「Webスクレイピングって何?プログラミングできなくても使えるの?」「実際にどんな業務で役立つの?」— そんな疑問を持つ方のために、この記事では基礎から実装方法・活用事例・法的注意点まで、ひとつの記事でまとめて解説します。
データドリブン経営が当たり前になった今、Webスクレイピングはビジネスの現場で欠かせないスキルのひとつです。実際、世界600万人以上のユーザーがOctoparseを使ってデータ収集を自動化しています。プログラミング不要のノーコードツールを使えば、エンジニアでなくても今日から始められます。
本記事では、ウェブスクレイピングの基本や仕組みからメリット・デメリット、さらに活用事例までを詳しく解説します。ウェブスクレイピングの理解を深め、ビジネスシーンに役立ててください。
スクレイピングとは?
Webスクレイピングとは、インターネット上に公開されているウェブサイトから特定の情報を自動的に収集・加工するコンピューター技術です。英語の「scraping(こすり取る)」に由来し、Web上のテキスト・価格・画像などのデータを「こすり取るように」自動抽出するイメージです。
例えるなら、図書館の本棚から必要な本を一冊ずつ手で取り出す作業を、ロボットが瞬時に行うようなものです。この技術を使えば、人間が何日もかけてコピー&ペーストしていたデータ収集作業を、数分〜数時間で完了させることができます。取得したデータはCSV・Excel・JSONなどの形式で出力でき、そのままビジネス分析や営業リスト作成、価格モニタリングなどに活用できます。
ここでは、ウェブスクレイピングの基本概念や仕組みをわかりやすく解説します。
データ収集・加工の定義と基本概念
ウェブスクレイピングの仕組みは、ウェブサイト上に公開されている情報を収集し、それを利用可能な形式に変換するというものです。
例えば、ニュース記事のタイトル、ECサイトの商品価格など、特定のデータだけを抜き出し、CSVやExcelなどのデータベース形式に変換してくれます。それにより、さまざまなデータ分析やリスト作成、戦略立案に利用できます。
ウェブスクレイピングはプログラムによって自動実行されるため、手動に比べて圧倒的に短時間で大量のデータを収集することが可能です。さらに、データの転記ミスも防ぐため、精度の高い情報収集を実現します。
したがって、ウェブスクレイピングは単なる情報収集の手段ではなく、その加工まで含めて業務効率化や意思決定に役立つコンピューター技術です。
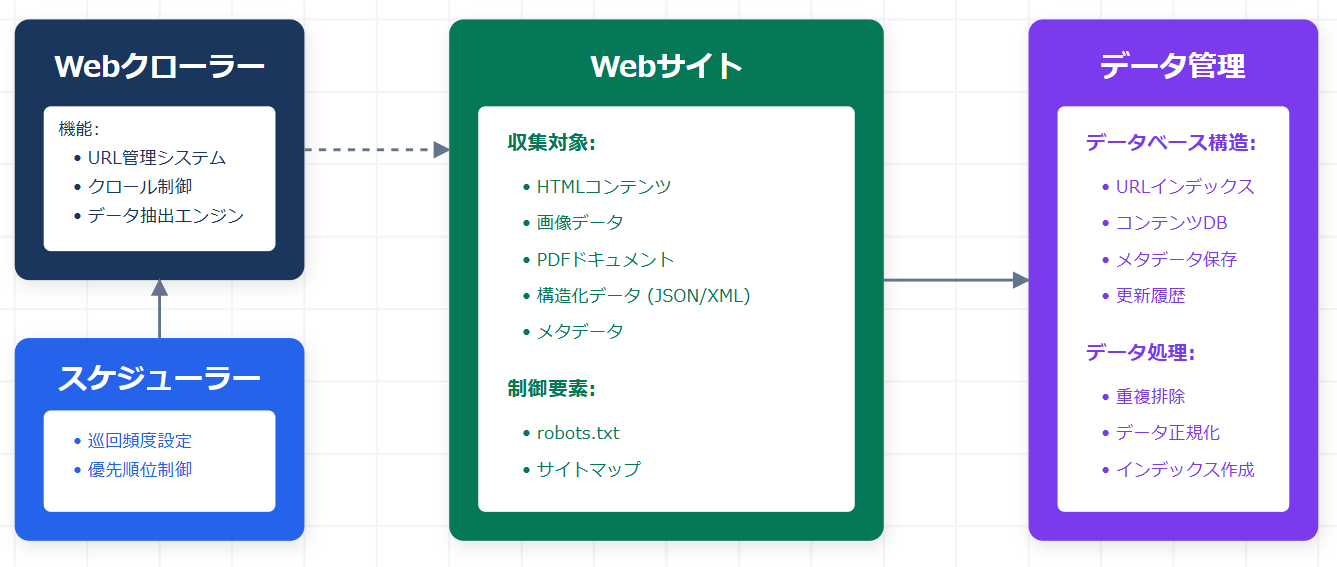
スクレイピングを支えるWebクローラーとWebスクレイパーとは
Webスクレイピングは「Webクローラー」と「Webスクレイパー」の2段階のプロセスで動作します。これはちょうど「探偵が証拠を集めてくる係(クローラー)」と「集めた証拠を整理・分析する係(スクレイパー)」のような分業関係です。
▶ Webクローラー(巡回役):
インターネット上のリンクをたどりながらページを自動巡回し、データを収集するプログラム。Googleの検索エンジンも同様の仕組みで動作しています。
※詳細は「Webクローラーとは?構築方法と仕組み」で解説しています。
▶ Webスクレイパー(抽出役):
クローラーが訪問したページのHTML構造を解析し、必要なデータのみを取り出すプログラム。CSSセレクタやXPathと呼ばれる指定方法で、欲しいデータをピンポイントで取得します。
この2つが連携することで、「Amazonの商品価格だけを毎日自動収集する」「Linkedinの求人情報をCSVに一括出力する」といった処理が可能になります。
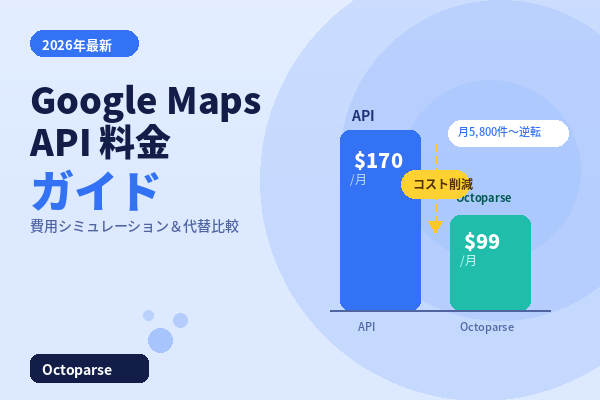
スクレイピングとAPIの違いとは
WebスクレイピングとAPIはどちらもWebからデータを取得する方法ですが、大きな違いがあります。「APIが用意されていない情報を取得したい」「公開されているあらゆるデータを柔軟に収集したい」という場面では、Webスクレイピングが強力な手段になります。
APIとは
API(アプリケーションプログラミングインターフェース)は、データ提供者が公式に用意したプログラム間の通信手段です。APIを用いることで、ユーザーは事前に決められた形式でデータを安定的かつ効率的に取得することができます。
一般的にAPIを利用するには事前登録や認証が求められますが、その分データ取得の信頼性と一貫性が担保されています。例えば、天気情報や為替レートなどのデータを取得する際、APIを使用すると簡単に最新の情報を取得できます。
また、APIは取得可能なデータの範囲や更新頻度が明確であり、サーバーへの負荷をかけるリスクも最小限に抑えられるため、運用上の安全性が高いのもメリットです。一方で、APIは取得するデータが限られており、柔軟性に乏しい点がデメリットとして挙げられます。
WebスクレイピングとAPIの比較
| 項目 | Webスクレイピング | API |
|---|---|---|
| データソース | 公開されているほぼすべてのWebページ | APIが提供するデータのみ |
| 柔軟性 | 高い条件・形式を自由に指定 | 低い提供フォーマットに依存 |
| 安定性 | 要注意(サイト構造変更の影響を受ける) | 安定公式サポートあり |
| 事前認証 | 不要(公開情報の場合) | 必要APIキーなど |
| 法的リスク | 要確認(利用規約の確認が必要) | 低い(公式提供のため) |
スクレイピングのメリット
ウェブスクレイピングは、ウェブサイト上の情報を効率的かつ自動的に収集する技術として、ビジネスシーンや研究分野で多く利用されています。
ウWebスクレイピング自体に違法性はなく、むしろ公共機関でも積極的に活用されています。例えば、日本の総務省は2019年から消費者物価指数(CPI)の調査にWebスクレイピングを正式採用しており、ILO(国際労働機関)など国際機関でも標準的なデータ収集手段として認識されています。(参照:総務省「消費者物価指数へのウェブスクレイピングの活用について」)
ここでは、ウェブスクレイピングがもたらす具体的なメリットについて詳しく解説します。
データ収集の効率化
ウェブスクレイピングの最大の利点の一つは、データ収集の効率化です。この技術を活用すれば、人が手作業で情報を集めるのに要する膨大な時間と労力を大幅に削減することができます。
例えば、マーケット調査や競合分析のために複数のウェブサイトから情報を収集する場合、手作業では何日も掛かってしまいますが、ウェブスクレイピングを用いれば、数分から数時間程度で完了できます。
さらに、自動化されたデータ収集は精度が高く、転記ミスなどのヒューマンエラーもありません。これにより、収集した情報を安心して分析や意思決定に活用することが可能です。効率的なデータ収集によって、担当者の業務負荷を軽減し、より専門性が求められる業務に専念できます。
最新の情報をリアルタイムに取得
ウェブスクレイピングを定期的に実行することで、常に最新情報を手に入れることができます。例えば、ECサイトに掲載されている他社製品の価格モニタリングや、求人情報サイトに掲載されている平均賃金を把握することが可能です。
その他にも、株価のリアルタイムモニタリングなど、即時性が求められるデータを効率的に収集できます。それにより、戦略の見直しや迅速な意思決定を支援します。
カスタマイズされたデータの取得
ウェブスクレイピングは、特定の条件やニーズに応じたカスタマイズされたデータの取得を可能にします。例えば、特定の地域における商品価格や、特定キーワードに関連するニュース記事など、柔軟な情報収集が可能です。
必要なデータだけを収集できるため、データ整理に掛かる手間を減らし、効率的な分析や意思決定が可能になります。こうして得られた精度の高いデータは、ビジネスの成果向上や研究の信頼性向上に貢献するでしょう。
スクレイピングのデメリット
ウェブスクレイピングには多くのメリットがありますが、注意すべきデメリットも存在します。ここでは主なデメリットをいくつか解説します。
初心者には技術的に障壁が高い
【プログラミングが必要な場合】BeautifulSoupやSeleniumなどのPythonライブラリを使う方法は、技術的なスキルを必要とします。特に、JavaScriptで動的にコンテンツを生成するサイトや、ログインが必要なサイトでは、さらに高度な知識が求められます。
【ノーコードツールで解決】ただし、OctoparseのようなノーコードWebスクレイピングツールを使えば、プログラミング不要でデータ収集を始められます。視覚的な操作画面で「取りたいデータをクリックするだけ」で設定が完了するため、初心者でも最短5分でデータ収集を開始できます。
対象サイトのサーバーに負荷が掛かる
ウェブスクレイピングは多くの場合、短時間に大量のリクエストを送るため、対象のウェブサイトに過度の負荷をかけるリスクがあります。これにより、対象ウェブサイトがスクレイピングをブロックしたり、法的措置を取ったりする可能性もあります。
こうしたリスクを軽減するためには、適切なリクエスト間隔を設定したり、負荷を分散するためにプロキシを利用するなどの工夫が必要です。また、対象のウェブサイトの運営方針を事前に確認し、運用ポリシーに反しない形で利用することが求められます。
関連記事:
ウェブスクレイピングの活用事例
ウェブスクレイピングは、さまざまな分野でその強力なデータ収集能力が活用されています。特に、効率的かつ自動化された方法で情報を取得し、それをビジネスや研究活動に役立てることができる点が特徴です。ここでは、具体的な活用事例をご紹介します。
製品価格調査
ウェブスクレイピングは、競合商品の価格をリアルタイムで把握する上で効果を発揮します。例えば、ECサイトを運営する場合、競合他社の製品価格情報を収集することで、適切な価格に設定できます。
これにより、収益の最大化や顧客満足度の向上につながります。また、価格の変動パターンを分析することで、需要や市場の動向を理解しやすくなるでしょう。
| Amazonテンプレート(コレクション) https://www.octoparse.jp/template/amazon-jp-product-listings-scraper 取得可能なデータ(主要フィールド): • 商品名(Product Title) • 価格(Price / Discounted Price) • レビュー評価(Star Rating) • レビュー件数(Number of Reviews) • ASIN(商品ID) • 販売者名(Seller Name) • 在庫状況(Availability) • 商品カテゴリ(Category) • 商品画像URL |
市場調査
ウェブスクレイピングは、業界や市場のトレンドを把握することが可能です。例えば、ソーシャルメディアやニュースサイトからユーザーの意見や反応を抽出することで、新しい市場のニーズや潜在的な課題を明らかにできます。さらに、競合他社のマーケティング戦略や新商品情報を収集することで、自社の戦略を最適化するためのデータを得ることが可能です。
活用事例:競合調査とは?やり方・フレームワークからAI×Octoparseによる自動化まで
不動産データ分析
不動産業界では、ウェブスクレイピングを利用して物件情報を収集し、市場動向を分析するケースが増えています。
例えば、不動産ポータルサイトから物件の価格や所在地、設備の情報を取得することで、顧客に最適な提案を可能にします。また、過去の不動産価格データを分析することで、将来的な価格動向の予測にも活用できます。
| SUUMO 戸建て物件リスト https://www.octoparse.jp/template/suumo-detached-house-listing-scraper 取得可能なデータ(主要フィールド): • 物件名(Property Name) • 所在地(Address) • 価格(Price) • 専有面積(Floor Area m²) • 間取り(Floor Plan: 1LDK等) • 築年数(Age of Building) • 最寄り駅・徒歩分数(Nearest Station) • 管理費・修繕積立金 |
リード(見込み客)情報収集
ウェブスクレイピングは、見込み客の情報収集にも有効です。特定の属性を持つ顧客データを抽出することで、営業活動やマーケティングキャンペーンに役立てることができます。
例えば、Googleマップに掲載されている企業の店舗名・電話番号・業種などの公開情報を収集することで、効率的な営業リスト作成が可能です。実際にOctoparseのGoogleマップテンプレートを使ったユーザーは、月間1,500万件のデータ取得・商談数2倍という成果を実現しています。
| Google Mapsテンプレート https://www.octoparse.jp/template/google-maps-store-listing-scraper 取得可能なデータ(主要フィールド): • 店舗名(Store Name) • 住所(Address) • 電話番号(Phone Number) • 評価スコア(Rating) • レビュー件数(Number of Reviews) • 営業時間(Business Hours) • カテゴリ(Business Category) • ウェブサイトURL |
※個人が特定できる個人情報の無断収集は、個人情報保護法に抵触する可能性があります。公開情報であっても収集目的・利用方法には十分ご注意ください。
求人情報収集
| ハローワーク / Indeedテンプレート https://www.octoparse.jp/template/hello-work-job-listings-scraper https://www.octoparse.jp/template/indeed-job-listing-scraper-jp-by-keywords 取得可能なデータ(主要フィールド): • 求人タイトル(Job Title) • 会社名(Company Name) • 勤務地(Work Location) • 給与(Salary) • 雇用形態(Employment Type) • 仕事内容(Job Description) • 応募条件(Requirements) • 掲載期間(Listing Period) |
金融機関向けオルタナティブデータ
オルタナティブデータとは、金融機関や投資家が資産運用の際に参考にしているデータの中で、一般的に公開された情報以外のデータを指します。金融機関では、ウェブスクレイピングを活用して、投資判断やリスク評価のためのオルタナティブデータを収集しています。
たとえば、企業のニュースやソーシャルメディアでの評判、不動産価格や経済指標などのデータを取得することで、投資先の状況や市場の動向をより正確に評価できます。このようなデータは、従来の財務情報では得られない新たな洞察を提供します。
ニュース・情報収集
ウェブスクレイピングは、最新のニュースや業界関連の情報を迅速に収集するための有効な手段です。
例えば、特定のキーワードに関連するニュースを自動的に抽出することで、情報収集の効率化が図れます。これにより、市場の変化や競合状況をリアルタイムで把握し、適切な意思決定を支援することが可能です。
ブランドモニタリング
ブランドの評判管理においても、ウェブスクレイピングは重要な役割を果たします。クチコミサイトのレビューやSNS投稿をチェックし、自社製品やサービスに対する情報を収集することで、顧客満足度の向上や課題解決につなげることができます。また、競合ブランドの動向を把握することも可能です。
ビジネスの自動化
ウェブスクレイピングは、データ収集の自動化を通じて、ビジネスプロセスを効率化します。例えば、営業リスト作成に必要なデータを自動で収集・整理することで、手作業の時間を大幅に削減できます。
定期的に情報更新が必要な場合でも、スケジュールを設定しておくことで、自動収集・更新が可能です。これにより、従業員がより専門性が求められる業務に専念でき、生産性向上につながります。
ECサイトの製品価格モニタリング
ウェブスクレイピングを活用すれば、ECサイトの製品価格変動をリアルタイムで追跡できます。これにより、自社製品が競争力を維持できる価格帯にあるかを確認し、必要に応じて迅速に価格調整が可能です。
市場内で自社製品の競争力を保つために、他の出品者の価格や在庫状況を監視する上でも役立ちます。
スクレイピングの実装方法
ウェブスクレイピングを始めるには、プログラミングを活用した実装と、専用ツールを使った方法の大きく2つに分けられます。それぞれメリット・デメリットがあるため、目的やスキルレベルに応じて適切なアプローチを選ぶことが大切です。
Pythonによる実装(基本的なコード例)
Pythonは世界で最も広く使われているWebスクレイピング用プログラミング言語です。主要ライブラリは以下の3種類があり、用途に応じて使い分けます:
- BeautifulSoup:HTMLの解析・静的ページのスクレイピングに最適。初心者向け。
- Scrapy:大規模・高速なクローリングに特化したフレームワーク。中〜上級者向け。
- Selenium / Playwright:JavaScriptで動的に生成されるページに対応。ブラウザ操作が必要な場合に使用。
以下に、BeautifulSoupを用いた基本的なスクレイピングのコード例を示します。この例では、指定したウェブサイトから記事のタイトルを抽出します。
このコードは基本的なものですが、タグやクラスを指定してデータを収集するなど、カスタマイズすることで柔軟に対応できます。Pythonを使ったスクレイピングは、特に技術的なスキルを磨きながら、効率的にデータを収集したい方に適しています。
ご注意:
Webサイトの構造(HTML)が変更されると、スクリプトが動作しなくなる場合があります。robots.txtの確認と適切なリクエスト間隔の設定(最低1秒以上)を忘れずに行いましょう。
スクレイピングツールの活用
プログラミングの知識がなくても、スクレイピングツールを活用すれば簡単にデータ収集を行うことができます。例えば、「Octoparse(オクトパス・オクトパース)」は、ノーコードでウェブスクレイピングを実行できるツールです。これらのツールは、直感的なインターフェースを提供し、ユーザーがクリック操作で収集したいデータを指定できる仕組みを採用しています。
特に、テンプレートを活用すれば、人気のあるウェブサイトからデータを即座に収集することが可能です。さらに、クラウド型のツールでは、大規模なデータ収集やスケジュール設定も可能で、手軽に自動化を実現できます。これにより、技術的な負担を軽減しつつ、効率的に目的のデータを取得することができます。
スクレイピングツールは、時間やリソースを節約しながら、データ収集を迅速に行いたいユーザーに最適な選択肢です。特に、専門的なプログラミングスキルを持たない初心者にとって、非常に有用です。
関連記事:データドリブン営業チームが実践する自動化ワークフロー

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール
Octoparse(オクトパス・オクトパース)の活用
世界600万人以上が選ぶWebスクレイピングツール「Octoparse(オクトパス・オクトパース)」は、ノーコードでありながらプロ品質のデータ収集を実現します。クラウドサービスのため、ソフトウェアをダウンロードしてアカウントを作成するだけで、最短5分でデータ収集を開始できます。
【Octoparse独自の強み】
1. ノーコード操作:ビジュアルなワークフローデザイナーで、クリックするだけでスクレイパーを設計。HTMLやCSSの知識不要。
2. 自動検出機能:URLを入力するだけでOctoparseがスクレイピング設定を自動生成(Auto-detect機能)。設定時間を大幅短縮。
3. 600種以上のテンプレート:Amazon・Google Maps・ハローワーク・食べログなど、日本でよく使われるサイト向けテンプレートを多数収録。
Octoparseのテンプレートとは、スクレイピングの設定がすべて事前に組み込まれた「収集パッケージ」です。コードも設定も不要。URLかキーワードを入れるだけで、すぐにデータ取得を開始できます。

4. クラウド自動実行:スケジュール設定で24時間自動収集。PCをつけたままにする必要なし。
5. MCP対応・AIエージェント連携:2026年対応のMCPプロトコルにより、ChatGPTやClaudeなどのAIエージェントと連携し、収集→分析→活用を一気通貫で実現。6. 無料プランあり:クレジットカード不要でスタート。世界の個人・企業・研究機関が活用中。
ウェブスクレイピングの違法性と注意事項について
ウェブスクレイピングは、多くの場面で有益な技術ですが、その利用には法的および倫理的な注意が必要です。スクレイピングそのものは違法ではないものの、方法や対象によっては問題を引き起こす可能性があります。ここでは、ウェブスクレイピングに関連する法的および倫理的な注意点を網羅的に解説します。
法的リスク|利用規約やデータ保護法を遵守する
ウェブスクレイピングを行う際は、対象サイトの利用規約を確認し、必要に応じて許可を取得することが重要です。利用規約に「スクレイピングを禁止する」と明記されている場合、それを無視する行為は契約違反として問題視される可能性があります。また、著作権やデータベース権が適用されるデータに関しては、その取得が法的に許されているかを慎重に判断しなければなりません。
こうした法的リスクを回避するには、収集するデータの範囲を必要最小限に抑え、法的な基準を守ることが欠かせません。さらに、対象サイトの運営者に事前に相談し、明確な許可を得ることで、トラブルを未然に防ぐことができます。
参考:スクレイピングは違法?ウェブスクレイピングに関する10のよくある誤解!
プライバシー保護|個人情報の取り扱いに注意する
個人情報を含むデータを収集する場合は、プライバシー保護法やGDPRなどの規制を遵守しなければなりません。例えば、名前や住所、メールアドレスといった個人が特定されるデータを収集する場合、その情報が本当に必要であるかを確認することが求められます。
リスクを最小限にするためには、個人情報の収集範囲を制限し、センシティブなデータに特に注意を払う必要があります。また、データ収集の目的を明確にし、取得したデータを第三者と共有する際には、収集対象者の同意を得ることが重要です。
ウェブサイトへの配慮|サーバーの負荷を抑える
スクレイピングによる過剰なリクエストは、対象サイトのサーバーに負荷をかけ、運営者に迷惑をかける可能性があります。このような行為は、運営者からアクセスをブロックされるだけでなく、法的措置を招く恐れもあります。
適切なリクエスト頻度を設定し、リクエストの間隔を調整することで、サーバー負荷を抑えることが可能です。たとえば、1秒に1リクエスト以上送信しないように制御することや、複数のプロキシサーバーを使用して負荷を分散させることが推奨されます。これにより、運営者との良好な関係を保つことができます。
Webスクレイピングを安全・合法に行うための実践チェックリスト
□ 対象サイトの利用規約を確認した(スクレイピング禁止条項がないか)
□ robots.txtの内容を確認し、Disallowされたパスへのアクセスを回避している
□ リクエスト間隔は1秒以上に設定している
□ 個人情報(氏名・メール・住所等)を含むデータは収集していないか確認した
□ 収集データを第三者に無断で公開・販売していない
□ 収集データを自社内のデータ分析目的のみに使用している
※判断に迷う場合は、法律の専門家または対象サイトの管理者に事前に確認することを推奨します。
詳細な法的解説は「スクレイピングは違法?Webスクレイピングに関するよくある誤解」をご覧ください。
よくある質問(FAQ)
Q1. Webスクレイピングは違法ですか?
A. Webスクレイピング自体は違法ではありません。ただし、①対象サイトの利用規約でスクレイピングが禁止されている場合、②サーバーに過度な負荷をかけた場合、③個人情報を無断収集・公開した場合などは、法的問題が生じる可能性があります。詳細は「スクレイピングの法的注意点」を確認してください。
Q2. プログラミングができなくてもWebスクレイピングはできますか?
A. はい、できます。OctoparseのようなノーコードWebスクレイピングツールを使えば、クリック操作だけでデータ収集の設定が完了します。無料プランで今すぐ試すことができます。
Q3. Webスクレイピングで取得したデータは何に使えますか?
A. 競合他社の価格モニタリング、市場調査、営業リスト作成、不動産データ分析、SNSのブランドモニタリング、求人情報収集など、ビジネスの幅広い場面で活用できます。取得データはCSV・Excel・Google Sheetsへの出力も可能です。
Q4. Octoparseはいくらかかりますか?
A. Octoparseはクレジットカード不要の無料プランから始められます。有料プランはビジネス規模に応じて選択可能で、クラウドクロール・スケジュール実行・大量データ取得など高度な機能が利用できます。詳しくは料金ページをご確認ください。
Q5. Webスクレイピングでどのくらいのデータを取得できますか?
A. ツールやプランによって異なりますが、Octoparseのクラウドプランでは大規模なデータ収集にも対応しています。実際のユーザー事例では月間1,500万件以上のデータを収集しています。
まとめ
Webスクレイピングとは、ビジネスデータの収集を自動化し、意思決定を加速させるための強力な技術です。本記事では、その仕組み・メリット・デメリット・活用事例・実装方法・法的注意点をひとつの記事で網羅しました。
まず試してみたい方へ、次のステップをご案内します:
▶ ノーコードで始める → Octoparseを無料ダウンロードして、テンプレートから即スタート
▶ Pythonで学ぶ → BeautifulSoupを使った実装記事でコードから理解を深める
▶ 法律を確認する → スクレイピングの法的グレーゾーンを詳しく理解
するクレジットカード不要・無料プランありのOctoparseで、まず小さく始めてみてください。世界600万人のユーザーが証明する、シンプルで強力なデータ収集を体験してください。
競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール