Webスクレイピングを行う上で、重要な役割を担うのが「XPath」です。しかし、XPathについて正しく理解できていない方も多いでしょう。そこで今回はXPathについて、基本から書き方までわかりやすく解説します。それに、XPathでスクレイピングする手順とXPathを取得する方法もご説明します。
XPathとは
XPathとは、「XML Path Language」の略で、XML形式で記述された文書から、特定のデータを指定して抽出するための、問い合わせ言語を指します。
XPathで条件を指定することで、Webページ上の任意のテキストや画像などを抽出します。XPathは、Webスクレイピングによってデータを取得する際に利用されることの多い言語です。
XPathを表示・取得するには
XPathを取得する方法は、お使いのブラウザによって異なります。ここでは、「Chrome」と「Firefox」を使ったXPathの取得方法を解説します。
Chrome
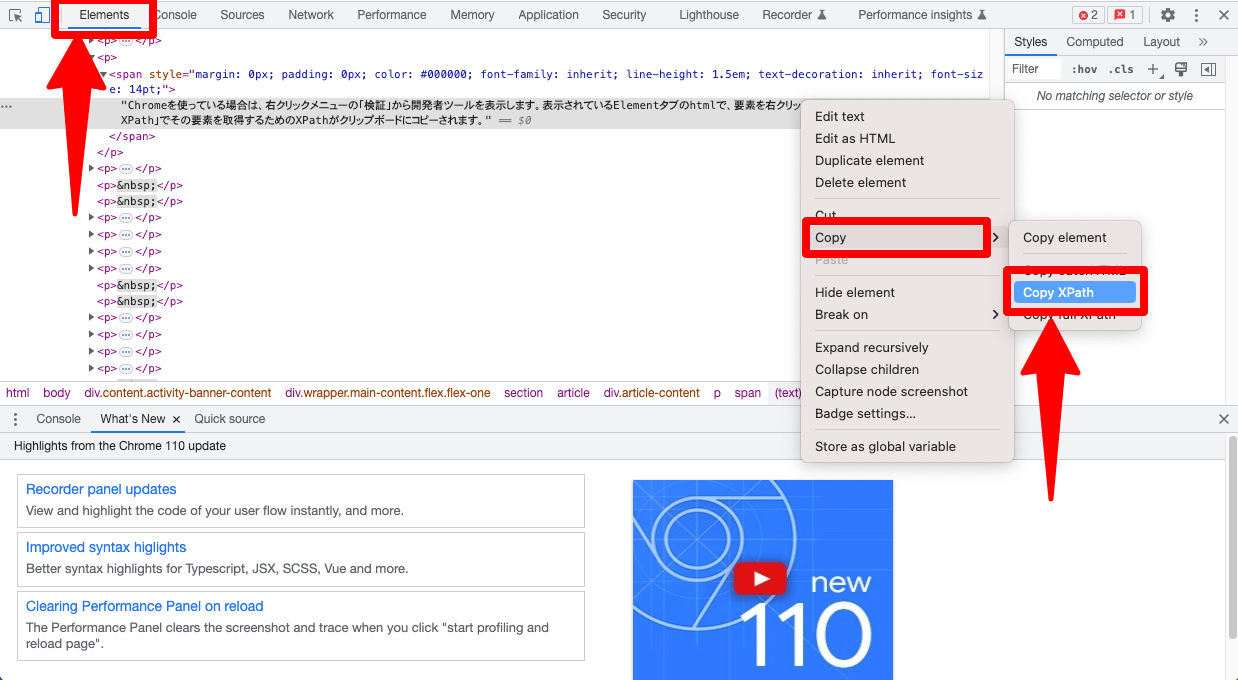
「Chrome」では、右クリックメニューの「検証」から開発者ツールを表示します。表示されているElementsタブのhtmlで、要素を右クリックします。メニューの「Copy」→「Copy XPath」でその要素を取得するためのXPathがクリップボードにコピーされます。
Firefox
「Firefox」でXPathを表示するには、 Firefox のアドオンである『Firebug』を使います。Firebugは、Webページ上の任意の要素のHTML / CSSを検索して、Webページのデバッグと開発を容易にするFirefoxアドオンです。
FirefoxでWebページを開き、Firebugボタンをクリックし、ページ内の要素をクリックして、そのXPathを取得できます。または、ページを右クリックするだけで、「Inspect in FirePath」オプションが表示されます。「Inspect in FirePath」は Firefox のアドオン「FirePath」の機能であるため、「FirePath」アドオンがインストールされていることが前提となります。
表示されているElementタブのhtmlで、要素を右クリックし、「Copy XPath」でその要素を取得するためのXPathがクリップボードにコピーされます。
Firebugは旧バージョンのFirefoxでのみ利用可能です。古いバージョンのFirefoxをダウンロードする
現在は Firefox に代わって「Firefox 開発者ツール」が推奨されており、「Firefox 開発者ツール」にも XPath の機能があります。
XPathの書き方
OctoparseはXPath を自動的に見つけ出すデータ抽出ツールです。Octoparseで自動認識したXPathはブラウザでコピーしたXPathと同じです。
しかし、XPathの表示式が多いため、多くのページを処理する場合は、XPathが無効になる可能性があります。その場合は、XPathを自分で書く必要があります。
ここではXPathについて解説していきます。
まず、XPathフォーマットには、以下のような主要な要素があります。
1.軸(Axis):軸と呼ばれる概念を使用して、文書のノードを検索するための基準を設定します。軸には、祖先、子孫、兄弟などがあります。
2.ノード(Node):XML文書の中のノードを特定するために使用されます。ノードには、要素、属性、テキスト、コメントなどがあります。
3.パス(Path):XML文書内のノードを指定するためにパス表記を使用します。パスには、相対パスと絶対パスがあり、それぞれのパス表記でノードを指定することができます。
4.述語(Predicate):述語は、XPathの条件式で使用されます。述語を使用して、ノードを選択する条件を指定することができます。例えば、特定の属性値を持つ要素だけを選択するために述語を使用することができます。
5.関数(Function):関数を使用して、ノードや文字列などを処理することができます。XPathでは、数学関数、文字列関数、日付関数、ノード関数などのさまざまな種類の関数があります。
XPathは、親子関係や属性、テキスト値といった要素を指定することができます。また、XPathは論理演算子、算術演算子、比較演算子を含めた多彩な構文を持ち、さらには関数を組み合わせることもできます。これらの構文を駆使することで、XMLドキュメント内の要素を高度に特定し、必要な情報を取得することができます。これらには、次のようなものがあります。
XPathは、スラッシュ(/)を使用してXMLドキュメントの要素を参照します。 XPath式は、XMLノードツリー内のパスを示し、各ノードはスラッシュで区切られます。たとえば、以下のXPath式は、XMLドキュメント内のルート要素の最初の子要素を参照します。
| /ルート要素/最初の子要素 |
1.ノードタイプ:XPath式では、XMLノードの種類を指定することができます。たとえば、次のXPath式は、ドキュメント内のすべての要素ノードを選択します。
| //要素ノード |
2.属性:XPath式では、属性も参照することができます。たとえば、次のXPath式は、XMLドキュメント内のすべてのhref属性を含む要素を選択します。
| //要素[@href] |
3.テキストノード:XPath式は、テキストノードも指定できます。たとえば、次のXPath式は、XMLドキュメント内のすべてのテキストノードを選択します。
| //テキスト() |
XPathフォーマットについての説明をテーブル形式で示します。
| 要素 | 意味 |
| 軸::ノードテスト[式] | XPathの書式 |
| 軸 | ツリー上の位置関係を指定するもの |
| child:: | 子ノード |
| self:: | カレントノード |
| parent:: | 親ノード |
| descendant-or-self:: | すべてのノード |
| // | ルートノードの子孫ノードから要素ノードelementを全て選択 |
| attribute:: | 属性ノード |
| ancestor:: | 祖先ノード |
| descendant:: | 子孫ノード |
| following:: | 起点より後に位置するノードすべて(子孫ノードを除く) |
| preceding:: | 起点より前に位置するノードすべて(祖先ノードを除く) |
| following-sibling:: | 起点より後に位置する兄弟ノード |
| preceding-sibling:: | 起点より前に位置する兄弟ノード |
| ノードテスト | 選択するノードの型と名前を指定するもの |
| ロケーションパス | 特定のノードの位置を指定するための式 |
| 相対ロケーションパス | 現在位置のノードを起点として指定するロケーションパス |
| 絶対ロケーションパス | ルートノードを起点として指定するロケーションパス |
| 省略シンタックス | 記述方法を簡略化したロケーションパス |
| name | 子要素nameまたは属性name |
| / | ルートノードを選択 |
| // | ルートノードの子孫ノードから要素ノードelementを全て選択 |
| . | カレントノード(現在位置のノード)を選択 |
| .. | カレントノードの親を選択 |
| @ | 属性ノードを選択 |
| * | 指定したパスの直下の全ての子要素または属性 |
| text() | 指定したパスの直下のテキストを選択 |
| node() | 指定したパスの直下のノードを選択(属性ノードは含まない) |
| 式 | ノードを限定するために使用する条件 |
XPathを試してみる
XPathの書き方を理解できたところで、いくつかの例を通して、実際にXPathを書いてみましょう。
ここでは、以下のXML文書を例として使います。
この文書に対して、いくつかのXPath式を試してみましょう。
例1: 特定のタイトルの本の著者を取得する
タイトルが「The Great Gatsby」の書籍の著者を取得するXPath:
例2: すべての本のタイトルを取得する
例3: 1950年以降に出版された本のタイトルを取得する
Pythonでの実行例
これらのXPath式をPythonで実行する例を示します。
このコードを実行すると、以下のような出力が得られます:
このように、XPathを使用することで、XML文書から特定の条件に合致するデータを簡単に抽出できます。最後の追加例では、より複雑なXPath式を使って、最も古い本の情報を取得しています。これは、XPathのnot()関数と比較演算子を組み合わせて実現しています。
XPathでスクレイピングする手順は?
XPathを使用したWebスクレイピングは、以下の手順で行います。各ステップについて、詳細な説明と具体的なコード例を示します。
1. ライブラリのインポート
Pythonでは、XPathを使用するために主にlxmlライブラリを使用します。また、HTTP リクエストを送信するためにrequestsライブラリも必要です。
2. HTMLの取得
スクレイピングしたいウェブページのHTMLを取得します。requestsライブラリを使用して、指定したURLにHTTPリクエストを送信し、レスポンスを取得します。
3. XPathの作成
取得したHTMLに対してXPathを作成します。XPathは、ウェブページの構造に基づいて特定の要素を選択するためのパスです。例えば:
//h1: ページ内のすべてのh1タグを選択//div[@class="product"]: class属性が”product”のすべてのdiv要素を選択//a[@href]: href属性を持つすべてのaタグ(リンク)を選択
より高度なXPath式の例:
//div[contains(@class, "article")]//p[1]: class属性に”article”を含むdiv要素内の最初の段落(p要素)を選択//table//tr[position() > 1]//td[2]: テーブルの2行目以降の2列目のセルを選択
4. XPathを使用して要素を選択
lxmlのetreeライブラリを使用してHTMLを解析し、作成したXPathを適用して要素を選択します。
5. 取得したデータの処理
選択した要素から必要なデータを抽出し、必要に応じて処理します。
高度なXPathの使用例
より複雑なデータ抽出のための高度なXPath使用例:
これらの手順を組み合わせることで、XPathを使用して効率的なWebスクレイピングを行うことができます。ウェブページの構造を理解し、適切なXPath式を構築することが、データ抽出の鍵となります。また、Webスクレイピングを行う際は、対象ウェブサイトの利用規約を遵守し、サーバーに過度な負荷をかけないよう注意することが重要です。
まとめ
Webスクレイピングに便利なXPathについて解説しましたが、いかがでしょうか?
初心者の方にはやや難しい内容ですが、XPathはWebスクレイピングに活用するために、不可欠なものですので、ぜひ頑張って理解してみてください。Webスクレイピングツールで直接にデータを取得したい場合、便利で使いやすいスクレイピングソフトOctoparseをおすすめします。
もしこの記事の内容だけではわかりにくいと感じましたら、以下の記事も併せて参考にしてください。




