Webスクレイピングやテスト自動化で、Webページから狙った情報を取得するときに役立つのが「XPath」です。しかし、「XPathとは何か」「XPathの書き方がわからない」「ChromeでのXPath取得方法を知りたい」という方も多いのではないでしょうか。
本記事では、XPathの意味と仕組み、基本構文、Google Chromeを使ったXPath取得の手順を初心者向けに解説します。コピーしたXPathをそのまま使う際の注意点や、Webサイトの構造変更に強いXPathを書くコツも、具体例とともに紹介します。
この記事でわかること
- XPathとは何か、どのような場面で使うのか
- 絶対XPathと相対XPathの違い
- ChromeでXPathを取得・検証する方法
- タグ・属性・テキストを使ったXPathの書き方
- 壊れにくいXPathを作るポイント
XPathとは
XPath(XML Path Language)とは、XMLやHTMLのツリー構造をたどり、特定の要素や属性を指定するための言語です。フォルダの階層をたどってファイルを探すように、タグの親子関係や属性、テキストなどを手掛かりに目的の要素を選択します。
XPathはW3Cによって標準化されており、Webスクレイピング、ブラウザ操作の自動化、E2Eテスト、XMLデータの検索・変換などに利用されています。厳密にはXML向けに設計された言語ですが、ブラウザ上ではHTMLから要素を探す用途でも広く使われています。
XPathの仕様を詳しく確認したい場合は、W3CのXPath 3.1勧告も参考になります。ただし、ブラウザやスクレイピングツールが対応するXPathのバージョンや関数は、実行環境によって異なります。
XPathの主な活用例
- Webスクレイピング:商品名、価格、在庫、記事タイトルなどを取得する
- ブラウザ自動操作:入力欄やボタンを指定してクリック・入力を自動化する
- Webテスト:画面上の要素を特定し、表示内容や動作を検証する
- XML処理:XML文書やXML形式のAPIレスポンスから必要な値を抽出する
XPathとCSSセレクタの違い
HTML要素の指定にはCSSセレクタも使われます。CSSセレクタは短く読みやすい一方、XPathはテキスト内容を条件にする、親要素や直前の兄弟要素へ移動するといった指定が得意です。
| 比較項目 | XPath | CSSセレクタ |
|---|---|---|
| 属性による指定 | 可能 | 可能 |
| テキストによる指定 | 可能 | 標準のCSSセレクタでは困難 |
| 親・兄弟方向への移動 | 柔軟 | 用途によって制限がある |
| 記述の簡潔さ | 複雑になりやすい | 比較的簡潔 |
どちらか一方に決める必要はありません。対象ページの構造や利用するツールに合わせて使い分けるのが実務的です。
XPathの仕組み
XPathの書き方を理解するには、HTMLやXMLがツリー構造になっていることを押さえましょう。スラッシュ(/)で階層を区切りながら、目的の要素まで順にたどります。
例えば、書籍情報を管理するXMLデータで「author」要素に到達する場合は、次のように記述します。

XPathでは、スラッシュや角括弧、アットマークなどの記号を組み合わせて対象を絞り込みます。
| 記号 | 意味 | 例 |
|---|---|---|
/ | 直下の子要素をたどる | /bookstore/book |
// | 現在位置より下の階層から検索する | //author |
@ | 属性を指定する | //h1[@id='booksTitle'] |
[] | 条件や位置を指定する | //span[2] |
* | 任意の要素を表す | //*[@id='booksTitle'] |
.. | 親要素へ移動する | //h1/.. |
絶対XPathと相対XPathの違い
XPathには、ルートからすべての階層を指定する「絶対XPath」と、特定の要素を起点にする「相対XPath」があります。
絶対XPath
相対XPath
絶対XPathは対象の位置が明確ですが、途中に<div>が1つ追加されただけでも動かなくなることがあります。スクレイピングでは、変更されにくいidやdata-*属性を使った相対XPathのほうが、一般的に保守しやすくなります。
ChromeでXPathを取得する方法
ここでは、Google Chromeの開発者ツールを使ったXPath取得方法を解説します。拡張機能を入れなくても、Chromeの標準機能だけでXPathをコピーできます。
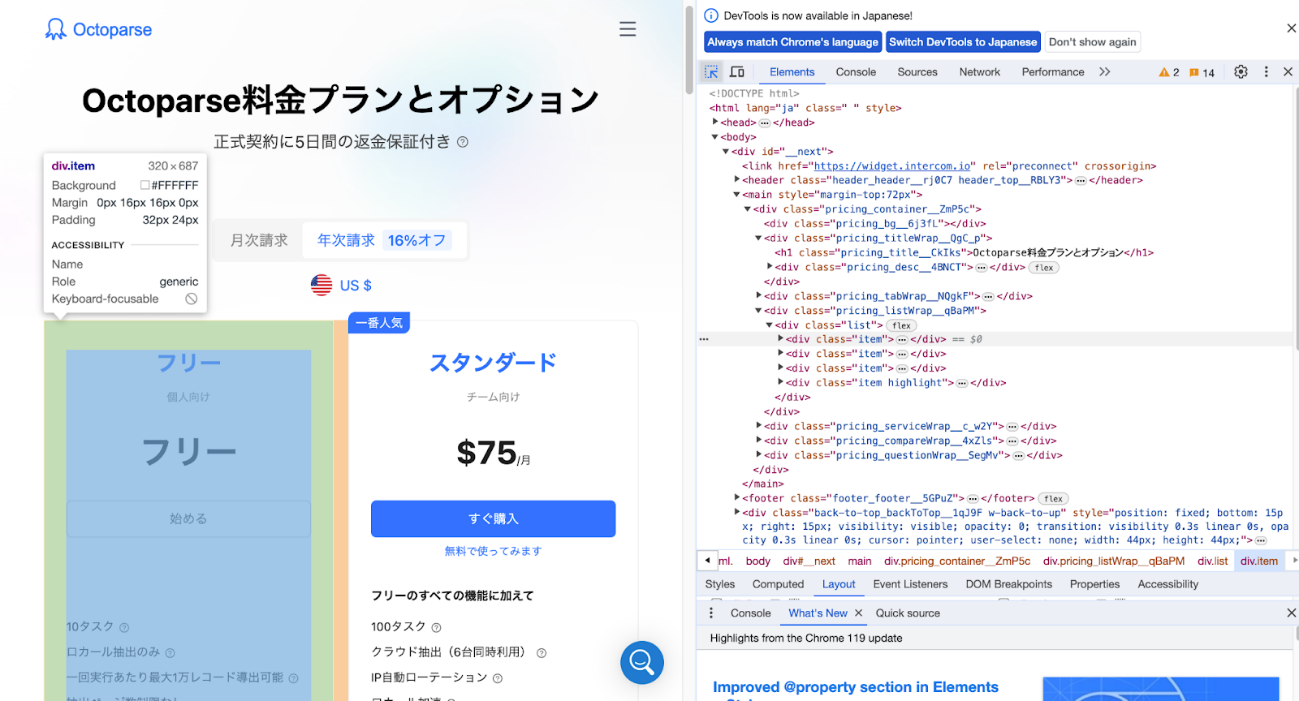
手順1:取得したい要素を検証する
- XPathを取得したいWebページをChromeで開きます。
- 対象のテキスト、画像、ボタンなどを右クリックします。
- メニューから「検証」を選択します。
WindowsではF12またはCtrl + Shift + I、MacではCommand + Option + Iでも開発者ツールを起動できます。
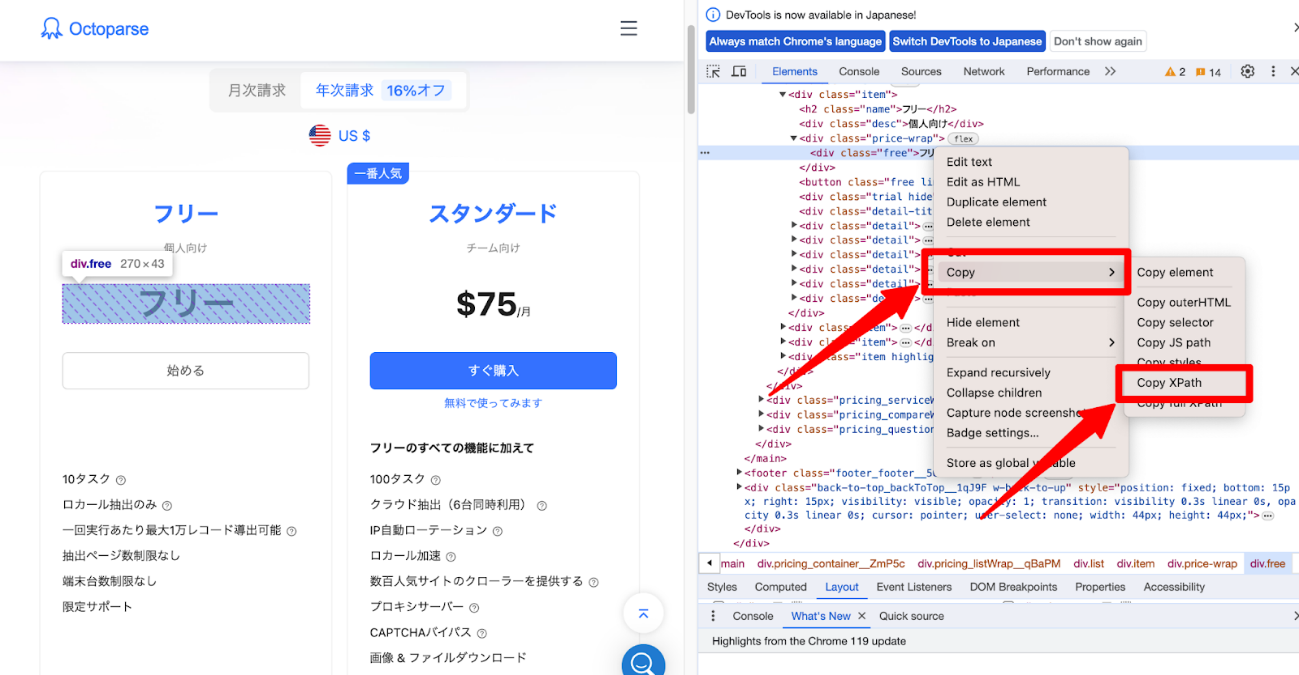
手順2:「Copy XPath」を選択する
- Elementsパネルで、選択されたHTML要素を右クリックします。
- 「Copy」から「Copy XPath」を選択します。
これでクリップボードにXPathがコピーされます。Chrome XPath取得の操作自体は簡単ですが、自動生成されたXPathがスクレイピングに最適とは限りません。コピー後に必ず動作と安定性を確認しましょう。
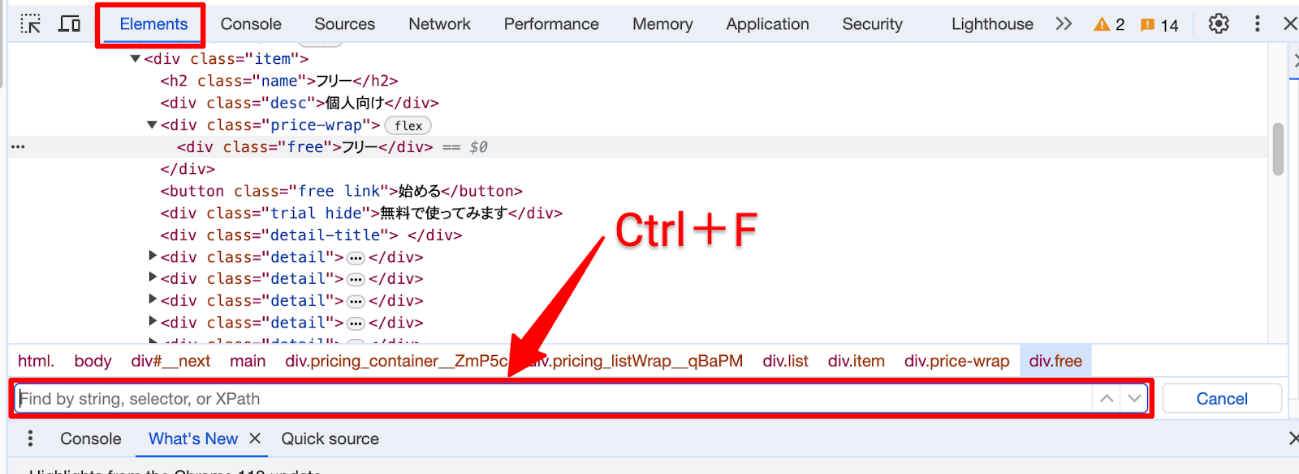
手順3:取得したXPathを検証する
- Elementsパネルを選択した状態で、Windowsは
Ctrl + F、MacはCommand + Fを押します。 - 検索欄にコピーしたXPathを貼り付けます。
- 一致件数とハイライトされた要素を確認します。
対象が1件だけなら1 of 1のように表示されます。Chrome DevToolsのElementsパネルでは、文字列だけでなくCSSセレクタやXPathによる検索も可能です。詳しい操作はChrome Developersの公式ドキュメントでも確認できます。
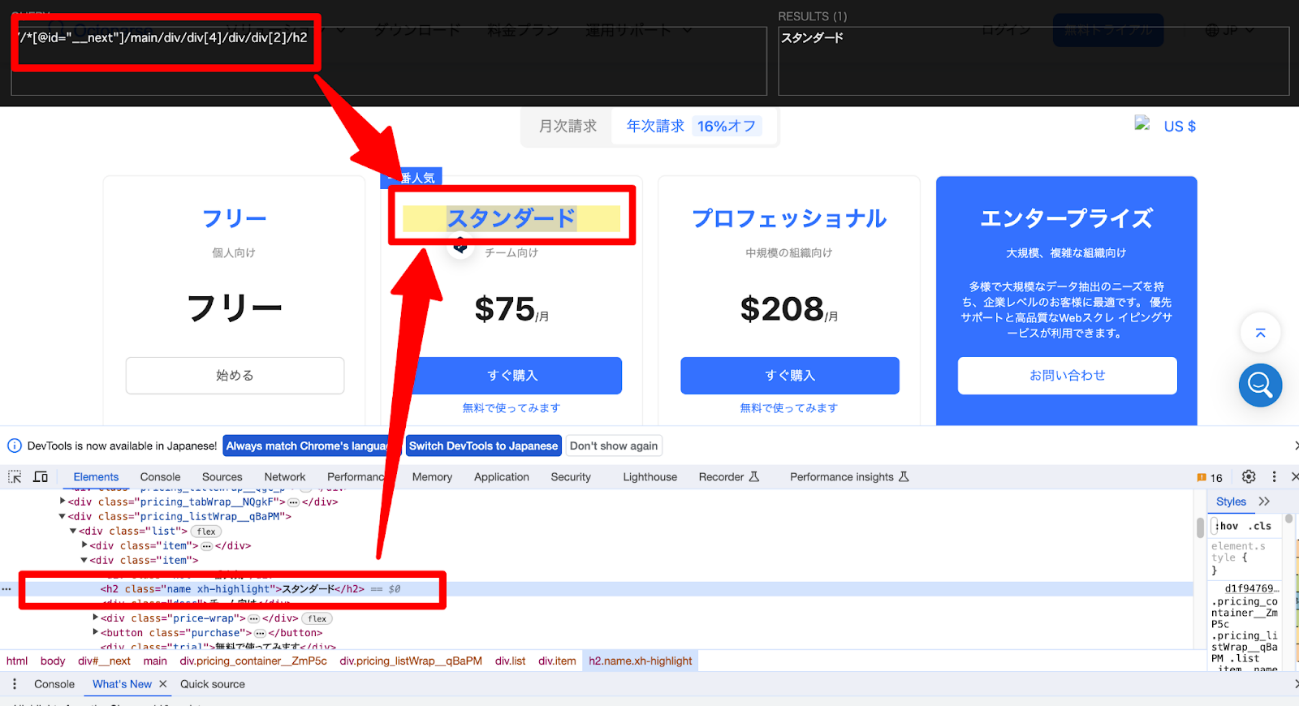
Chromeで取得したXPathをそのまま使う際の注意点
「Copy XPath」で生成される式には、/html/body/div[2]/...のような長い絶対XPathや、位置番号に強く依存する式が含まれることがあります。この形式は、広告やバナーの追加、レイアウト変更などで階層がずれると機能しなくなる可能性があります。
コピーしたXPathは完成品ではなく、対象要素を見つけるための出発点と考えましょう。安定した属性がある場合は、次のような相対XPathへ短く修正するのがおすすめです。
Chromeが生成した長いXPathの例
属性を使って短くした例
拡張機能でXPathを取得する方法
XPathを繰り返し取得・検証する場合は、XPath HelperなどのChrome拡張機能も利用できます。ただし、拡張機能には閲覧中ページへのアクセス権限が必要になる場合があります。提供元、権限、更新状況を確認したうえで導入してください。
XPathの書き方:基本構文と具体例
ここからは、実務でよく使うXPathの書き方を、タグ・属性・テキスト・要素同士の関係に分けて解説します。
1. タグ名で指定する
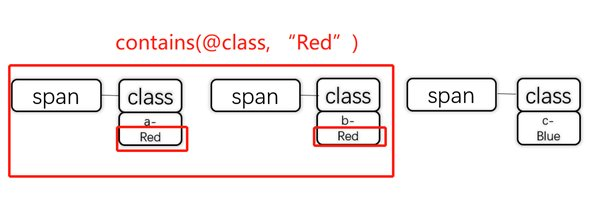
もっとも基本的な書き方は、タグ名を使って要素を指定する方法です。例として、次のHTML構造を見てみましょう。
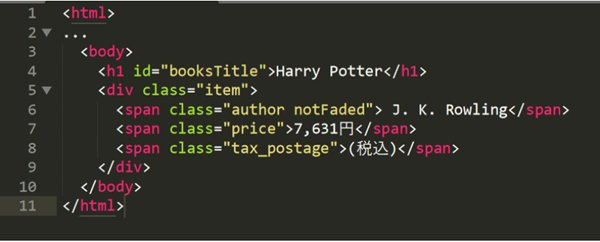
この例では、書籍タイトル「Harry Potter」が<h1>タグ内に記載されています。ツリー図で示すと次の通りです。
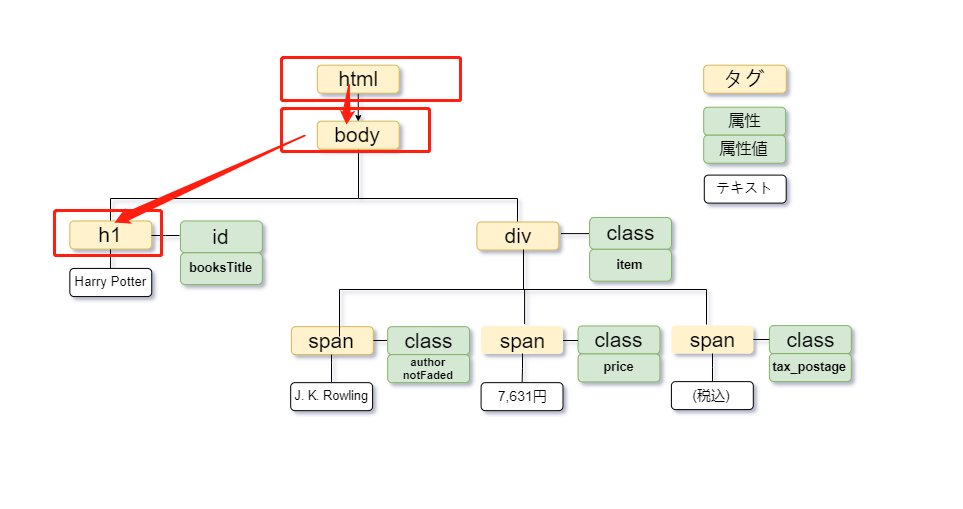
タイトルをルートから順にたどる絶対XPathは、次のように記述します。
相対XPathで指定する場合は、次のように記述します。
同じ階層に複数の<span>タグがあり、2番目の「7,631円」を取得する場合は、角括弧で位置を指定します。
位置番号はHTMLの追加・削除で変わりやすいため、識別できる属性がある場合は属性指定も検討しましょう。
2. idやclassなどの属性で指定する
属性を条件にする場合は、タグ名[@属性名="属性値"]と書きます。タグ名を限定しない場合は、//*[@属性名="属性値"]と記述できます。
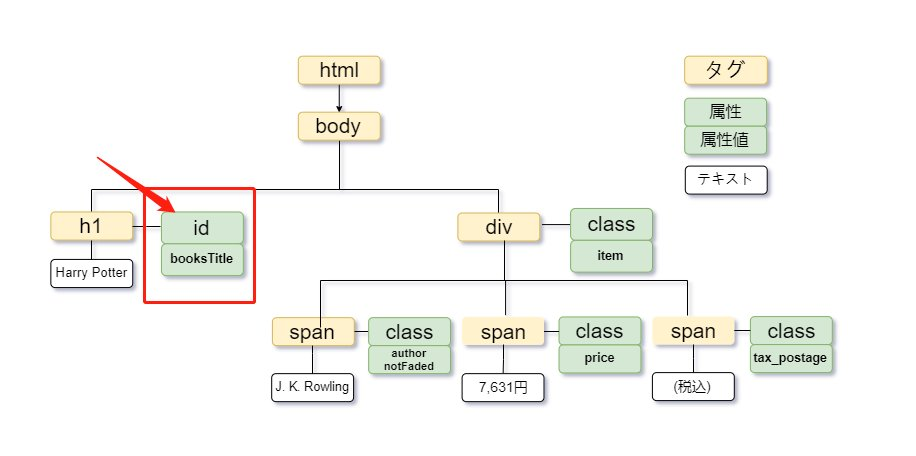
画像の例では、書籍タイトル「Harry Potter」の<h1>タグに、booksTitleというid属性が設定されています。XPathは次の通りです。
idはページ内で一意に設定されることが多いため、有力な手掛かりです。意味が明確なdata-*属性なども、安定したXPathを作る際に役立ちます。
3. テキスト内容で指定する
表示テキストが安定している場合は、text()を条件にできます。基本構文は次の通りです。
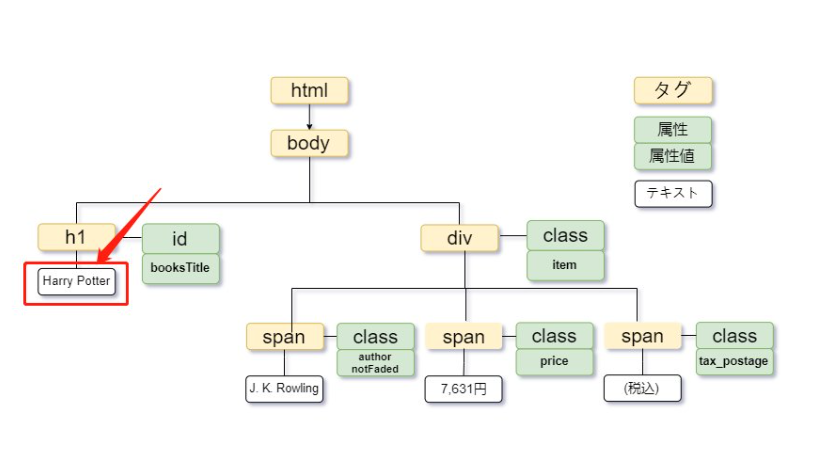
画像の「Harry Potter」というテキストを完全一致で指定する場合は、次のように記述します。
ただし、改行や前後の空白が含まれていると完全一致しない場合があります。実務では、前後の連続する空白を整理して比較できるnormalize-space()が便利です。
文言の一部だけが共通している場合は、contains()と組み合わせます。
4. 親子・兄弟関係で指定する
目的の要素自体に使いやすい属性がない場合は、ラベルなどの関連要素を起点にできます。
| 目的 | XPathの例 |
|---|---|
| 親要素を取得 | //h1[@id='booksTitle']/.. |
| 子要素を取得 | //div/span[2] |
| 子孫要素を取得 | //body//span[2] |
| 直後の兄弟要素を取得 | //span[@class='author notFaded']/following-sibling::span[1] |
| 直前の兄弟要素を取得 | //span[@class='tax_postage']/preceding-sibling::span[1] |
たとえば、商品名の直後に価格が配置されている構造なら、商品名を起点にfollowing-siblingで価格を取得できます。レイアウト上の位置ではなく、要素同士の意味的な関係を使える点がXPathの強みです。
よく使うXPath関数・条件式
contains():部分一致で指定する
contains()は、属性値やテキストに特定の文字列が含まれる要素を選択します。基本構文はcontains(対象, "部分文字列")です。
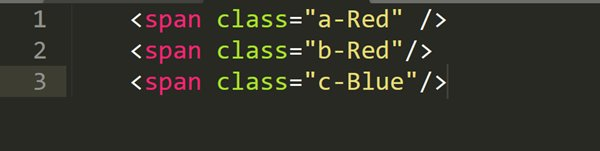
画像の例から、class属性に「Red」を含む<span>タグを取得する場合は、次のように記述します。
このXPathは、class属性の値に「Red」が含まれるすべてのspanタグを対象とします。画像の例では、1つ目と2つ目のspanタグが該当します。
また、先ほどのHarry PotterのHTML例のように、class属性に複数の値が設定されている場合にも有効です。
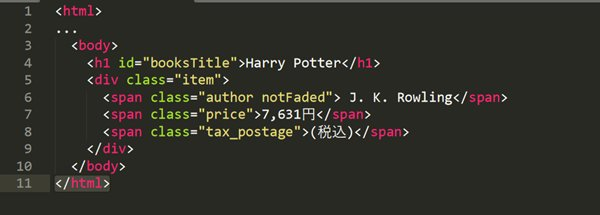
class属性に「author」を含むspanタグを指定するXPathは、次の通りです。
部分一致は便利ですが、短すぎる文字列を条件にすると意図しない要素まで一致します。一致件数を確認し、必要に応じてタグ名や別の条件を追加してください。
starts-with():先頭一致で指定する
属性値の先頭に一定の規則がある場合は、starts-with()を使えます。
position()・last():位置で指定する
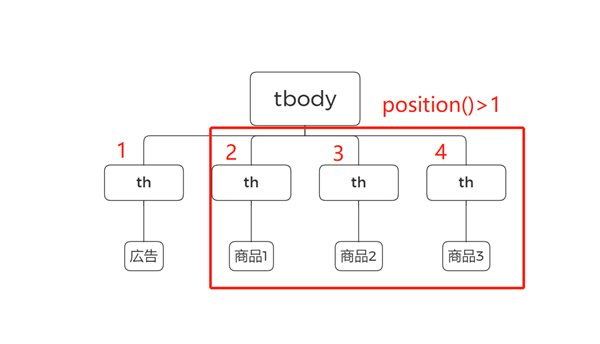
同じタグが繰り返されるリストやテーブルでは、位置を条件にできます。次の画像では、<tbody>内に4つの<th>タグがあります。
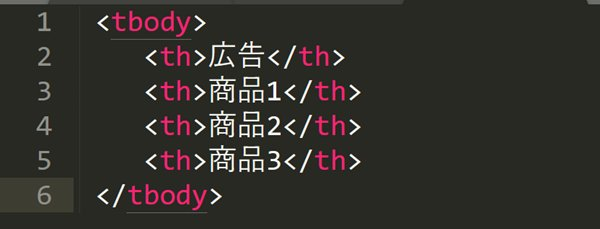
先頭の「広告」を除外し、「商品1」「商品2」「商品3」だけを取得する場合は、次のように記述します。
このXPathは、<tbody>直下にある<th>タグのうち、2番目以降の要素をすべて取得します。
特定の位置や範囲を指定する場合は、次のように使い分けます。
and・or・not:複数条件を組み合わせる
条件式を組み合わせることで、対象をより正確に絞り込めます。
and:両方の条件を満たす要素
not:特定条件を満たさない要素
or:いずれかの条件を満たす要素

XPathの書き方早見表
| やりたいこと | XPath |
|---|---|
| すべてのh1要素 | //h1 |
| 特定のidを持つ要素 | //*[@id='booksTitle'] |
| 特定のclassを含む要素 | //*[contains(@class, 'author')] |
| 特定のテキストと一致する要素 | //*[normalize-space()='Harry Potter'] |
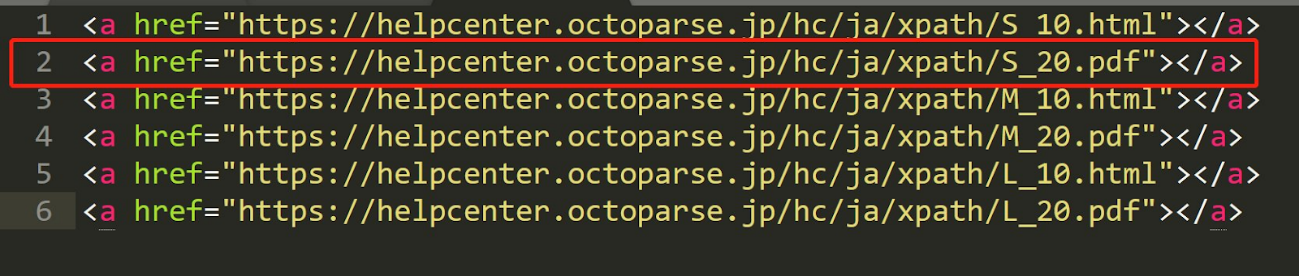
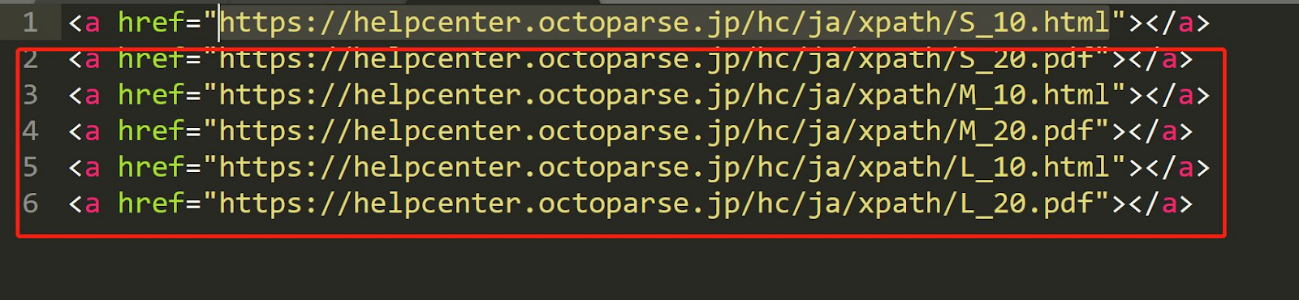
| hrefに特定文字列を含むリンク | //a[contains(@href, 'S_20')] |
| 2番目のth要素 | //tbody/th[2] |
| 最後のth要素 | //tbody/th[last()] |
| 親要素 | //h1[@id='booksTitle']/.. |
| 直後の兄弟要素 | //span[@class='author notFaded']/following-sibling::span[1] |
壊れにくいXPathを書く7つのコツ
- 長い絶対XPathを避ける:途中の階層が変わると動かなくなるため、相対XPathを基本にします。
- 安定した属性を優先する:
id、意味のあるname、aria-label、data-*属性などを確認します。 - 自動生成されたclass名に依存しすぎない:ランダムな文字列やビルドごとに変わるclass名は避けます。
- 位置番号を最小限にする:
div[4]のような指定は、要素の追加でずれやすくなります。 - 条件を増やしすぎない:長く複雑な式は読みづらく、修正も難しくなります。
- 複数ページで検証する:商品ページや一覧ページを数件確認し、テンプレートの違いに対応できるか試します。
- 0件と複数件の両方を確認する:対象が必ず1件とは限りません。期待する取得件数になっているか検証します。
理想的なXPathは、単に短い式ではありません。対象を正しく一意に指定でき、ページ更新後も壊れにくく、あとから読んで意図がわかる式を目指しましょう。
XPath取得がうまくいかない主な原因
動的に読み込まれる要素
JavaScriptの実行後に表示される商品一覧やレビューは、ページの初期HTMLに存在しない場合があります。ブラウザ上で見えていても、スクレイピング開始時点ではまだ生成されていない可能性があるため、待機時間やスクロール、クリック操作の設定が必要です。
iframe内の要素
対象が<iframe>内にある場合、外側の文書から同じXPathで直接取得できないことがあります。まずiframeへ切り替えてから、その内部でXPathを評価する必要があります。
Shadow DOM内の要素
Web Componentsで使われるShadow DOMは、通常のXPath検索では境界を越えられない場合があります。利用するスクレイピングツールがShadow DOMに対応しているか確認してください。
属性やテキストが毎回変わる
セッションごとに変わるid、ユーザーごとに変わる文言、在庫状況によって変化するclassなどを完全一致で指定すると、取得に失敗します。共通部分を使う、親要素を起点にする、複数条件を組み合わせるといった修正が有効です。
OctoparseでXPathを使ってデータを取得する方法
Octoparseでは、ページ上の要素をクリックして抽出項目を選択できるため、XPathをゼロから書かなくてもWebデータを取得できます。自動認識された範囲が広すぎる、または目的の要素を正しく選択できない場合は、XPathを編集して対象を絞り込めます。
- 対象ページのURLを入力してページを読み込みます。
- 取得したい商品名、価格、リンクなどをクリックします。
- プレビューで抽出結果と件数を確認します。
- 必要に応じて要素のXPathを相対XPathへ修正します。
- 複数ページでテストしてからタスクを実行します。
XPathの基本を理解しておくと、クリック操作だけでは選びにくい要素にも対応しやすくなり、タスクの保守性も高められます。
XPathに関するよくある質問
XPathとは何ですか?
XPathとは、XMLやHTMLのツリー構造から特定の要素や属性を指定するための言語です。Webスクレイピング、ブラウザ自動化、Webテスト、XML処理などで使われます。
ChromeでXPath取得するにはどうすればよいですか?
対象要素を右クリックして「検証」を選び、Elementsパネル内の該当要素を右クリックします。その後、「Copy」→「Copy XPath」を選択するとXPathを取得できます。取得後はCtrl + FまたはCommand + Fで検索し、対象が正しく一致するか確認してください。
XPathの取得方法はブラウザによって違いますか?
開発者ツールの名称やメニュー構成はブラウザによって異なります。Chromeでは「Copy XPath」を利用できますが、取得した式はブラウザ任せにせず、使用するスクレイピングツール上でも検証することが重要です。
Chrome XPath取得でコピーした式が長いのはなぜですか?
Chromeが要素の位置を確実に示すため、ルートから階層をたどる絶対XPathを生成することがあるためです。長い式はページ構造の変更に弱いため、安定した属性を使った相対XPathへ短くできないか確認しましょう。
XPathが0件になる場合はどうすればよいですか?
スペル、大文字・小文字、引用符、属性値、テキスト内の空白を確認します。それでも一致しない場合は、対象が動的コンテンツ、iframe、Shadow DOMの内部にないか確認してください。
XPathとCSSセレクタはどちらを使うべきですか?
単純なidやclass指定ならCSSセレクタが簡潔です。テキスト、親子関係、兄弟関係を利用したい場合はXPathが適しています。利用するツールの対応状況と、対象ページの構造に合わせて選びましょう。
まとめ
XPathとは、HTMLやXMLのツリー構造から目的の要素を指定するための言語です。基本的なXPathの書き方を覚えれば、タグ、属性、テキスト、親子・兄弟関係を手掛かりに、必要なデータを柔軟に取得できます。
ChromeでのXPath取得方法は、「検証」→「Copy XPath」→検索欄で検証、という3段階です。ただし、コピーした絶対XPathをそのまま使うのではなく、安定した属性を使った相対XPathへ整えることで、Webサイトの変更に強いスクレイピング設定を作れます。
まずはChromeで気になる要素のXPathを取得し、本記事の早見表を参考に短く読みやすい式へ書き換えてみましょう。

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール



