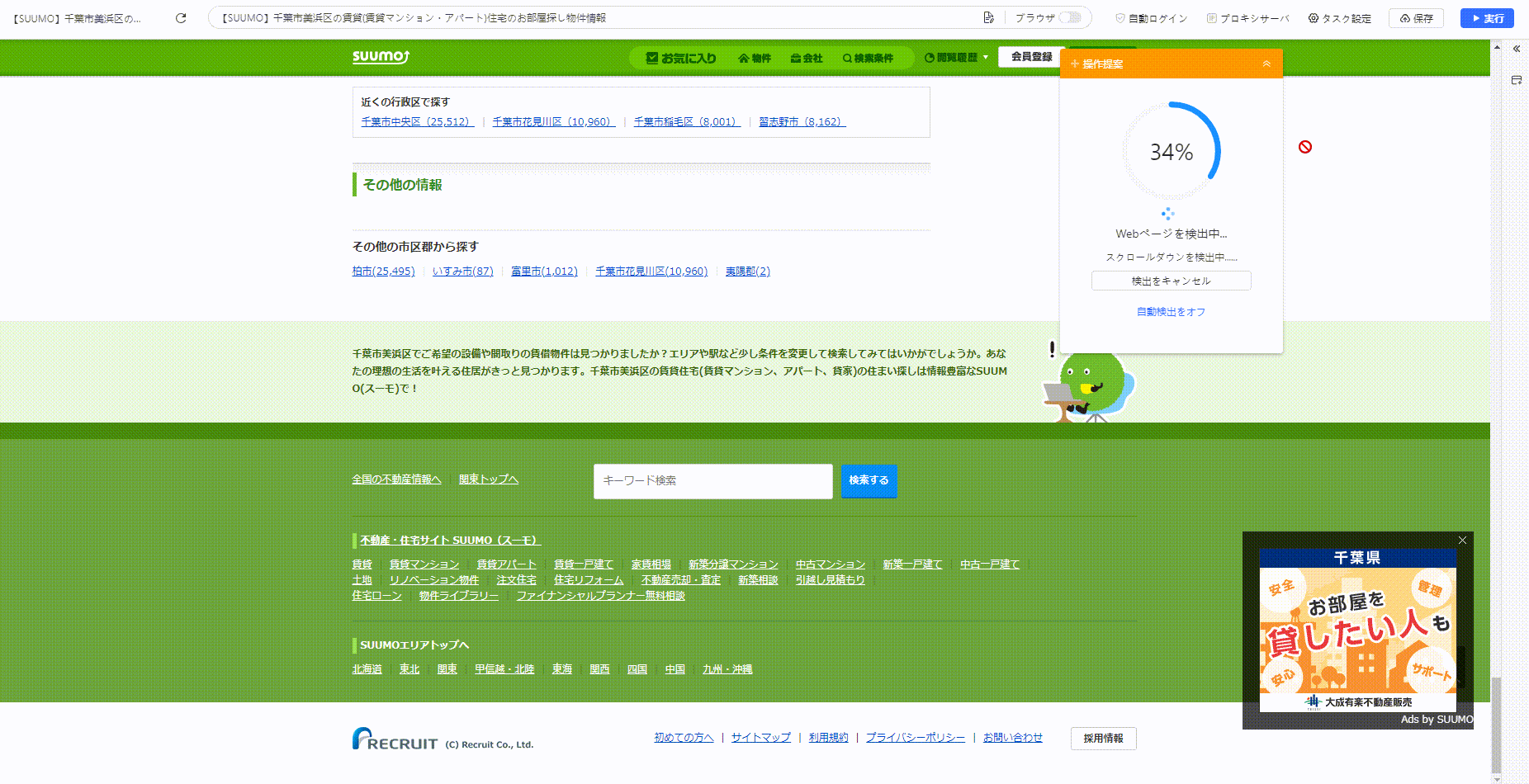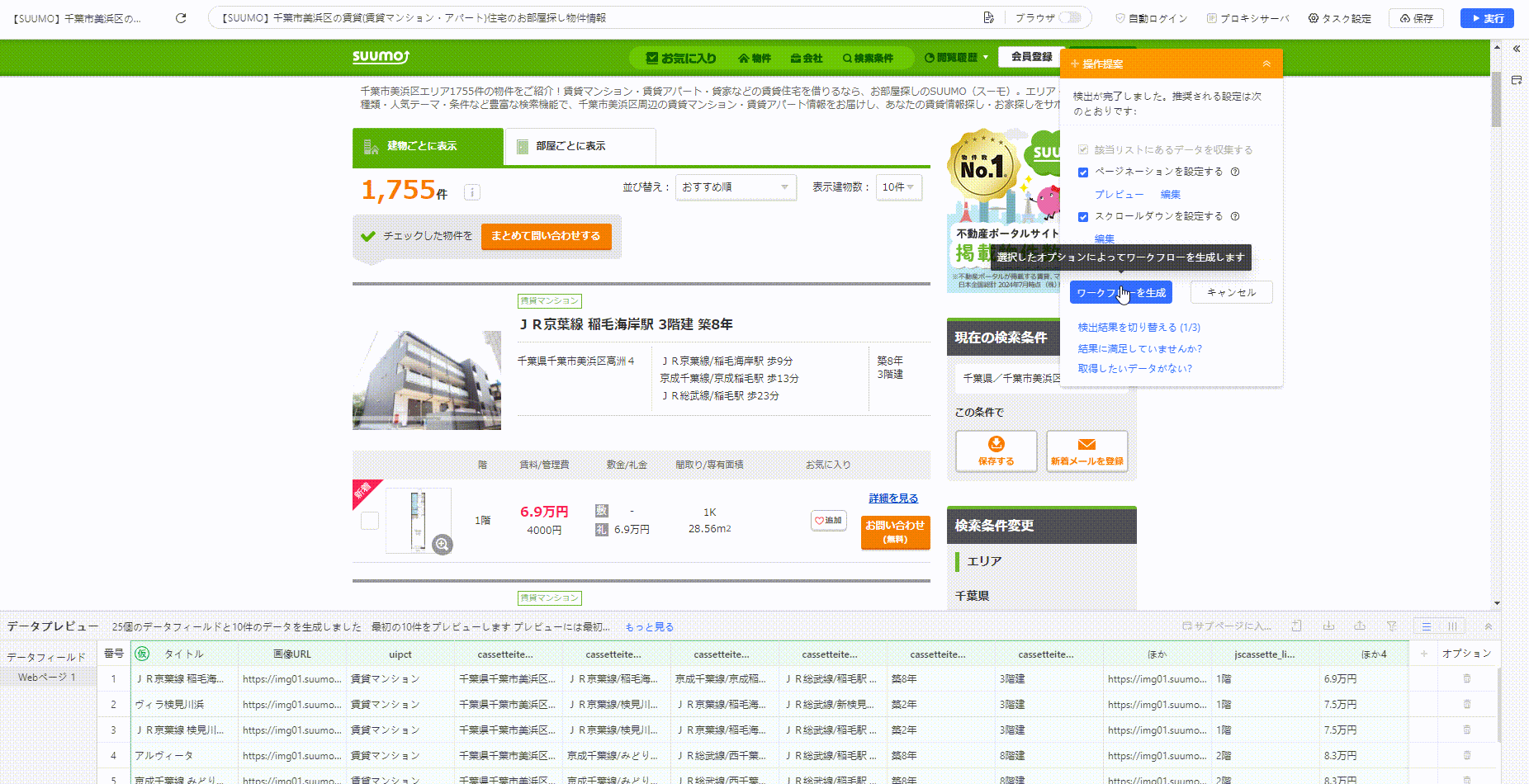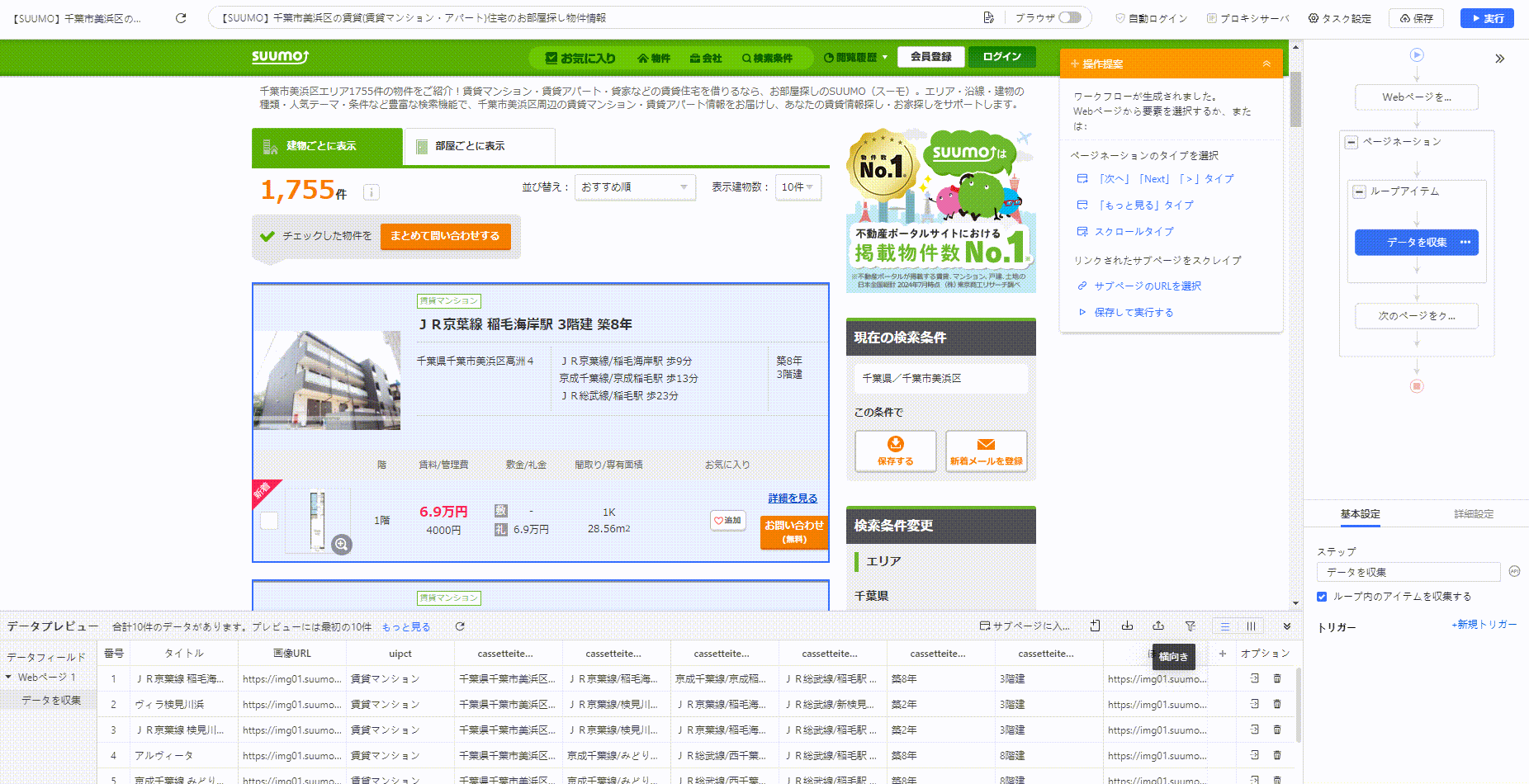
一方で、Octoparseは高度なデータ収集には向かない場合があります。より、複雑かつ大量なデータ収集を求められる場合は、Pythonを用いたスクレイピングをおすすめします。
- 複雑な設定には限界がある:細かいカスタマイズや大規模プロジェクトには、コードベースのスクレイピングが必要な場合もある。
- 有料版が必要:無料プランでは機能に制限があり、フル機能を利用するには有料版へのアップグレードが必要。
まとめ
この記事では、Webスクレイピングの基礎からPythonでの具体的な手順、さらにプロジェクトに最適なライブラリの選び方までを詳しく解説しました。Pythonは、シンプルな文法と豊富なライブラリを備えており、スクレイピングを行うのに最適な言語の一つです。
一方、プログラミング初心者がイチからPythonを習得するのは時間と労力が掛かります。もし、手軽にスクレイピングを行いたい場合は、コード不要で使えるスクレイピングツール「Octoparse」を利用すれば、簡単にデータを抽出できます。データ取得の目的や運用規模にあわせて最適な方法を取り入れていきましょう。




