SEO対策やスクレイピングを行う際には、「robots.txt」への理解が不可欠です。robots.txtは、検索エンジンのクローラーやスクレイピングツールに対して、アクセス可能な範囲を示すファイルです。適切に確認すれば、スクレイピングでは安全かつ効率的なデータ取得が実現し、SEOでは検索エンジンに意図したページだけをクロールさせることで、サイト評価の最適化につながります。
本記事では、robots.txtの基本的な仕組みから具体的な確認方法、記述ルール、さらにSEOやスクレイピングに役立つポイントまでを詳しく解説します。
robot.txtファイルとは?
robots.txtファイルは、検索エンジンのクローラーやスクレイピングツールに対して、Webサイト内のアクセス許可範囲を指定するテキストファイルです。
はじめに、robot.txtの役割やユースケースについて解説します。
robots.txtの役割・機能
robots.txtファイルは、検索エンジンのクローラーや各種ボットに対して、アクセス可能な範囲を伝える役割を持っています。これにより、Webサイトの特定ページへのクロールを防ぐことができます。
例えば、検索結果に表示させたくない内部用のページや、公開前のコンテンツ、さらにはサーバー負荷を考慮してクロール頻度を制限したいケースもあります。
このような状況に対応するのが、robots.txtです。サイト運営者は、このファイルを通じて「ここはクロールしても良い」「ここは避けてほしい」といった指示を出すことができます。
また、スクレイピングを行う側にとってもrobots.txtは重要なガイドラインです。対象サイトのrobots.txtを確認することで、データ取得が許可されている範囲を事前に把握でき、不要なトラブルを避けることができます。
robots.txtのユースケース
robots.txtは、Webサイト運用においてさまざまな場面で活用されています。
- 管理画面・会員専用ページのクロール防止
公開する必要のない管理画面やマイページなどが検索エンジンにインデックスされるのを防ぎます。
- 開発・テスト環境の保護
リニューアル中のサイトや検証用環境が外部に公開されないよう、クローラーのアクセスを制限します。
- 重複コンテンツの制御
ECサイトの商品一覧やブログのタグページなど、同一内容が複数URLで生成される場合にクロール対象を限定し、SEO評価の低下を防ぎます。
- サーバー負荷の軽減
頻繁にアクセスするクローラーに対して、巡回範囲や頻度を制御することで、リソースの消費を抑えます。
このように、robots.txtは単なるクローラー制御にとどまらず、情報管理やパフォーマンス維持、さらにはSEO対策にも利用されています。特に、サイト規模が大きくなるほど、適切なクロール制御が求められます。また、スクレイピングを行う際も、こうした制限が設定されているかを事前に確認することで、ルールを遵守したデータ取得が可能になります。robots.txtの意図を正しく理解し、双方にとって負担の少ない運用を心がけることが重要です。
robots.txtの確認方法
robots.txtは公開ファイルのため、誰でも簡単に確認できます。
ここでは、robots.txtの確認方法を解説します。
<手順>
- robots.txtを確認したいWebサイトに移動する
ブラウザを使って対象サイトのトップページに移動します。
今回は本Webサイト「Octoparse」にアクセスします。
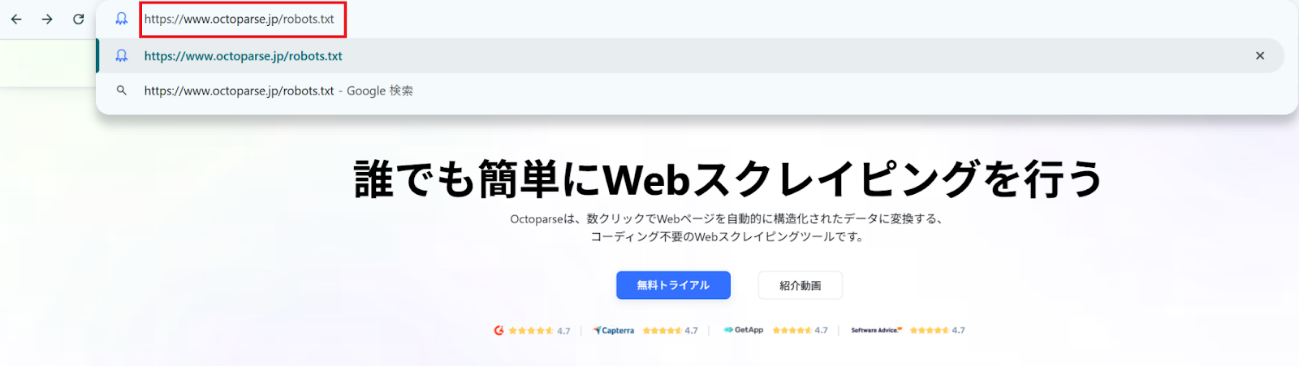
- URLに「/robots.txt」を追加する
対象サイトのトップページURLの末尾に「/robots.txt」を付けてアクセスします。
(例)https://www.octoparse.jp/robots.txt
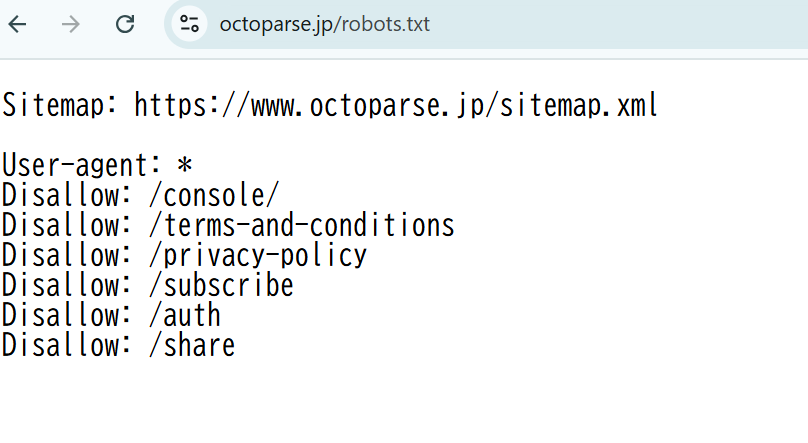
- robots.txtが表示される
以下のように、当Webサイトのrobots.txtが表示されました。
robots.txtは公開情報ですが、常に最新の状態とは限りません。スクレイピングを行う際は、都度確認する習慣をつけることが重要です。
また、記述内容を正しく理解するには、基本的なルールやディレクティブに関する知識が求められます。次章では、robots.txtの構成や書き方について詳しく解説します。
robots.txtの読み方・記述方法
robots.txtの内容を確認した後は、記述ルールを正しく理解することが重要です。この章では、robots.txtの基本構成と各ディレクティブの意味を解説します。
robots.txtの構成要素
robots.txtは、基本的なディレクティブ(命令文)で構成されています。ディレクティブを適切に組み合わせることで、クローラーの動きを制御します。主なディレクティブは以下の通りです。
| ディレクティブ | 内容 | 使用例 |
| User-agent | 対象とするクローラーを指定 | User-agent: Googlebot |
| Disallow | クローラーにアクセスを禁止するパスを指定 | Disallow: /admin/ |
| Allow | 許可するパスを指定 | Allow: /public/ |
| Sitemap | サイトマップのURLを指定 | Sitemap: https://example.com/sitemap.xml |
| Crawl-delay | クローラーの巡回間隔を指定 | Crawl-delay: 10 |
各ディレクティブの役割を理解することで、より柔軟にクローラーの制御が可能になります。robots.txtファイルの仕様については公式サイト http://www.robotstxt.org/robotstxt.html をご参照ください。
次に、代表的なディレクティブごとに具体的な使い方を詳しく見ていきましょう。
User-agent
User-agentは、robots.txtで制御対象とするクローラーを指定するディレクティブです。検索エンジンやSNS、各種サービスごとに異なるUser-agent名が割り当てられており、特定のクローラーだけにルールを適用することが可能です。全クローラーに共通の設定を行う場合は「*(アスタリスク)」を使用します。
代表的なUser-agentは以下の通りです。
| クローラー | User-agent名 |
| Googlebot | |
| Bing検索 | Bingbot |
| Yahoo!検索 | Y!J-BRU/VSIDX等(参考) |
| FacebookExternalHit | |
| SmartNews | Crowsnest |
| 全クローラー | * |
このように、対象を明確にすることでクローラーごとに柔軟な制御が可能です。マイナーなクローラーや最新情報については、各サービスの公式情報を確認しましょう。
Disallow
Disallowは、クローラーに対して特定のパス(URL)の巡回を禁止するためのディレクティブです。指定したパス以下のページにはアクセスしないよう指示できます。例えば、管理画面やテスト用ディレクトリなど、公開する必要のない領域をクロール対象から除外する際に使用されます。
| User-agent: *Disallow: /admin/ |
この例では、全てのクローラーに対して「/admin/」以下のページをクロール禁止としています。なお、Disallow: / と記載すると、サイト全体のクロールを禁止する設定になります。一方で、何も制限しない場合は「Disallow:」と空欄で記載します。適切に設定することで、不要なクロールを防ぎ、サーバー負荷の軽減や情報漏洩リスクを抑えることが可能です。
Allow
Allowは、クローラーに対して特定のパスのみを巡回許可するためのディレクティブです。主に、広い範囲をDisallowで禁止した上で、一部のページだけクロールを許可したい場合に使用されます。
| User-agent: *Disallow: /private/Allow: /private/public-page.html |
この例では、「/private/」以下を全てクロール禁止としつつ、「public-page.html」だけはクロールを許可しています。DisallowよりもAllowが優先されるため、細かい制御が可能です。ただし、すべてのクローラーがAllowに対応しているわけではない点に注意が必要です。特定ページの公開範囲を限定したい場合に有効な手段です。
Sitemap
Sitemapは、クローラーに対してWebサイトの構造を効率的に伝えるためのディレクティブです。XML形式で作成されたサイトマップのURLを指定することで、クローラーは重要なページを優先的に巡回できるようになります。これにより、特にページ数が多いサイトや更新頻度の高いサイトで、SEO効果の向上が期待できます。
| Sitemap: https://example.com/sitemap.xml |
Sitemapは、User-agentの指定に関係なくファイル内のどこに記載しても有効です。また、複数のサイトマップを指定することも可能です。
Crawl-delay
Crawl-delayは、クローラーがサイトを巡回する際のアクセス間隔を指定するディレクティブです。サーバーへの負荷を軽減したい場合や、頻繁なクロールを避けたい場合に使用されます。数値は「秒」を表し、各リクエストの間隔として機能します。
| User-agent: *Crawl-delay: 10 |
この設定では、クローラーが10秒ごとに1回のペースでアクセスするよう指示しています。ただし、GooglebotはCrawl-delayをサポートしていません。Googleの場合は、Search Consoleからクロール頻度を調整する必要があります。また、対応状況はクローラーごとに異なるため、導入前に確認が必要です。Crawl-delayは、特に中小規模サイトやリソースに限りがある環境で有効な手段となります。
robots.txtの記述例
本章の最後に、robot.txtの記載例を見ていきましょう。
今回は、主要なディレクティブを全て使用したサンプルにて解説します。
| Sitemap: https://www.example.com/sitemap.xml User-agent: Googlebot Disallow: /private/ Allow: /private/public-info.html Crawl-delay: 5 User-agent: * Disallow: /tmp/ Disallow: /backup/ |
この例では、Googlebotに対しては「/private/」以下を禁止しつつ、一部ページのみ許可しています。また、クロール間隔を5秒に設定、全クローラーにはtmpフォルダやバックアップフォルダのアクセスを禁止していることが分かります。
robots.txtの設定方法
robots.txtは、正しい手順で作成しサーバーに配置することで、クローラーへの指示が有効になります。最後に、Webサイト担当者向けにrobots.txtの作成方法からサーバーへの設置方法について解説します。
ファイル作成
robots.txtは、単純なテキストファイルとして作成します。Windowsではメモ帳、Macではテキストエディットで作成可能です。
ファイル名は「robots.txt」で固定となります。誤って「robots.txt.txt」などにならないよう注意しましょう。
記述内容はこれまで解説したディレクティブを用いて構成しますが、書き間違いや不要な全角スペースがあると正常に動作しなくなります。特にコピー&ペーストで作成する場合は、不要な文字が含まれていないか確認しましょう。
サーバーへの設置方法
robots.txtを正しく機能させるためには、決められた場所に正確に設置することが重要です。このファイルは、Webサイトのルートディレクトリ(トップ階層)に配置する必要があります。
OSやサーバー設定にもよりますが、一般的なドキュメントルートは以下のようなパスに設定されています。
| サーバー環境 | ドキュメントルート例 |
| Linux(Apache) | /var/www/html |
| Linux(Nginx) | /usr/share/nginx/html |
| レンタルサーバー | /home/ユーザー名/public_html |
このルート直下に「robots.txt」を配置することで、クローラーが正しく認識します。
また、サーバーへの設置手段も複数あります。自身の環境に応じた設置を行いましょう。
- サーバー上で直接アップロードする
レンタルサーバーやVPSの管理画面(例:cPanel、Plesk)にある「ファイルマネージャー」機能を使い、ドキュメントルートにrobots.txtを配置します。
- サーバーへ直接記載する
オンプレミス環境やAWS EC2の場合は、サーバーに直接ログインして設置することが可能です。
サーバーにsshログインし、cdやviコマンドを使って直接robots.txtを作成しましょう。
- FTPソフト(FFFTPやFileZilla)を使う
FTPクライアントを利用して、ローカルPCからサーバーへファイルを転送します。初心者にも扱いやすく、細かいファイル操作が可能です。
- WordPressでプラグインを使う
WordPressを運営している場合は、「Yoast SEO」や「All in One SEO Pack」などのプラグインを使って、管理画面からrobots.txtを編集・生成することもできます。
テスターによる確認
robots.txtをサーバーに設置した後は、クローラーに正しく認識されているかを確認することが重要です。
確認方法は以下の通りです。
- ブラウザで直接アクセスする
最も簡単な方法は、自分のサイトのURLに「/robots.txt」を追加して確認することです。
例:https://example.com/robots.txt
ここでrobots.txtの内容が表示されれば、設置は完了しています。
- Googleの「robots.txt確認ツール」を使う
Googleが提供するrobots.txtの確認ページでは、Googlebotがrobots.txtをどのように認識しているか確認できます。ここで最新の取得日時や、正しく読み込まれているかをチェックが可能です。ただし、Googleがrobots.txtを認識するまで数日掛かるため注意しましょう。
robots.txtの注意点
robots.txtはシンプルな構造ですが、誤った設定をするとSEOやスクレイピングに深刻な影響を与えることがあります。以下のポイントに注意して運用しましょう。
Webサイト担当者向け
- インデックス制御はできない
robots.txtは「クロールの可否」を指示するものであり、検索結果への表示(インデックス登録)を直接制御するものではありません。インデックスを防ぎたい場合は、HTML内に「metaタグ(noindex)」を使用する必要があります。ただし、クロール自体をブロックすると、metaタグも読み込まれない点に注意が必要です。
- Disallowの過剰設定に注意
意図せず重要なページまでクロール禁止にしてしまうケースが多く見られます。特に「Disallow: /」と記載すると、サイト全体がクロール不可になるため、記述内容は慎重に確認しましょう。
- クローラーが従わないケースもある
robots.txtは「規約」ではなく「お願い」に近い存在です。GooglebotやBingbotなど主要なクローラーは遵守しますが、一部の悪質なボットは無視してアクセスしてくることがあります。セキュリティ対策としては、.htaccessやWAF(Web Application Firewall)によるIP制限も検討しましょう。
スクレイピング実施者向け
- robots.txtは必ず確認すること
スクレイピングを行う前に、対象サイトのrobots.txtを確認し、許可された範囲内でデータ取得を行いましょう。Disallowで制限されている領域へのアクセスは、技術的に可能であっても法的措置を受ける可能性があります。
- アクセス頻度に配慮する
Crawl-delayが設定されている場合は、それを遵守しましょう。仮に記載がなくても、過剰なリクエストはサーバー負荷を高め、IPブロックや法的リスクにつながることがあります。
- 利用規約の確認も重要
robots.txtだけでなく、サイトの利用規約でスクレイピングが禁止されていないかも確認しましょう。特に商用利用を目的とする場合は、リスク管理が必要です。
関連記事:スクレイピングは違法?Webスクレイピングに関するよくある誤解!
まとめ
robots.txtは、クローラー制御を行うための重要なファイルであり、SEO対策やスクレイピングに欠かせない存在です。正しく設定すれば、不要なクロールを防ぎ、サーバー負荷の軽減や情報管理を効率化できます。スクレイピングを行う際も、必ずrobots.txtを確認し、許可された範囲でデータ取得を行うことが重要です。
サイト運営者もスクレイピング実施者も、robots.txtを正しく理解し、適切に活用することが求められます。

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール



