データ収集は現代のビジネスにおいて重要な役割を果たしています。マーケティング戦略の構築、顧客のニーズの把握、競合他社の動向分析など、さまざまな場面でデータの有効活用が求められています。しかし、従来のデータ収集方法は多くの時間とコストがかかる上に、専門的な知識が必要とされることが多いです。
そこで注目されているのが、ノーコードツールを使ったデータ収集方法です。ノーコードツールを使えば、プログラミングの知識がなくても、効率的にデータを収集・活用できます。本記事では、ノーコードツールを使ったデータ収集のメリットや手順を解説しますので、ぜひ参考にしてください。
データ収集の課題とは
データ収集は現代のビジネスにおいて欠かせないものですが、多くの企業がその過程で直面するさまざまな課題があります。以下では、データ収集に関連する主な課題について詳しく見ていきます。
データ収集に時間が掛かる
データ収集の一つ目の課題は、その過程に時間がかかることです。ビジネスが成長するにつれて必要なデータ量は増加し、従来の手動でのデータ収集方法では対応しきれなくなります。
データの収集から整理、分析に至るまでのプロセスは膨大な時間を要し、その結果、他の重要な業務に割く時間が減少してしまいます。迅速に市場の変化に対応するためには、データ収集の効率化が不可欠です。
コストが掛かる
データ収集に関連するもう一つの課題はコストです。専用のデータ収集ツールやソフトウェアを導入するには多額の費用がかかり、またその運用には専門知識を持った人材が必要です。
さらに、手動でのデータ収集は人件費もかさみます。特に中小企業にとっては、このコストは大きな負担となり、データ収集の取り組みを制限する要因となります。
ツールを使いこなせない
データ収集のために導入したツールやソフトウェアを効果的に使いこなせないという課題もあります。多くのツールは専門的な知識やスキルを要求し、使い方を習得するためのトレーニングが必要です。
しかし、時間とリソースに限りがある企業では、このようなトレーニングに十分な投資を行うことが難しく、結果的にツールの活用が不十分となってしまいます。
データ収集でノーコード活用が進んでいる
これらの課題を解決する手段として、近年注目されているのがノーコードツールです。ノーコードツールは、プログラミングの知識がなくても簡単に操作できるため、企業にとって非常に魅力的な選択肢となっています。それでは、ノーコードツールの詳細と、その活用が注目される理由について見ていきましょう。
ノーコードとは
ノーコードとは、プログラミングの知識を必要とせず、視覚的なインターフェースを使ってアプリケーションやシステムを構築できる技術です。
これにより、専門的なプログラマーでなくても、自分のビジネスニーズに合ったツールを作成したり、データ収集を自動化することが可能になります。ノーコードツールは直感的に操作できるため、従来のコーディングに比べて短時間で効率的に作業を進めることができます。
ノーコード活用が注目される理由
ノーコードツールが注目される理由は、利便性の高さです。専門知識が不要なため、誰でも簡単に使用できる点が大きな魅力です。これにより、企業内のリソースを有効に活用し、従業員全員がデータ収集や分析に参加できるようになります。
また、ノーコードツールは導入コストが低く、運用費用も抑えられるため、特に中小企業にとっては大きなメリットとなります。さらに、迅速な市場対応が可能となり、ビジネスの競争力を高めることができます。
データ収集にノーコードを活用するメリット
ノーコードツールを活用することで、データ収集においてさまざまなメリットが得られます。以下では、その具体的な利点について詳しく解説していきます。
専門知識が不要で誰でも使える
ノーコードツールの最大の魅力は、プログラミングの専門知識が不要で誰でも使える点です。従来、データ収集や分析を行うためには、高度なプログラミングスキルが求められましたが、ノーコードツールを使えば、視覚的なインターフェースを操作するだけで簡単に作業を進めることができます。
これにより、IT部門だけでなく、営業やマーケティング部門のスタッフも自分たちで必要なデータを収集・分析できるようになり、業務の効率化が図れます。
データ収集に時間がかからない
ノーコードツールを使うことで、データ収集にかかる時間を大幅に短縮できます。自動化されたプロセスにより、手動でデータを集めるのに比べて圧倒的に早く、かつ正確にデータを収集することが可能です。
これにより、迅速に市場の変化に対応でき、ビジネスの意思決定をスピーディーに行うことができます。ノーコードツールの導入は、業務の効率化と生産性の向上に大きく貢献します。
コストを抑えることができる
ノーコードツールの導入は、コスト削減にもつながります。専用のデータ収集ソフトウェアやプログラマーを雇う必要がなく、低コストでデータ収集の自動化を実現できます。また、ツールの使用に特別なトレーニングが不要であるため、社員の教育にかかるコストも抑えられます。
これにより、特に中小企業においては、限られた予算内で効率的にデータ収集を行うことが可能となり、コストパフォーマンスの向上が期待できます。
ノーコードでデータ収集をする手順
ノーコードツールを活用してデータ収集を行う手順について解説します。この手順を理解することで、より効果的にノーコードツールを利用し、データ収集の効率を高めることができます。
データ収集の目的を明確にする
まず初めに、データ収集の目的を明確にすることが重要です。何のためにデータを収集するのか、どのようなデータが必要なのかを具体的に定めることで、収集プロセスがスムーズに進行します。
例えば、顧客の購買傾向を分析するためのデータを集める場合、必要なデータポイントをリストアップし、そのデータがどこから得られるのかを明確にすることが必要です。このように目的をはっきりさせることで、データ収集の効率と精度が向上します。
ノーコードツールを選定する
次に、データ収集に適したノーコードツールを選定します。市場には多くのノーコードツールが存在し、それぞれに特徴があります。
例えば、ウェブスクレイピングを行うツール、データベースから情報を抽出するツール、APIを利用してデータを収集するツールなどがあります。目的に合ったツールを選ぶことで、データ収集の効率が格段に向上します。また、ツールの使いやすさやサポート体制も選定の重要なポイントとなります。
データを収集する
ノーコードツールを選定したら、実際にデータを収集します。ツールの設定画面で収集するデータの種類や範囲を指定し、自動化プロセスを開始します。
例えば、ウェブスクレイピングツールでは、対象となるウェブサイトのURLを入力し、収集したいデータの要素を指定するだけで、自動的にデータを収集してくれます。ノーコードツールを活用することで、手動では難しい大量のデータを短時間で収集することが可能となります。
Octoparseを使ったデータ収集方法を解説
ステップ1.Octoparseをダウンロードする
- Octoparseのダウンロードページから、最新版をダウンロードします。
- アカウントを作成し、Octoparseにログインします。
Octoparseでは、ユーザーの目的やニーズに合わせ、いくつかのプランを用意しています。無料プランでも基本的な機能が備わっているため、データ収集の効率化を実現できます。より多くのデータが必要な場合や、高度な機能を利用したい場合は上位プランがおすすめです。
ステップ2.テンプレートの選択
Octoparseでは、あらかじめスクレイピングタスクがプリセットされた「クローラーテンプレート」が用意されています。クローラーテンプレートストアから、好きなテンプレートを選択します。
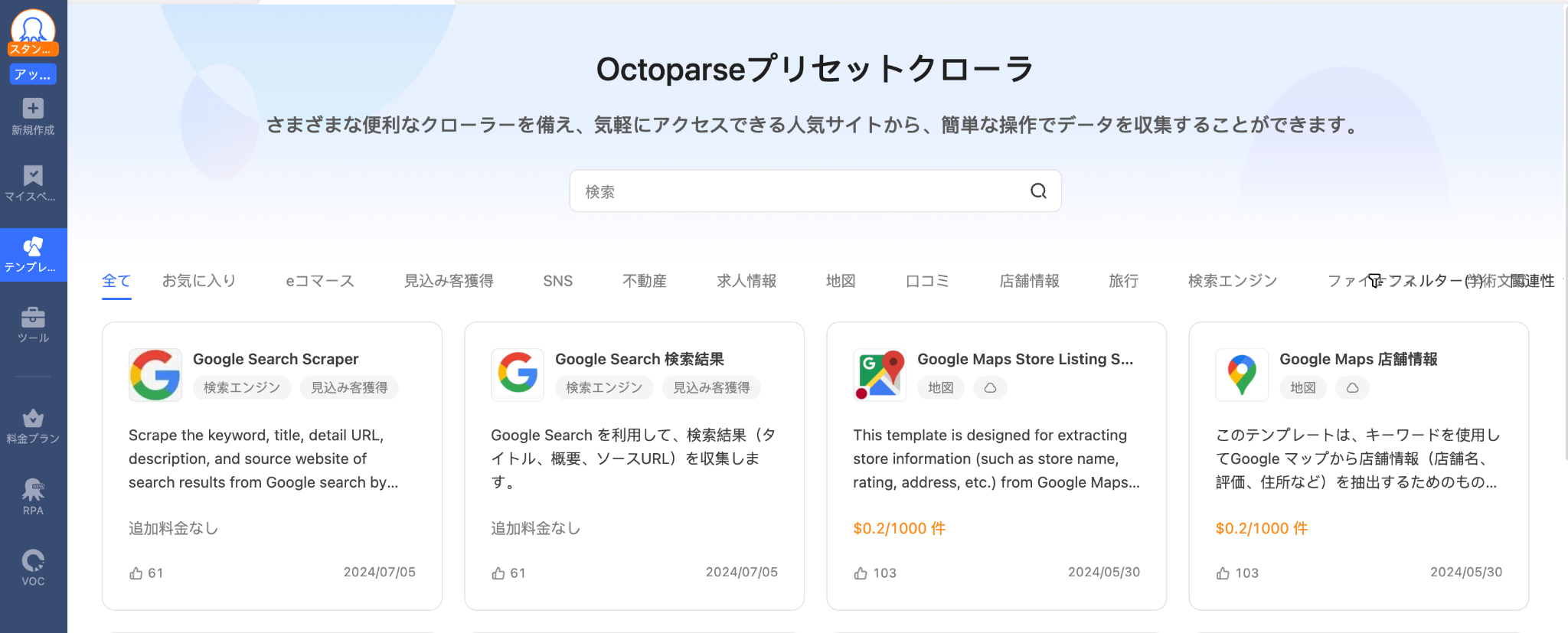
例として、「Yahoo!ニュース 最新情報」のテンプレートを使って、最新ニュースのタイトルや本文を抽出します。
データを取得したいYahoo!ニュースのURLをテンプレートに入力します。
ここでは、主要トピックス一覧ページの情報を抽出します。
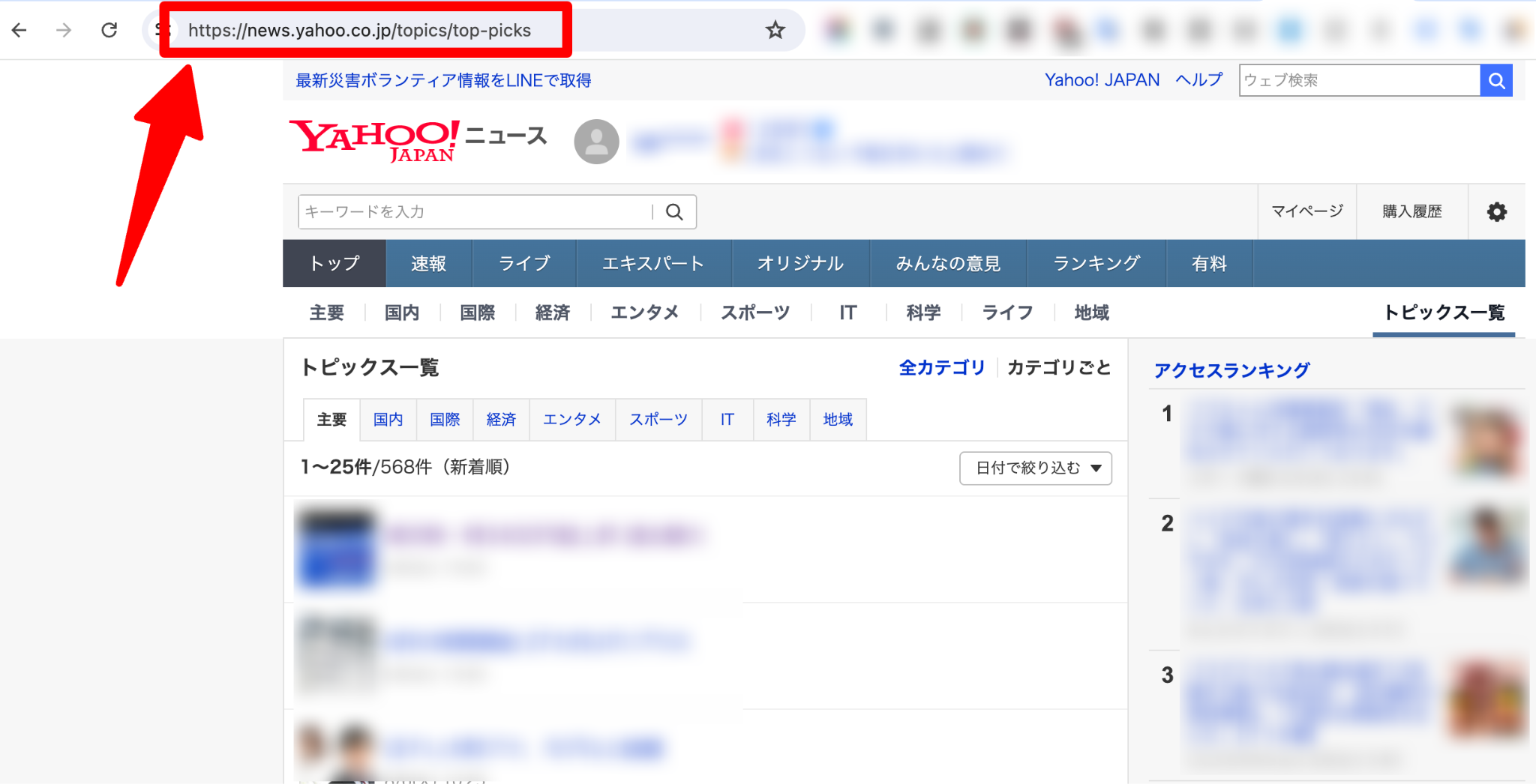
URLをコピーしたら、テンプレート内にペーストします。その後、実行ボタンをクリックしましょう。
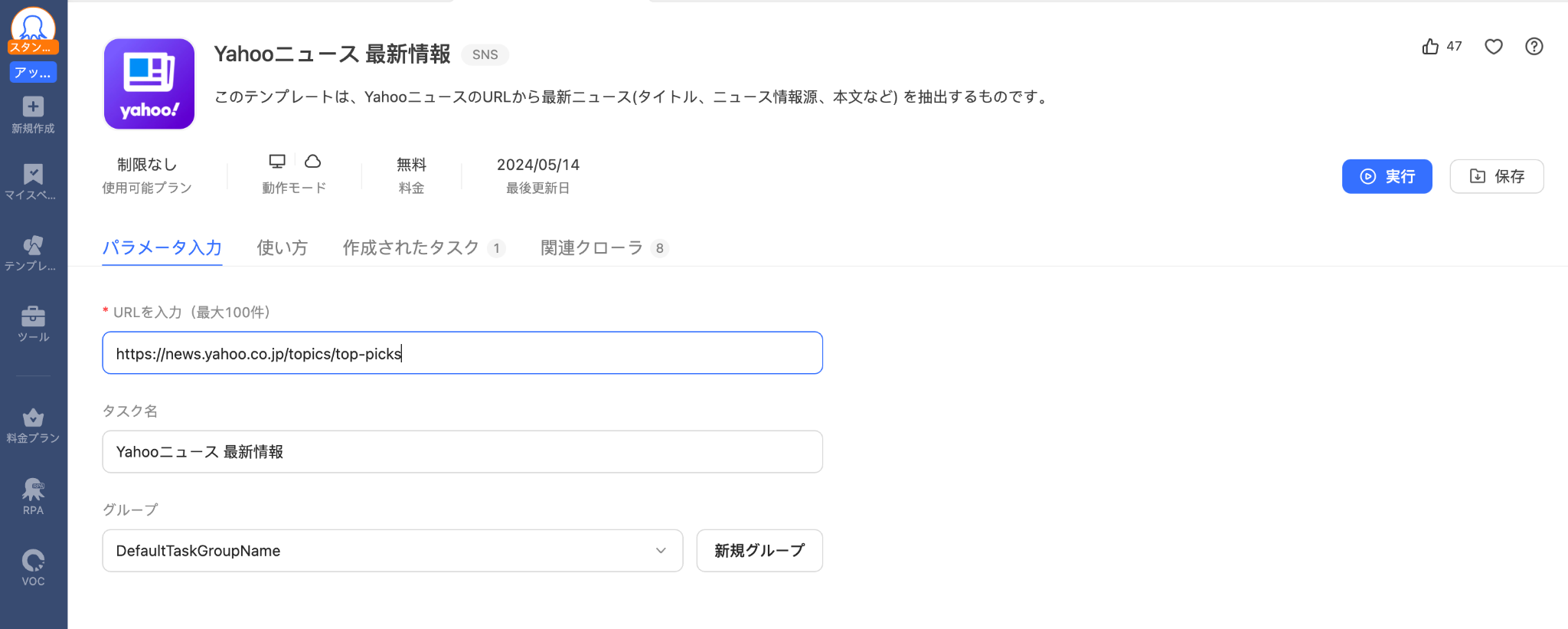
データリストに抽出したデータが表示されます。すべてのデータ抽出が完了するまで待ちましょう。データ抽出の途中で停止することも可能です。
また、データ抽出のスケジュール設定もできるため、決まった時間や日にちでの定期的なデータ抽出もかんたんに設定できます。
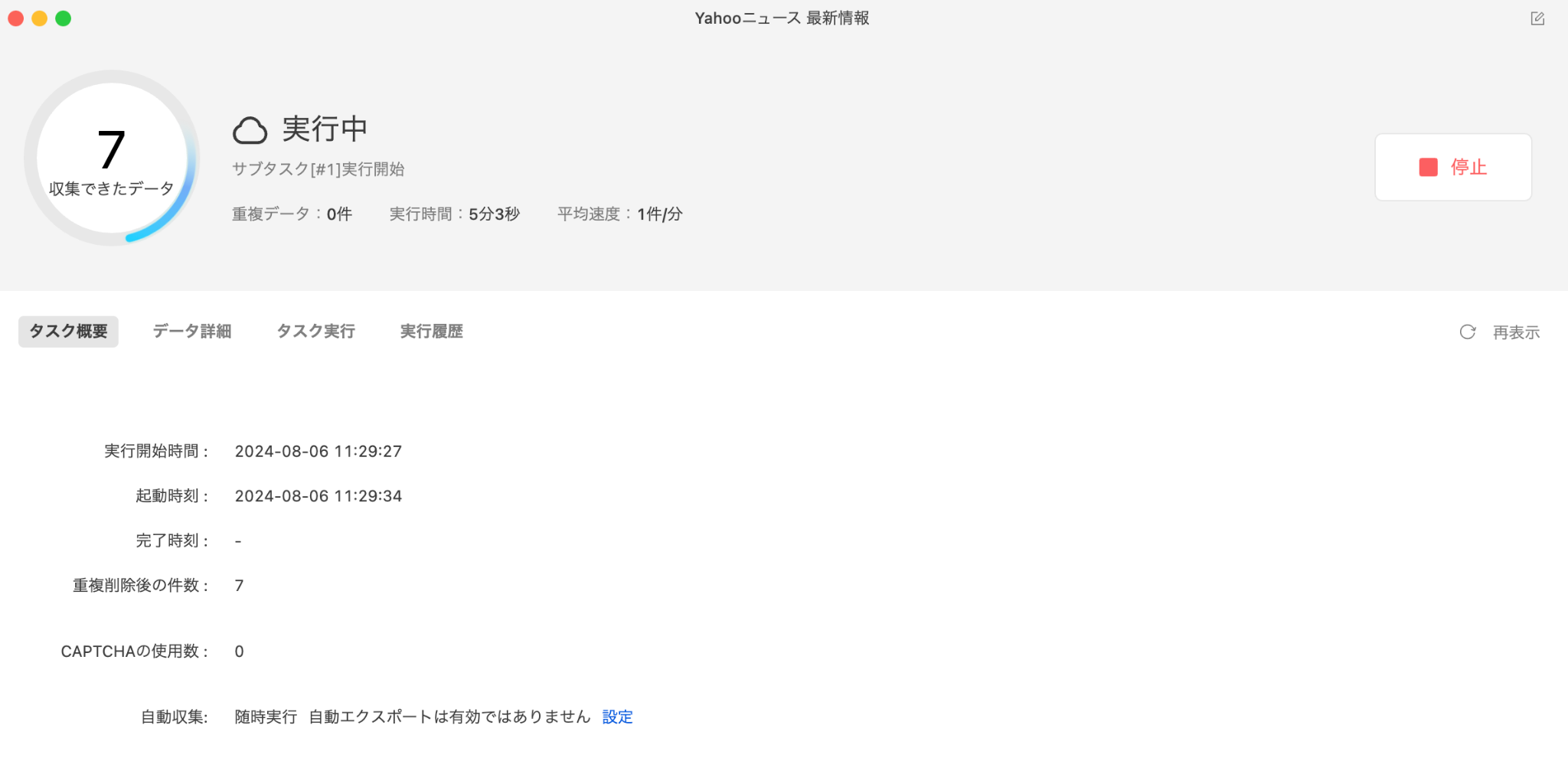
抽出したデータは、Excel、csv、HTML、JSONなど、さまざまな形式でエクスポートが可能です。このように、プログラミングを一切行わずに、Yahoo!ニュースに掲載されている記事のURLやタイトル、日付、ニュース情報源、本文まで、かんたんに抽出できました。

まとめ
ノーコードツールを活用したデータ収集は、現代のビジネスにおいて非常に効果的な手段です。プログラミングの知識が不要で誰でも使えること、迅速にデータを収集できること、そしてコストを抑えられることから、多くの企業で導入が進んでいます。本記事で紹介した手順を参考に、ノーコードツールを活用して効率的にデータ収集を行い、ビジネスの競争力を高めましょう。




