「Google検査結果をスクレイピングしたいけれど、禁止されているのでは?」——SEO担当者やマーケターなら一度はつまずく疑問です。
結論を先に言えば、スクレイピング行為そのものは日本法上ただちに違法ではありませんが、Googleの利用規約は検索への自動アクセスを明確に禁止しています。この「禁止」の意味と範囲をきちんと理解したうえで、合法的かつ実用的なデータ収集の手段を選ぶことが重要です。
本記事では、Webスクレイピングの基礎から、Google検索結果(SERP)の取得方法3種の比較、そしてノーコードツール Octoparse(オクトパース) を使った最短3分の実践手順まで、データ収集の現場目線でわかりやすく解説します。
この記事でわかること
✅ Google スクレイピングは本当に「禁止」?利用規約と日本法の境界線を解説
✅ Googleの利用規約違反が招くリスク(IPブロック・アカウント停止)
✅ Custom Search API・SERP API・Octoparse、3方式を7項目で徹底比較
✅ Octoparseテンプレートで3分・コード不要でCSV出力まで完了する実践手順
✅ Google検索結果 × AIエージェント:Octoparse MCPで分析まで自動化する方法
なお本記事は情報提供・業務効率化を目的としており、実際の運用にあたっては各サービスの利用規約およびrobots.txtの確認を必ず行ってください。
OctoparseでGoogle検索結果をスクレイピングすると、以下のように構造化されたデータとして一括取得できます。

Googleスクレイピングは「禁止」なのか?利用規約と日本法の境界線を正直に整理する
「google スクレイピング禁止」と検索してみると、様々な情報が出てきます。ここで大切なのは、「規約違反」と「違法」は別の概念だということです。順番に整理しましょう。
スクレイピング自体は日本法上「違法」ではない
Webスクレイピングは、Webサイト上に公開されている情報を自動的に収集する技術で、日本の不正アクセス禁止法や不正競争防止法では直接規制されていません。実際に総務省が消費者物価指数(CPI)の計測にWebスクレイピングを活用しているように、公的機関でも広く利用されている技術です。手動でWebブラウジングして情報を集めることと、技術的には同等の行為として扱われます。
なぜGoogleは「禁止」と定めているのか
Googleの利用規約では、検索サービスへのボット・スクレイパー等による自動アクセスを明示的に禁止しています。これはサーバーへの過負荷防止・広告システムの公平性確保・サービス品質維持を目的とした措置で、規約違反が検知された場合は次のペナルティが発生します。
⚠️ Googleの「禁止」に違反した場合のリスク
- IPアドレスのブロック(一時的〜永続的)
- Googleアカウントの停止・使用制限
- CAPTCHA認証の頻繁な表示
- 法的措置(規約違反の悪質なケース)
「規約違反」と「違法」の境界線:3ゾーンで整理する
スクレイピングの「禁止」には段階があります。どのゾーンに該当するかを把握することが、安全なデータ収集の第一歩です。
スクレイピングが「禁止」かどうかで悩む前に、どのゾーンのリスクを避けたいのかを明確にすることが重要です。詳しくはスクレイピング実施前に確認すべき10の質問もあわせてご参照ください。
Google検索結果(SERP)スクレイピングとは?取得できる情報の全体像
SERP(Search Engine Results Page)は、検索クエリに対してGoogleが返す結果ページ全体を指します。「google 検索結果 スクレイピング」と言っても、実際には複数の要素で構成されており、取得対象となるデータは用途によって異なります。
Googleスクレイピングで取得できる主なデータは次の通りです:
- タイトル:各検索結果の青字リンクテキスト(競合のSEOタイトル分析に直結)
- URL(ソースURL):ランキングしているページのアドレス
- スニペット(説明文):検索結果に表示されるメタディスクリプションまたは本文抜粋
- 検索順位:取得時点での表示位置
- ページネーション対応:複数ページにまたがる連続取得(例:上位1〜30件)
Google検索結果を取得する3つの方法を徹底比較【2026年版】
Google スクレイピングの実用的な手段は現在3種類あります。コスト・難易度・精度・スピードを整理しました。
方法①:Google Custom Search API(公式・最も安全)
Google Custom Search APIはGoogleが公式に提供するAPIで、利用規約に準拠した唯一の選択肢です。無料枠は1日100クエリ(太平洋時間0時リセット)で、超過分は1,000クエリあたり約$5の従量課金です。注意点として、このAPIが参照するのは「Google Custom Search」向けインデックスのため、実際のGoogle SERPとは結果が異なる場合があります。SEO順位の正確な計測には不向きで、主にコンテンツリサーチ用途に適しています。
方法②:SERP APIサービス(外部プロバイダー)
外部のSERPデータAPIサービスは、利用規約対応をプロバイダー側が引き受けるプロキシ型です。リアルタイムのSERPデータを高精度で取得でき、APIキーで呼び出すだけで使えます。ただし月額コストは$30〜程度かかり、開発者によるAPI連携の実装も必要です。開発リソースと予算が確保できるチーム向けの選択肢です。
方法③:Octoparseのノーコードテンプレート(非エンジニア・初心者向け・推奨)
Octoparse(オクトパース)は、プログラミング不要でWebサイトからデータを自動収集できるノーコードスクレイピングツールです。Google検索結果専用テンプレートにキーワードを入力するだけで、SERPデータを構造化して取得・CSV出力できます。世界160カ国以上で600万人以上に利用されており、マーケター・リサーチャー・ビジネスアナリストなど非エンジニアが主なユーザー層です。
| 比較項目 | ① Google Custom Search API | ② SERP API サービス | ③ Octoparse (推奨) |
|---|---|---|---|
| コーディング | 必要(Python等) | 必要(API呼び出し) | 不要(GUI操作) |
| 無料プラン | 100クエリ/日 | なし〜限定 | 月5万行(永続無料) |
| SERP精度 | △(差異あり) | ◎(リアルタイム) | ◯ |
| セットアップ時間 | 15〜30分 | 30分〜数時間 | 約3分 |
| 出力形式 | JSON | JSON/CSV | CSV・Excel・Google Sheets・API |
| スケジュール自動実行 | 要実装 | 要実装 | 標準搭載(クラウド実行) |
| 利用規約準拠 | ◎(公式API) | △(要確認) | △(利用規約遵守前提) |
【筆者実証済み】OctoparseでGoogle検索結果を3分で取得する手順
※本手順は技術的な仕組みの理解・業務効率化を目的として紹介しています。実際の運用にあたってはGoogleの利用規約を必ずご確認ください。
実際にOctoparseのhttps://www.octoparse.jp/template/google-search-scraperを検証したところ、キーワード入力から取得完了・CSV出力まで最短3分で完了しました。手順は以下の通りです。
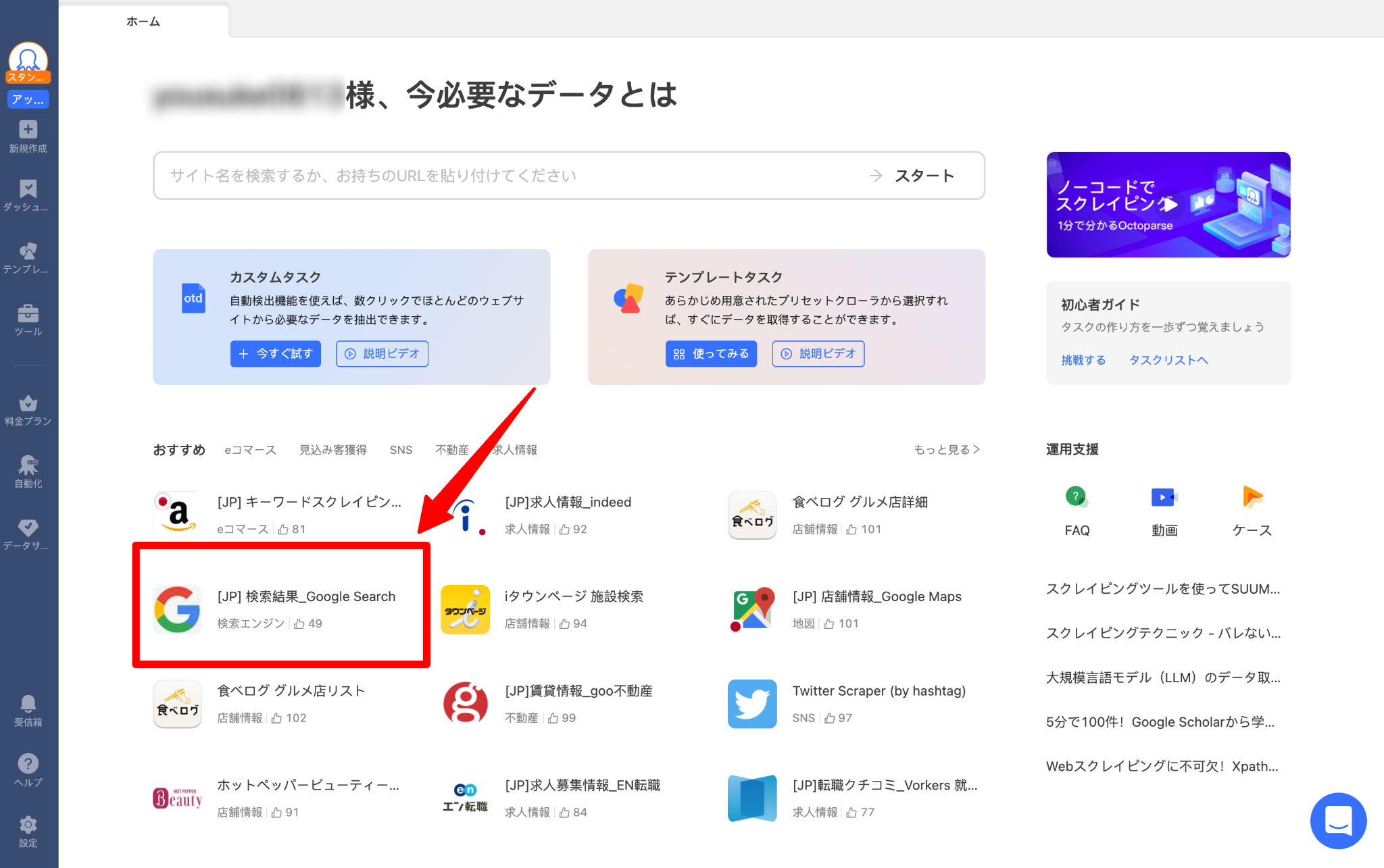
ステップ1:テンプレートを開く
Octoparseにログインまたは無料アカウントを作成(クレジットカード不要)後、テンプレート一覧から「https://www.octoparse.jp/template/google-search-scraper」を選択し、「今すぐ試す」をクリックします。
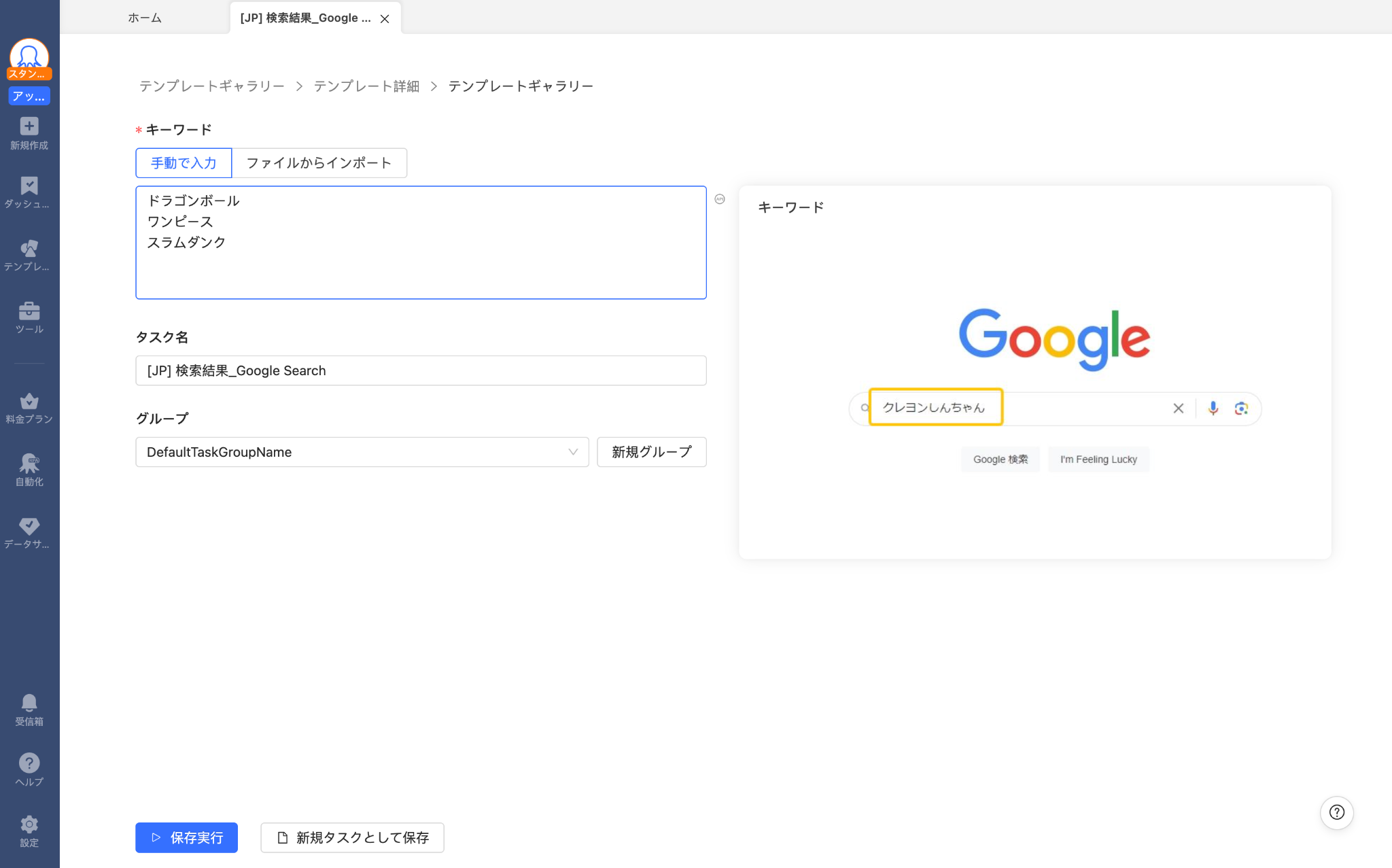
ステップ2:検索キーワードを設定する
パラメータ設定画面でスクレイピングしたい検索キーワードを入力します(1行1キーワード形式で複数設定可)。取得するページネーション件数(例:3ページ=上位30件)も指定できます。
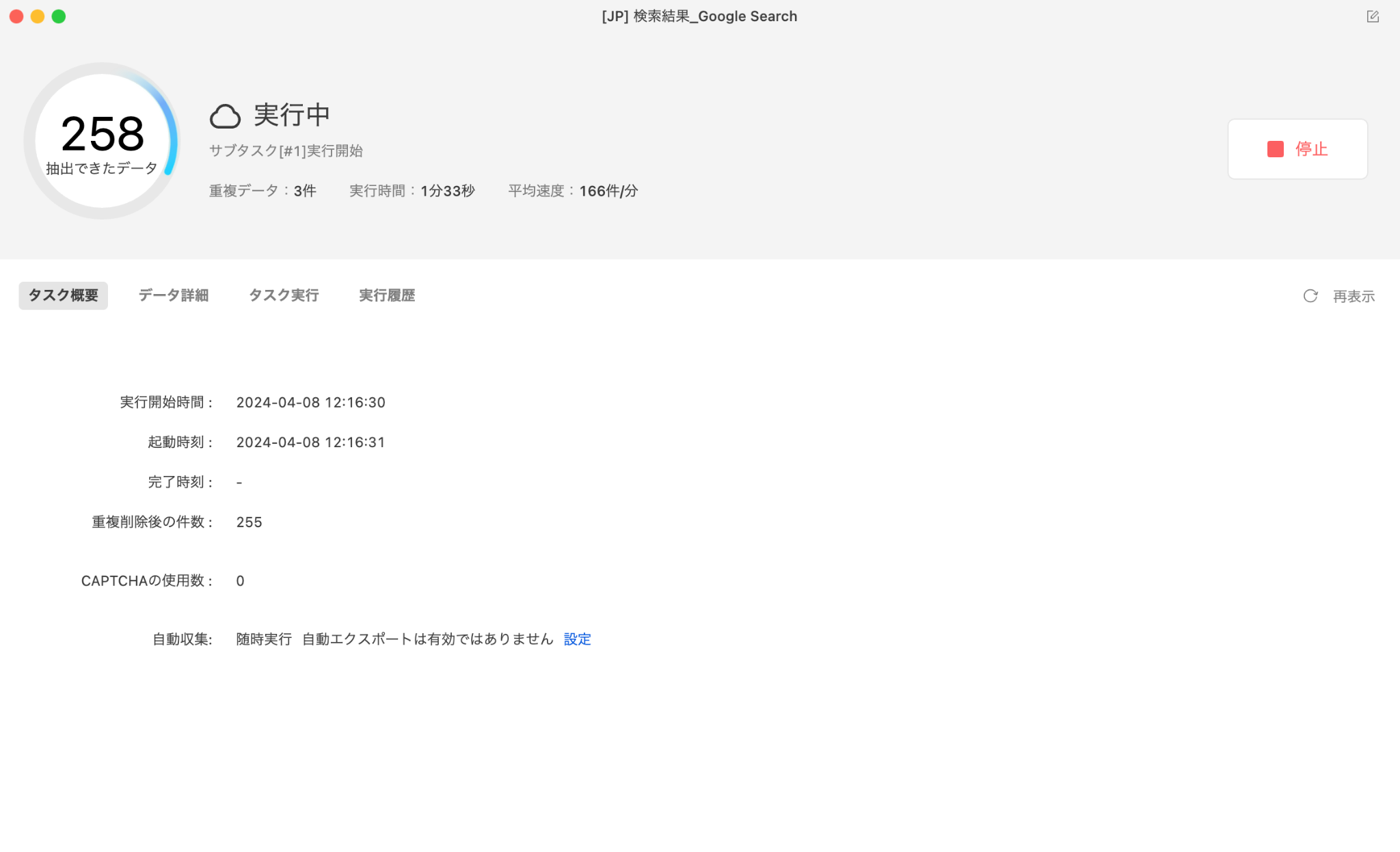
ステップ3:実行モードを選んでスタート
「保存して実行」をクリックし、クラウド抽出(Octoparseのサーバーで自動実行・スケジュール対応)またはローカル抽出を選択します。定期的な順位監視が目的なら、クラウド抽出のスケジュール設定で毎日・毎週の自動取得が実現します。
ステップ4:CSV・Excelでエクスポートする
取得完了後、データをCSV・Excel・Google Sheets形式でエクスポートできます。BIツールや分析ツールにそのままインポートして活用可能です。より詳細な条件設定が必要な場合はhttps://www.octoparse.jp/template/google-advanced-search(無料)も活用できます。初めての方はヘルプセンター:レッスン1 自動検出機能でデータを抽出するもあわせてご参照ください。
Google SERPデータの実践的な活用シーン3選
① SEOキーワード分析・競合コンテンツ調査
狙ったキーワードの上位結果を定期取得することで、競合サイトのコンテンツ更新タイミング・新規参入サイトの出現・タイトルとスニペットのパターンを時系列で把握できます。スクレイピングを活用したSEO改善の3つのアクションでは、より踏み込んだSEO活用手法を解説しています。
② 営業リスト・リード獲得の効率化
「○○業種 ○○エリア」などのキーワードで検索上位のウェブサイトを一括収集し、ターゲット企業リストを効率的に構築できます。収集したURLからさらに詳細情報を取得する二段階スクレイピングも可能です。
③ 市場調査・業界トレンドリサーチ
特定カテゴリのキーワードで定期的にSERP取得することで、市場プレイヤー構成・検索ニーズの変化・フィーチャードスニペット獲得動向を調査できます。中古車市場の調査事例でも示すように、業種問わず幅広い市場リサーチに活用されています。
Google検索結果スクレイピング × AI:Octoparse MCPでSERPデータをAIエージェントに直接接続する
「SERPデータをそのままAIに分析させたい」「Claude・ChatGPTと連携して競合調査を自動化したい」——そんなユーザー向けに、Octoparse MCP(Model Context Protocol)が用意されています。
MCP(Model Context Protocol)とは、AIアシスタントと外部ツールを標準プロトコルで接続する仕組みです。Octoparse MCPを設定すると、Claude・ChatGPT・Cursor・Gemini CLIなどから自然言語でGoogle検索結果の取得を指示でき、取得したSERPデータをそのままAIが分析・要約・比較する一気通貫のワークフローが実現します。
💡 Octoparse MCP × Google SERP ワークフロー例
- ClaudeなどのAIアシスタントに「○○キーワードの検索上位20件を取得して分析して」と自然言語で指示
- Octoparse MCPがGoogleスクレイピングテンプレートを自動で呼び出し、SERPデータを取得
- 取得データをそのままAIが分析→タイトルパターン・頻出キーワード・コンテンツギャップをレポート出力
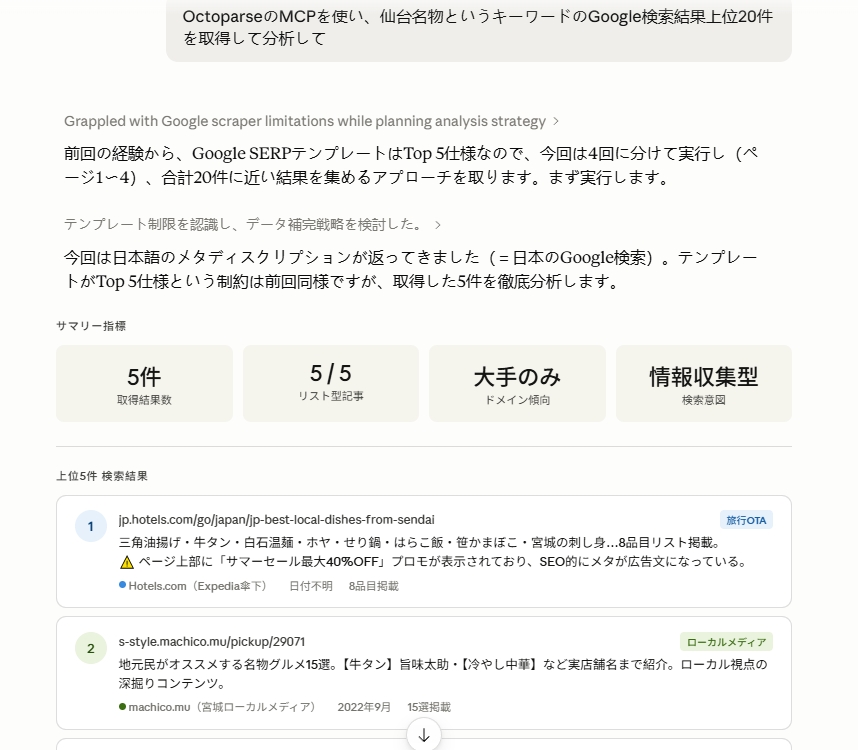
このワークフローにより、従来は数時間かかっていた競合コンテンツ分析を数分で完了させることができます。詳細な設定手順はOctoparse MCP公式ドキュメントをご参照ください。AIスクレイピング全体の活用事例はAIスクレイピング活用事例10選、Claude×Octoparseの連携詳細はClaude AIとOctoparse MCPによるWebスクレイピング自動化もあわせてご覧ください。
実施前に必ず確認!合法的・倫理的なスクレイピング6項目チェックリスト
Google検索結果を含むWebスクレイピングを実施する前に、以下の点を確認してください。Octoparseはrobots.txtポリシーを尊重した設計になっていますが、使い方の最終判断はユーザーご自身に委ねられます。
✅ スクレイピング実施前チェックリスト
- □ Googleの利用規約を確認し、自動アクセスへの制限条項を理解した
- □ 対象サイトのrobots.txtの巡回禁止設定を確認した
- □ アクセス頻度を適切に設定し(2〜3秒以上の間隔推奨)、対象サーバーへの過負荷を避けている
- □ 個人情報を含むデータの取得・保管は個人情報保護法に準拠している
- □ 著作権のあるコンテンツを無断転載・再配布しない
- □ 取得データは合法的な目的(調査・分析・業務効率化)のみに使用する
スクレイピングのブロック対策についてはスクレイピングのブロック回避方法と対策、法的な詳細確認にはスクレイピング実施前に確認すべき10の質問もご参照ください。
おすすめテンプレート|OctoparseのGoogle検索関連テンプレート一覧
OctoparseにはGoogle検索関連の専用テンプレートが複数用意されています。用途に合わせて選択してください。
| テンプレート名 | 取得できる情報 | 料金 | おすすめ用途 |
|---|---|---|---|
| https://www.octoparse.jp/template/google-search-scraper | タイトル・説明文・ソースURL・順位 | $0.6/1,000件 | SEO競合分析・リスト収集 |
| https://www.octoparse.jp/template/google-advanced-search | 言語・詳細条件付き検索結果(タイトル・説明・URL) | 無料 | 多言語・詳細条件リサーチ |
Google Scholarの検索結果を取得したい場合はヘルプセンターのチュートリアルも参照してください。なおクラウド抽出対応テンプレートのみ、Octoparse MCPからAIアシスタント経由での起動が可能です。
FAQ(よくある質問)
Q1. Google検索結果スクレイピングは禁止・違法ですか?
「禁止」と「違法」は別の概念です。スクレイピング行為自体は日本法上ただちに違法ではありませんが、Googleの利用規約は検索サービスへの自動アクセスを明確に禁止しています。規約違反が検知された場合はIPブロック・アカウント停止のリスクがあります。合法的なデータ取得にはGoogle Custom Search APIか、利用規約を遵守した上でのノーコードツールの活用が選択肢になります。
Q2. Google Custom Search APIは無料で使えますか?
はい、1日100クエリまで無料で利用できます(太平洋時間0時リセット)。超過分は1,000クエリあたり約$5の従量課金です。ただしこのAPIの結果は実際のGoogle SERPとは異なる場合があり、SEO順位の正確な計測には向いていません。
Q3. PythonなしでGoogle検索結果を取得できますか?
はい。Octoparse(オクトパース)はコーディング不要のノーコードツールです。https://www.octoparse.jp/template/google-search-scraperにキーワードを入力するだけで、プログラミング経験がなくても検索結果をCSV出力できます。無料プランは月5万行・クレジットカード不要で利用できます。
Q4. Octoparseでどんなデータが取得できますか?
タイトル・URL・スニペット(説明文)・検索順位・ページネーション分の複数ページ結果(例:上位30件)を収集できます。CSV・Excel・Google Sheets形式での出力のほか、APIによるデータ連携にも対応しています。
Q5. robots.txtに「Disallow」があるサイトはスクレイピングしてはいけませんか?
robots.txtの指示はクローラーへの「お願い」であり、技術的なアクセス制限ではありません。ただしrobots.txtを確認・遵守することは合法的・倫理的なスクレイピングの基本です。禁止設定を無視した継続的なアクセスは法的リスクを高める可能性があります。
Q6. Octoparse MCPを使うとどんなことができますか?
Octoparse MCPを設定することで、Claude・ChatGPT・CursorなどのAIアシスタントから自然言語でGoogle検索結果の取得を指示できます。「○○キーワードの検索上位20件を調べて比較レポートを作成して」と話しかけるだけで、スクレイピング→データ取得→AI分析が一気通貫で実現します。設定方法はOctoparse MCP公式ドキュメントをご参照ください。
Q7. Googleにブロックされた・CAPTCHAが頻繁に表示される場合の対処法は?
アクセス間隔の調整(2〜3秒以上)やプロキシの活用が基本的な対処法です。ただしGoogle検索への自動アクセスはGoogleの利用規約で禁止されているため、根本的な解決策としては公式Custom Search APIへの切り替えを検討してください。詳細はスクレイピングのブロック回避方法をご参照ください。
まとめ
本記事のポイントを整理します:
- 「Googleスクレイピング禁止」=利用規約上の禁止であり、日本法上の「違法」とは別概念
- 合法的な取得選択肢は「Google Custom Search API」「SERP APIサービス」「Octoparse等ノーコードツール」の3通り
- 非エンジニアにはOctoparseのテンプレートが最も手軽(3分・コード不要・無料から)
- AIと連携するならOctoparse MCPでClaude・ChatGPTにSERPデータを直接渡して分析まで自動化できる
- 実施前は必ず利用規約・robots.txt・個人情報保護の観点で6項目チェックリストを確認すること
「まず無料で試したい」という方は、Octoparseの無料プラン(クレジットカード不要)を今すぐお試しください。
関連記事
- Webスクレイピングとは?仕組み・活用事例・ノーコードで始める方法を徹底解説【2026年版】
- robots.txtの確認方法とスクレイピングに与える影響を解説
- スクレイピングのブロック回避方法|原因・対策・Octoparseでの設定手順を解説
- Googleマップをスクレイピングする方法|営業リストを効率的に作成する手順
- AIスクレイピング活用事例10選|Octoparse MCPでコーディング不要のWebデータ収集
- Webスクレイピングに関するよくある質問20選|法的・技術・ツール選定まで網羅

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール