現代のビジネスシーンでは、データを活用したマーケティング活動や戦略立案が求められています。企業はいかに効率的に質の高いデータ収集ができるかが成功の鍵を握るといっても過言ではありません。
そうしたなかで、インターネット上の特定のWebサイトから必要な情報を効率的に収集する手法として「ウェブスクレイピング」が注目されています。ウェブスクレイピングを活用するには、専門的なプログラミングスキルや、高額なツールの導入が必要と感じる方もいるでしょう。
しかし、ウェブスクレイピングツールの中には、プログラミング不要かつ無料で利用できるツールも存在します。本記事では、ウェブスクレイピングの基本から、無料で利用できるおすすめのウェブスクレイピングツールまで詳しく解説します。データ収集の効率性を高めたいとお考えの方は、ぜひ参考にしてください。
ウェブスクレイピングとは
ウェブスクレイピングは、インターネット上のウェブサイトから情報を自動で収集する技術です。主にプログラムを用いて、ウェブページからデータを抽出し、有用な形で保存する過程を指します。これにより、手動でのデータ収集(コピー&ペースト)に比べて、大幅な時間短縮と効率化が可能になります。
ウェブスクレイピングでできることの例としては、次のようなものが挙げられます。
- 市場調査:競合他社の価格や商品情報を収集し、市場の動向を分析する
- ソーシャルメディア分析:ソーシャルメディア上のコメントや評価数を収集する
- 営業リスト生成:ポータルサイト上に記載されている企業情報をもとに営業リストを作成する
- ニュース収集:複数のニュースソースから最新情報をリアルタイムで集計する
- 求人情報収集:求人サイトから求人情報を収集し、地域や業界の賃金相場を調査する
ウェブスクレイピングは、これらの情報収集を自動化することで、企業の営業担当者やマーケターの効率的なデータ活用を支援します。
ウェブスクレイピングの仕組みは
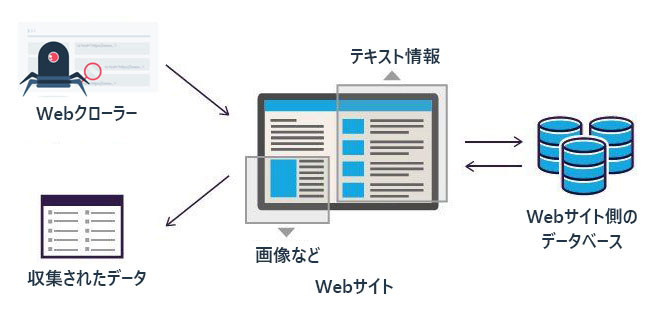
ウェブスクレイピングは、Webサイトから情報を自動的に取り出すための方法です。このプロセスはいくつかのステップに分けて実行され、それぞれの段階で特定の技術が使用されます。ここでは、それぞれのステップを簡単に説明します。
- ウェブサイトの選定:まず、情報を取得したいウェブサイトを選びます。このステップでは、特定の目的に合った内容が豊富に含まれているサイトを選ぶことが重要です。
- 情報の取得:選定したウェブサイトにWebクローラーを使ってアクセスし、ページの内容(文章や画像など)を読み込みます。Webクローラーとは、自動的にウェブサイト内を巡り、必要なデータを集めるためのコンピューターボットのことです。
- データの抽出:読み込んだページから必要な情報だけを選び出します。ここでの情報には、Webサイト内のテキスト情報、画像、リンクなどが含まれます。例えば、商品の価格や詳細、記事の内容など、目的に応じたデータを抽出します。
- データの整理:選び出した情報を使いやすい形に整えます。たとえば、表にしたり、リストにしたりすることで、データの見やすさとアクセスのしやすさを向上させます。
- データの保存:最後に、整理したデータをデータベースに保存します。これにより、後でいつでもデータにアクセスできるようになり、情報の再利用が容易になります。
ウェブスクレイピングの仕組みをさらに詳しく知りたい方は、こちらの記事もあわせてご覧ください。
ウェブスクレイピングツールの選び方
ウェブスクレイピングツールを選ぶ際には、自社のニーズに合ったツールを見つけることが重要です。選択する際のポイントとして、OSの互換性、クラウド対応、機能性、サポート体制、そして価格が挙げられます。ここでは、それぞれのポイントを詳しく解説します。
自社のOSに対応しているか
選ぶウェブスクレイピングツールは、使用しているオペレーティングシステム(OS)に対応している必要があります。なぜなら、OSに対応していないツールを選ぶと、追加のシステム調整やプログラムの変更が必要になることがあり、これには多大な時間とコストがかかるからです。
例えば、自社がMacを使用している場合、Windowsにのみ対応しているツールは利用できません。したがって、OSの互換性を確認することは、ツール選定の初期段階で非常に重要です。
クラウドに対応しているか
クラウド対応のウェブスクレイピングツールを選ぶことは、データアクセスと管理の柔軟性を高めるために重要です。クラウド対応ツールを使用することで、どこからでもデータにアクセスでき、チームメンバー間の共同作業が容易になります。
例えば、クラウドベースのツールを使用することで、外出先からでもプロジェクトの進捗を確認し、データを更新することができます。このため、クラウド対応は現代のビジネス環境において重要な要素となっています。
必要な機能が備わっているか
ウェブスクレイピングツールを選ぶ際には、必要な機能が全て備わっているかを確認することが不可欠です。例えば、動的なウェブサイトからのデータ収集を想定している場合、JavaScriptを実行できる機能が必要です。また、大量のデータを扱う場合は、データの自動処理と整理の機能が充実しているツールが適しています。これらの機能がツールに備わっていることで、スクレイピングの効率が大幅に向上します。
トレーニングやサポートが充実しているか
選ぶウェブスクレイピングツールには、充実したトレーニングとサポートが提供されているかを確認することが重要です。特に複雑な機能を持つツールを使用する場合、適切なトレーニングと技術サポートがなければ、ツールの有効活用が困難になります。
例えば、ユーザーマニュアルが充実していたり、問い合わせに迅速に応じてくれるサポートチームがいる場合、使用中に生じる問題を迅速に解決できます。
価格は予算内に収まるか
ウェブスクレイピングツールの選定において、価格が予算内に収まっているかを検討することも重要です。予算を超えるツールを選ぶと、他の重要な投資がおろそかになる可能性があります。
例えば、ウェブスクレイピングツールによっては無料で利用できるものもあります。低コストのツールを選ぶことで、他のマーケティング活動や戦略立案にリソースを回すことができます。したがって、コストとパフォーマンスのバランスを考慮することが賢明です。
人気のウェブスクレイピングツール10選
次に、どのウェブスクレイビングツールを選べばいいのか、気になるところですよね。 この節では、さまざまなプラットフォームに基づいた無料のウェブクローラーを9個リストアップしました。 中にはソフトウェア型でダウンロードしてインストールする必要がありますが、Webベースの拡張機能やクラウドサービスよりも常に強力な機能を備えています。
以下のリストは、無料または低コストの最高のウェブクローラーであり、ほとんどデータ収集のニーズを満たすことができます。
Octoparse
Octoparse(オクトパス)は、プログラミング知識や専門的なITスキルがなくても使用できるユーザーフレンドリーなウェブスクレイピングツールです。特に、初心者や非技術者にとってアクセスしやすい設計がされています。
Octoparseの特徴は、数クリックでWebページを自動的に構造化されたデータに変換できる点です。コーディング不要で、誰でも簡単にデータ収集を開始できるほか、無料プランから利用できるため、ウェブスクレイピング初心者におすすめです。
<特徴>
- AI機能の統合: 自動検出機能により、ユーザーはより速く、効果的にスクレイピングを始めることができます。
- 高度な自動化:24時間365日運用可能なクラウドソリューションを提供し、データ収集の効率を最大化します。
- 多彩なデータ取得オプション:IPローテーション、CAPTCHA解決サポート、プロキシ使用など、高度な機能を備えており、複雑なウェブサイトからもデータを抽出可能です。
- 豊富なスクレイピングテンプレート:人気サイトのテンプレートが100以上備わっており、該当ページのURLを読み込ませるだけでスクレイピングを実行できます。
Octoparseは無料版でも十分な機能を備え、普通のデータ取得要望を全部カバーできます。有料プランの場合は、14日間の無料トライアルも提供しており、全ての機能を試すことが可能です。
ParseHub
ParseHubは、高度なウェブスクレイピング機能を備えた無料のツールで、複雑なウェブサイトからもデータを効率的に抽出することが可能です。 ParseHubの特徴は、インタラクティブなウェブサイトからも容易にデータを取得できる点です。ユーザーはウェブサイトを開き、抽出したいデータをクリックするだけで、簡単にデータ収集を開始できます。
<特徴>
- インタラクティブなウェブサイト対応:JavaScriptやAJAXを利用した複雑なサイトからもデータを収集できます。
- コーディング不要:マシンラーニングによる関係エンジンがページの構造を認識し、ユーザーはコードを書くことなくデータを抽出できます。
- 柔軟なデータ取得:数百万のウェブページからデータを取得し、REST APIを使用してExcelやJSON形式でデータをダウンロードできます。
Import.io
Import.ioは、市場情報の収集を支援するカスタムウェブデータ抽出サービスです。このツールは、複雑なデータ収集ニーズに対応する機能と専門サービスを提供しています。
Import.ioの特徴は、ビジネスの成長を支援するための市場情報を提供し、データ駆動型の意思決定を可能にする点です。直感的なプラットフォームと強力なAPIを備えており、複雑なウェブサイトからも容易にデータを抽出できます。
<特徴>
- カスタマイズ可能なデータ抽出:特定の業界やビジネスニーズに合わせてカスタマイズ可能なデータ抽出オプションを提供します。
- 専門的なサービス:専門のデータ取得サービスを通じて、重要なビジネスデータを確実に入手できます。
- 高度なデータ処理:複雑なデータセットを管理し、精度の高い消費者洞察を提供する高度なデータ処理機能を備えています。
Google chrome「Scraper」
「Scraper」は、Google Chromeの拡張機能で、ウェブページからデータを簡単にスプレッドシートに抽出することができます。XPathに慣れている中級から上級のユーザー向けの簡易的なデータマイニングツールとして設計されています。
Scraperの特徴は、ウェブページから直接データをスプレッドシートに迅速に抽出できる点です。特に、データを手軽にスプレッドシート形式で必要とする場合に重宝するでしょう。
<特徴>
- 簡単な使用感:ウェブページを開いてデータをクリックするだけで、すぐに抽出を開始できます。
- XPathを利用できる:XPathの知識があれば、より具体的かつ詳細なデータ抽出が可能です。
- データのクリップボードへのコピー:抽出したデータをタブ区切り値としてクリップボードにコピーできる機能があります。
Bright Data

Bright Dataは、受賞歴のあるプロキシネットワークと強力なスクレイピングツールを提供する、世界をリードするウェブデータプラットフォームです。
Bright Dataの特徴は、企業が競争優位を築くために必要なデータを提供するための、包括的なソリューションを提供している点です。プロキシネットワーク、データ収集ツール、およびAIを活用した解析機能が含まれ、データドリブンな意思決定を支援します。
<特徴>
- 多様なプロキシオプション:7200万個以上の住宅IPや700,000個以上のISPプロキシを含む広範なプロキシネットワークを提供します。
- 先進のスクレイピング機能:カスタムAPIエンドポイントを使用し、公開Webデータを効率的に収集および解析します。
- 包括的なデータソリューション:リアルタイムで市場動向を捉え、戦略的な意思決定を支援するためのデータセットマーケットプレイスを提供します。
Apify
Apifyは、ウェブスクレイピング、データ抽出、ウェブ自動化ツールを構築、展開、公開するウェブスクレイピングおよびデータ抽出プラットフォームです。Apifyの特徴は、複雑なウェブスクレイピングタスクを簡素化するための多機能プラットフォームを提供する点です。このプラットフォームは、コードテンプレートや1,600以上の既製のツールを利用して迅速にスクレイパーの構築を支援します。
<特徴>
- 多言語サポートとライブラリ:PythonやJavaScriptをはじめとする複数の言語での開発が可能で、Playwright、Puppeteer、Seleniumなどの人気ライブラリと連携します。
- クラウドベースの展開:サーバーレスの「Actor」を使ってコードをクラウドにデプロイし、インフラ、プロキシ、ストレージがすぐに利用可能です。
- 広範なインテグレーション:既製のインテグレーションやAPIを通じて、数百のアプリケーションに簡単に接続できます。
Scrapy
Scrapyは、高速で強力なスクレイピングとウェブクローリングを行うためのフレームワークです。これはオープンソースで、多くの開発者によって維持管理されています。
Scrapyの特徴は、ウェブから必要なデータを抽出するためのシンプルで拡張可能な方法を提供する点です。Pythonで書かれ、Linux、Windows、Mac、BSDで実行可能です。
<特徴>
- 高速で強力:複雑なウェブサイトからも効率的にデータを抽出できるように設計されており、スピーディなデータアクセスを実現します。
- 拡張性の高さ:プラグインの追加が容易で、コアシステムに手を加えることなく新しい機能を組み込むことができます。
- コミュニティのサポート:GitHub、Twitter、StackOverflowなどで活発なコミュニティサポートがあり、豊富なリソースが利用可能です。
Webscraper
Webscraperは、複雑なウェブサイトからデータを抽出するための強力なブラウザ拡張機能です。これは、初心者からプロフェッショナルまでのユーザーに適したツールです。
Webscraper.ioの特徴は、クリックと選択による簡単な操作でスクレイピングを行うことができ、コーディングの知識がなくても使用できる点です。また、クラウドでのスクレイピングのスケジューリングもサポートしています。
<特徴>
- 直感的なインターフェース:要素を指してクリックするだけでスクレイパーを構成でき、ユーザーフレンドリーです。
- JavaScriptサイトの処理:完全なJavaScript実行をサポートし、Ajaxリクエストの完了を待つことができます。
- データのカスタマイズとエクスポート:CSV、XLSX、JSON形式でのデータエクスポートが可能で、異なるサイト構造に合わせたデータカスタマイズも行えます。
Playwright

Playwrightは、モダンなウェブアプリケーションのための信頼性の高いエンドツーエンドテストを実現するツールです。クロスブラウザおよびクロスプラットフォームのテストが可能です。
Playwrightの特徴は、各種ブラウザでの動作をサポートし、Windows、Linux、macOSで実行可能である点です。また、TypeScript、JavaScript、Python、.NET、Javaといった複数の言語で使用できます。
<特徴>
- クロスブラウザ対応:すべてのモダンブラウザエンジンに対応し、一貫したAPIを通じて操作が可能です。
- テストの堅牢性:自動待機機能を備え、要素が操作可能になるまで待機します。これにより、人工的なタイムアウトに起因するテストの不安定さが解消されます。
- 強力なツールセット:テストのコード生成、インスペクタ、トレースビューアを含む豊富なツールを提供し、テストプロセスを支援します。
ScrapingBee
ScrapingBeeは、プロキシとヘッドレスブラウザの管理を行い、データの抽出に集中できるように設計されたウェブスクレイピングAPIです。ScrapingBeeは、複雑なウェブサイトのデータを簡単に抽出できるように、JavaScriptレンダリングやプロキシの自動回転などの機能を提供します。
このAPIは、シングルページアプリケーションなど、JavaScriptに依存するサイトからもデータを取得できます。
<特徴>
- JavaScriptレンダリング:リアルタイムでのウェブページレンダリングをサポートし、動的なウェブアプリケーションからデータを抽出できます。
- プロキシの自動回転:大規模なプロキシプールを活用し、レート制限を回避しながら安全にスクレイピングを行うことができます。
- 簡単なAPIの利用: 複雑な設定を要せず、APIを通じて直感的にウェブスクレイピングを行うことが可能です。
ウェブスクレイピングツールを使う時のポイント
ウェブスクレイピングツールを使用する際には、効果的なデータ収集を行うためにいくつかの重要なポイントを押さえておく必要があります。ここでは、特に注意すべきポイントを詳しく解説します。
データの使用目的を明確にする
ウェブスクレイピングを行う前に、データの使用目的を明確にすることが重要です。目的が明確でないと、必要なデータを適切に選択できず、結果として多くの無関係なデータを収集してしまう可能性があります。
例えば、市場分析を目的とする場合、競合の価格情報や製品の評価データが必要になります。この明確な目的に基づいてスクレイピングの計画を立て、データ収集の範囲と方法を決定します。
法的規制を遵守する
ウェブスクレイピングを行う際には、法的な規制やウェブサイトの利用規約を遵守することが不可欠です。多くのウェブサイトでは、そのコンテンツの無断での商用利用が禁じられており、これを無視してスクレイピングを行うと法的な問題に発展するリスクがあります。
例えば、公開されているAPIを利用するなど、許可されている方法でデータを収集するべきです。また、スクレイピングによってサーバーに過度の負荷をかけないように配慮することも、サイト運営者とのトラブルを防ぐ上で重要です。
ツールの機能を最大限に活用する
利用するウェブスクレイピングツールの機能を最大限に活用することも大切です。多くのツールは、単にデータを抽出するだけでなく、データのクリーニングや整形、保存形式の選択など、さまざまな機能を提供しています。
例えば、抽出したデータを自動的にCSVファイルやデータベースに保存できる機能を利用することで、データの後処理の手間を省くことができます。これにより、スクレイピングプロセス全体の効率が大幅に向上します。
まとめ
今回は、ウェブスクレイピングの基本から、具体的なツールの選び方、そして使用時の重要なポイントまで詳しく解説しました。ウェブスクレイピングは、現代のデータドリブンな意思決定に不可欠な技術です。
ウェブスクレイピングの仕組みを理解し、適切なツールを選定することで、効率的かつ効果的にウェブから価値あるデータを収集することが可能です。またOctoparseのようなウェブスクレイピングツールを使えば、データを抽出したいウェブページのURLを貼り付けるだけで、かんたんにデータ収集を行えます。
これからウェブスクレイピングを試してみたいという方は、ぜひOctoparseでスクレイピングの有用性を体験してみてください。




