instant Data Scraperは、プログラミング不要でWebデータをCSV・Excelに自動抽出できる無料のChrome拡張機能です。商品リストや競合価格の収集を「クリックだけ」で爆速化できるため、多くの業務効率化の現場で重宝されています。
本記事では、instant Data Scraperの使い方をインストールからCSV書き出しまでの手順を徹底解説します。私自身が実際に200件のデータを抽出した際に直面した「動的ページの欠落トラブル」とその解決策も公開しているため、これ一記事で「詰まるポイント」まで全て網羅可能です。 ぜひブックマークして、実際の作業を見ながら進めてみてください。
Instant Data Scraperとは?──AIで自動データ抽出するChrome拡張機能
Instant Data Scraperは、WebページのHTML構造をAIが自動解析し、テーブルやリストなどの構造化データをワンクリックで抽出できるChrome拡張機能です。開発元はWebRobots.ioで、完全無料・アカウント登録不要で利用できます。
通常、Webページからデータを取得するには「Webスクレイピング」と呼ばれる技術が必要で、PythonやBeautifulSoupといったプログラミングの知識が前提でした。Instant Data Scraperはそのハードルを取り払い、プログラミング経験ゼロの方でもブラウザ上でデータ抽出が完結する点が最大の特徴です。
何ができる?Instant Data Scraperの主な機能と対応フォーマット
Instant Data Scraperでできる主なことは、Webページ上のテーブル・リスト・商品一覧などの構造化データを自動検出して、CSV・XLSX形式でエクスポートすることです。以下に主な機能をまとめます。
| 機能 | 内容 |
|---|---|
| AI自動検出 | ページ上の最も関連性の高いデータをAIが自動で特定 |
| テーブル切り替え | 「Try Another Table」で取得対象を手動で変更可能 |
| ページネーション対応 | 「次へ」ボタンを指定して複数ページを自動巡回 |
| 無限スクロール対応 | 自動スクロールで遅延読み込みコンテンツも取得 |
| エクスポート形式 | CSV・XLS・XLSX(Googleスプレッドシートにそのまま貼付可能) |
| 料金 | 完全無料(アカウント登録不要) |
Instant Data Scraperは無料で使えるのか?利用条件を確認
はい、Instant Data Scraperは完全無料で使えます。有料プランや登録は一切不要です。ただし、1回の取得データ件数の上限は非公式ながら約1,000件とされており、大量データの定期取得には向いていません。個人利用・小規模なデータ調査であれば十分な機能を無料で使えます。
また、利用にあたっては対象サイトの利用規約やrobots.txtを必ず確認してください。公開データを個人・研究目的で収集する場合はリスクが低いですが、著作権侵害やサーバーへの過負荷は問題になり得ます。詳しくはWebスクレイピングの違法性と安全なルール(Octoparse)をご確認ください。
Instant Data Scraperのダウンロード・インストール方法
Instant Data ScraperのインストールはChromeウェブストアから1分以内に完了します。アカウント登録やメールアドレスの入力も不要で、以下の2ステップだけです。
ステップ1:Chromeウェブストアから拡張機能を追加する
Googleアカウントでログインした状態のChromeブラウザで、以下の手順を実行してください。
- Chromeブラウザで Instant Data Scraper(Chromeウェブストア) にアクセスする
- 画面右上の青いボタン「Chromeに追加」をクリックする
- 「拡張機能を追加しますか?」のポップアップが表示されたら「拡張機能を追加」をクリック
- 右上のパズルピースアイコン(🧩)をクリックして、インストール済みを確認する
ステップ2:拡張機能をツールバーにピン留めする
インストール直後は拡張機能がツールバーに表示されていない場合があります。毎回すぐにアクセスできるよう、ピン留めしておくことをおすすめします。
- Chromeツールバー右端のパズルピースアイコン(🧩)をクリックする
- 拡張機能の一覧から「Instant Data Scraper」を見つける
- 右側の📌ピンアイコンをクリックしてツールバーに固定する

- ツールバーにInstant Data Scraperのアイコンが常時表示されることを確認する
Instant Data Scraperの使い方──具体的な操作手順【図解】
Instant Data Scraperでのデータ抽出は、基本的に「ページを開く→拡張機能を起動→Locate Table→ダウンロード」の4ステップで完了します。以下では、ECサイトの商品一覧ページを例に、実際の操作を画像付きで解説します。
ステップ1:データを取得したいページを開く
Chromeブラウザでデータを抽出したいWebページを開きます。商品一覧・求人一覧・検索結果ページなど、同じ構造が繰り返されているページが最も取得しやすいです。たとえば、Amazonの検索結果、食べログのレストラン一覧、Indeedの求人一覧などが典型例です。
⚠️ 注意:ログインしなければ見られないページ(会員専用ページなど)は事前にログインした状態でアクセスしてください。ただし、ログイン必須かつJavaScriptで動的に描画されるページはInstant Data Scraperでは取得できない場合があります(詳しくは「できないこと・限界」のセクションを参照)。
ステップ2:拡張機能を起動してAI自動検出を確認する
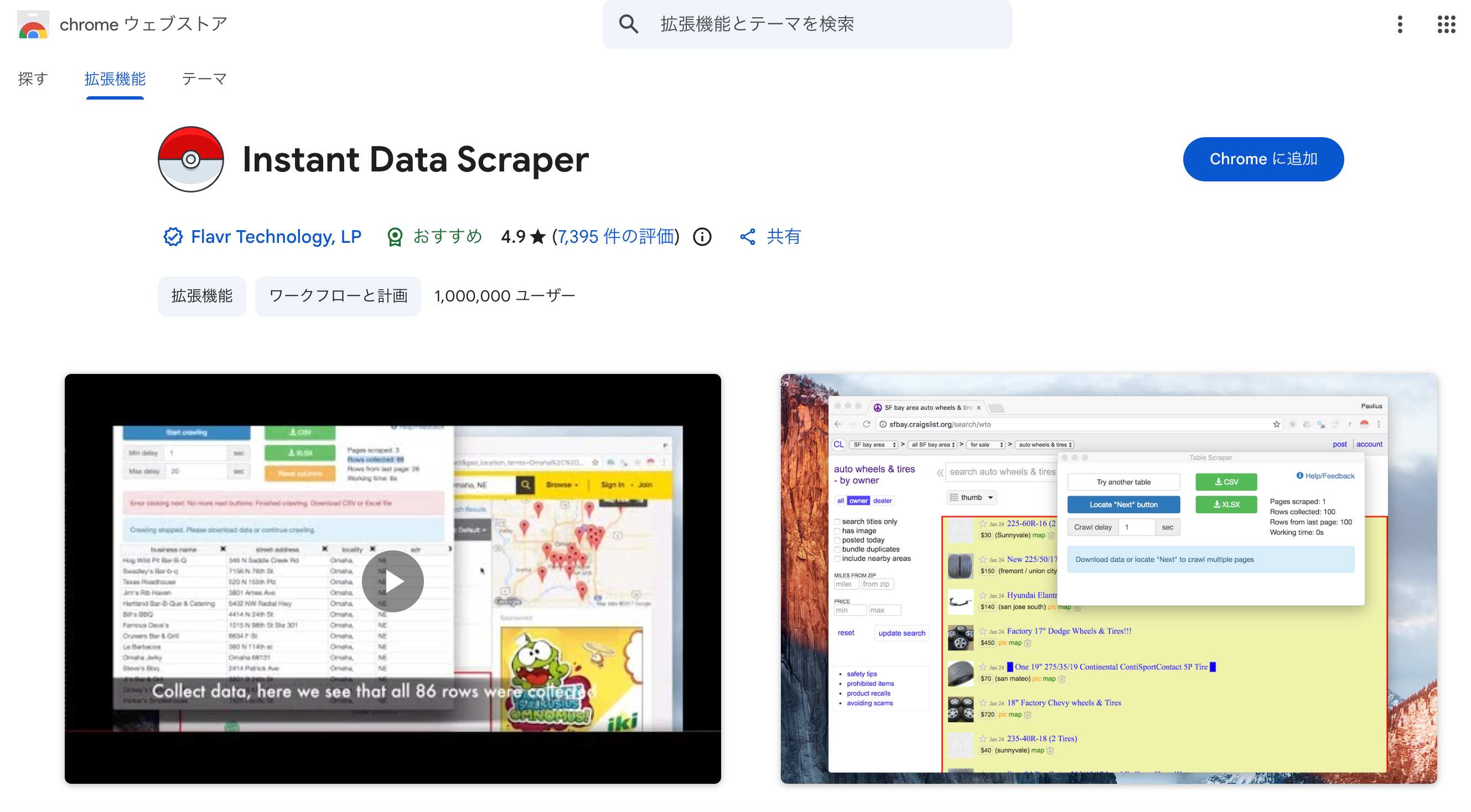
ツールバーのInstant Data Scraperアイコンをクリックすると拡張機能のポップアップが開き、AIがページ上の構造化データを自動的に検出してハイライト(黄色枠)で表示します。ポップアップには検出されたデータのプレビューが表形式で表示されます。
プレビューを確認して、取得したいデータが正しく表示されていれば次のステップへ進みます。
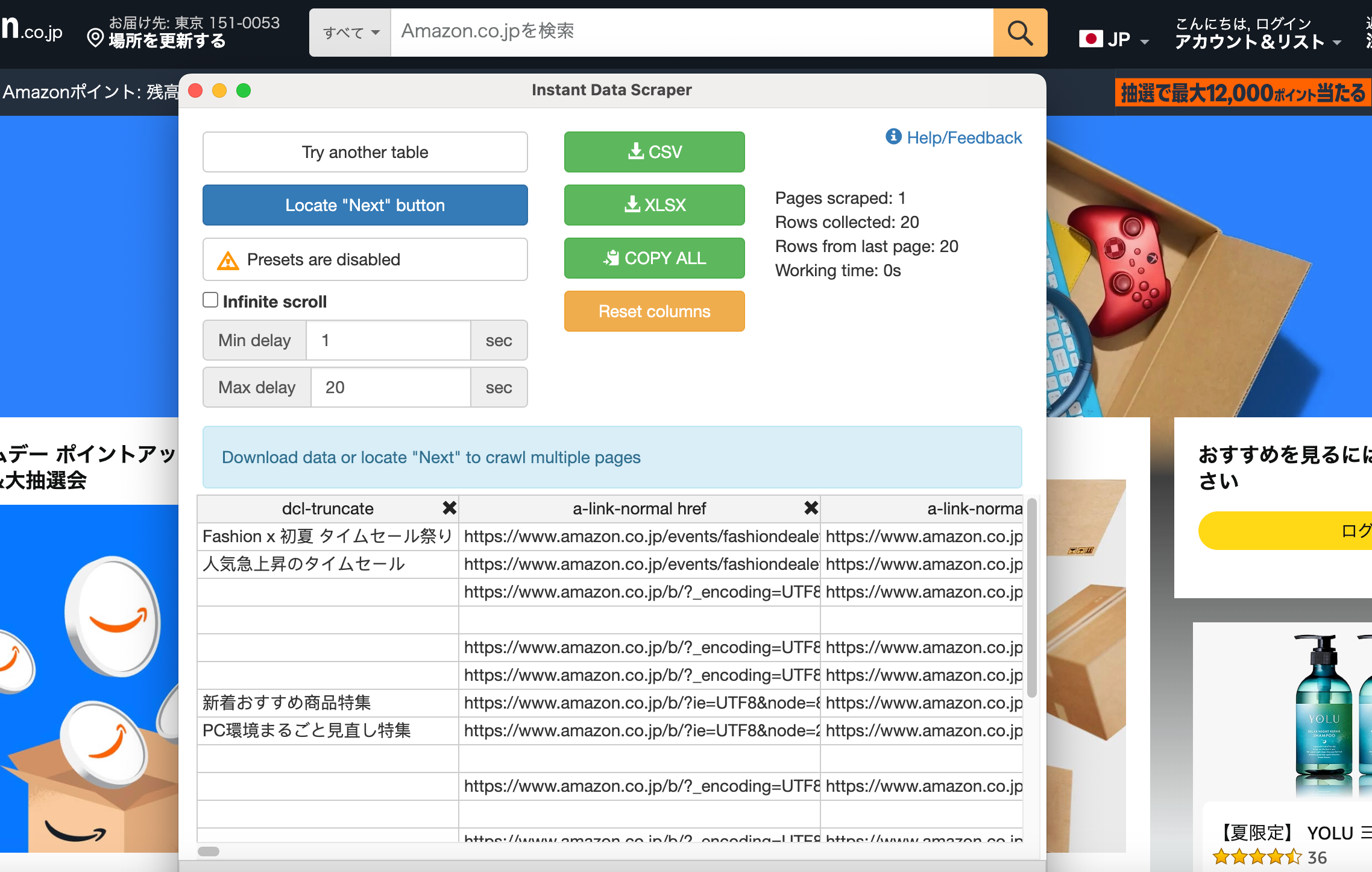
ステップ3:「Try Another Table」でテーブルを切り替えて取得範囲を調整する
AIの自動検出が目的のデータと異なる場合は、「Try Another Table」ボタンを押して別の候補に切り替えることができます。1つのページに複数のデータ群がある場合(メインリスト+サイドバーのおすすめ一覧など)、このボタンで対象を切り替えながら目的のデータを探してください。
希望のデータがハイライトされたら、ポップアップのプレビューテーブルで列名と内容を確認します。不要な列がある場合は列ヘッダーのチェックボックスを外して除外できます。
ステップ4:複数ページ(ページネーション)を設定して自動巡回する
Instant Data Scraperの便利な機能の1つが、「次へ」ボタンを設定するだけで複数ページを自動巡回してデータを連続取得できるページネーション対応です。以下の手順で設定します。
- ポップアップ内の「Locate ‘Next page’ button」をクリックする
- ダイアログが一時的に閉じる(←これは正常な動作です)
- ページ上の「次のページ」「Next」「>」などのボタンをクリックして教える
- ツールバーアイコンを再度クリックしてポップアップを開く
- 「Start Crawling」ボタンを押すと自動巡回が始まる
⚠️ 上限の目安:連続取得できるデータ件数は非公式ながら約1,000件が上限とされています。それ以上の大量取得には後述のOctoparseなどのデスクトップツールが適しています。
なお、「次へ」ボタンではなくページを下にスクロールすると自動で次のコンテンツが読み込まれる無限スクロール方式のサイト(例:X(旧Twitter)タイムライン風のレイアウト)の場合は、ポップアップ内の「Infinite Scroll」トグルをオンにしてください。
ステップ5:CSVまたはExcelでデータをダウンロード・書き出す
データ取得が完了したら、ポップアップ下部の「Download CSV」または「Download XLSX」ボタンをクリックするだけでファイルが保存されます。
- CSV形式:Googleスプレッドシートにそのままドラッグ&ドロップで貼り付け可能。文字コードはUTF-8で保存されるため、Excelで開く際は「データ→外部データの取り込み」から文字コードをUTF-8に指定してください。
- XLSX形式:Excelで直接開ける形式。日本語を含むデータの場合はXLSX推奨。
Instant Data Scraperでできないこと──限界と正直な注意点
Instant Data Scraperは軽量で手軽な反面、「動的サイト」「大量・定期取得」「ログイン後の複雑なページ」では機能が限られます。実際に使ってみて壁にぶつかった経験をもとに、正直に解説します。
動的サイト・JavaScriptレンダリングへの対応限界
Instant Data ScraperはHTMLの静的構造を読み取るツールのため、JavaScriptで動的に描画されるコンテンツの取得は不安定または不可能です。具体的には以下のようなサイトで問題が起きやすいです。
- 楽天市場・メルカリなど、Reactベースで動的レンダリングされるECサイト
- X(旧Twitter)・Instagramなどのソーシャルメディア
- スクロール後に非同期でデータが読み込まれるタイプのページ
- CAPTCHA(ボット対策)が設置されているサイト
このような動的サイトへのデータ抽出が必要な場合は、Octoparseのデスクトップ版が適しています。Octoparseはブラウザを内蔵しており、JavaScriptを完全に実行した状態でデータを抽出できます。
大量データの定期取得・自動スケジュール実行の限界
Instant Data Scraperはブラウザを開いて手動で操作する必要があるため、「毎日自動でデータを取得する」「1万件以上を一括収集する」といった自動化・大量取得には対応していません。
以下の要件がある場合は、よりパワフルなツールへの乗り換えを検討してください。
- 件数が多い:1,000件超のデータを一度に取得したい
- 定期実行:毎日・毎週など決まったスケジュールで自動収集したい
- 複数サイト同時:複数のURLを並列でスクレイピングしたい
- クラウド保存:PCを開かずにバックグラウンドで取得し続けたい
Instant Data Scraper vs Web Scraper vs Octoparse──ユーザーが最も気にする軸で徹底比較
3ツールの最大の違いを一言で言うと、「手軽さと機能の深さのトレードオフ」です。Instant Data Scraperは最も手軽、Web Scraperは中間、Octoparseは最も高機能かつ複雑なサイトに対応します。以下の比較表はユーザーが実際に悩む観点を軸に、中立・客観的にまとめています。
| 比較項目 | Instant Data Scraper | Web Scraper | Octoparse |
|---|---|---|---|
| 料金 | 完全無料 | 基本無料(クラウド機能は有料) | 無料プランあり/有料プランあり |
| インストール形式 | Chrome拡張機能のみ | Chrome拡張機能のみ | デスクトップアプリ(Win/Mac) |
| コーディング不要 | ✅ 不要 | ⚠️ SitemapのXPath設定が必要 | ✅ 不要(ノーコード) |
| 静的ページ対応 | ✅ 得意 | ✅ 対応 | ✅ 対応 |
| 動的ページ(JS)対応 | ❌ 不安定・非対応が多い | ⚠️ 一部対応 | ✅ 完全対応 |
| 複数ページ自動巡回 | ✅ ページネーション・無限スクロール対応 | ✅ 対応 | ✅ 対応 |
| 定期自動実行(スケジューラー) | ❌ 非対応 | ⚠️ クラウドプランのみ | ✅ 対応(クラウド実行) |
| 大量データ取得(1万件超) | ❌ 約1,000件が上限 | ⚠️ 可能だが速度が遅い | ✅ クラウドで高速並列処理 |
| ログイン後のページ | ⚠️ 事前ログインで一部対応 | ⚠️ 一部対応 | ✅ 対応 |
| データエクスポート形式 | CSV・XLSX | CSV | CSV・Excel・JSON・HTML・API |
| 日本語UI | ❌ 英語のみ | ❌ 英語のみ | ✅ 日本語完全対応 |
| 日本向けテンプレート | ❌ なし | ❌ なし | ✅ あり(食べログ・Indeed・Yahoo等) |
| 学習コスト | ⭐ 非常に低い(5分で使える) | ⭐⭐ 中程度(設定に慣れが必要) | ⭐⭐ 低〜中(テンプレートで即使用可) |
| サポート | Facebookグループ | ドキュメントのみ | ✅ チャット・メールサポート(日本語) |
どれを選ぶべきか?用途別の選び方ガイド
用途と規模によって最適なツールは異なります。以下のフローチャートで自分に合ったツールを確認してください。
- 🟢 今すぐ無料で、簡単なページから少量データを取りたい → Instant Data Scraper
- 🟡 複雑なサイト構造をカスタマイズしてスクレイピングしたい(多少の設定は苦にならない) → Web Scraper
- 🔵 動的サイト対応・定期自動実行・大量取得・日本語サポートが欲しい → Octoparse
Instant Data Scraperの代替として「Octoparse」が選ばれる理由──できないことをすべて解決
「Instant Data Scraperでは動的サイトが取れなかった」「毎日自動で取得したい」「データが1,000件を超える」——そのような悩みを持つユーザーが次に選ぶのがOctoparseです。
Instant Data Scraperは「とにかく今すぐ手軽に」というニーズに応える優れたツールですが、ビジネス活用や継続的なデータ収集には力不足になることがあります。たとえば、競合の価格を毎朝自動でチェックしたい、ECサイトの全商品5,000件を週次で収集したい、といった業務用途では Instant Data Scraperでは対応できません。
Octoparseはコーディング不要のノーコードデータスクレイピングツールとして、まさにそのギャップを埋めるために設計されています。
OctoparseがInstant Data Scraperより優れている点
- ✅ JavaScriptを完全実行できる内蔵ブラウザ:楽天・メルカリ・X(旧Twitter)など動的サイトも正確に取得
- ✅ 自動スケジュール実行:毎日・毎週など指定した時間に自動でデータ収集(PC不要のクラウド実行)
- ✅ 大量データ対応:1万件・10万件超のデータもクラウドで高速並列処理(最大6〜20倍速)
- ✅ 日本語UIと日本語サポート:インターフェースが日本語対応、チャット・メールサポートあり
- ✅ 日本サイト向けテンプレート:食べログ・Indeed・Yahooショッピング・ガリバーフリマなど国内主要サイトに対応済みテンプレートを搭載
- ✅ 複数フォーマットでエクスポート:CSV・Excel・JSON・HTMLのほか、APIでシステムと直接連携可能
- ✅MCP対応:OctoparseはMCP(Model Context Protocol)に対応しており、AIによるWebデータ収集の自動化を実現します。 ChatGPT、Claude、CursorなどのAIアシスタントをリアルタイムのWebデータに接続し、ライブページを読み取りながら、チャット画面を離れることなく構造化データを自動取得可能。手作業での情報収集やコピペ作業を削減し、競合調査、価格モニタリング、リード収集、市場分析などをより効率的かつスピーディーに行えます。
Octoparseを使ったデータ抽出の手順──テンプレートで即スタート
OctoparseはInstant Data Scraperよりも高機能ですが、テンプレートを使えばインストールから最初のデータ取得まで数分以内に完了します。以下は基本的な流れです。
- Octoparse公式サイトから無料アカウントを作成する(クレジットカード不要)
- デスクトップアプリをダウンロード・インストールしてログインする
- 「テンプレート」タブを開き、取得したいサイトに対応するテンプレートを選択する。ここで例をとして、Twitterのデータを抽出するテンプレートを選びます。
- 抽出したデータを入力してから「実行」をクリックするだけでデータ収集が始まる。ここでは開始日付と終了日付、抽出したいキーワードなどを入力しました。
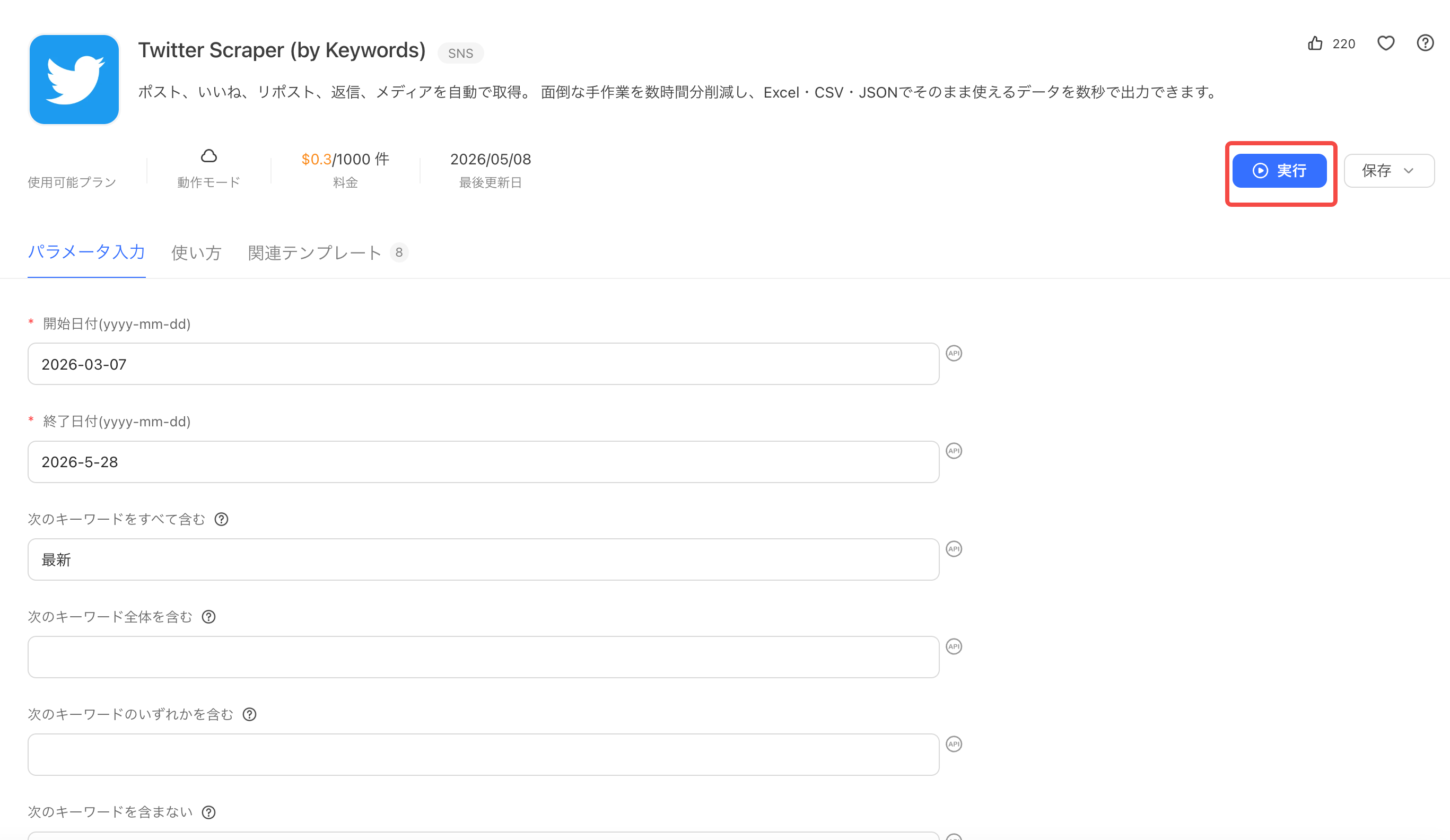
- 完了後にCSV・Excelなどでエクスポートする
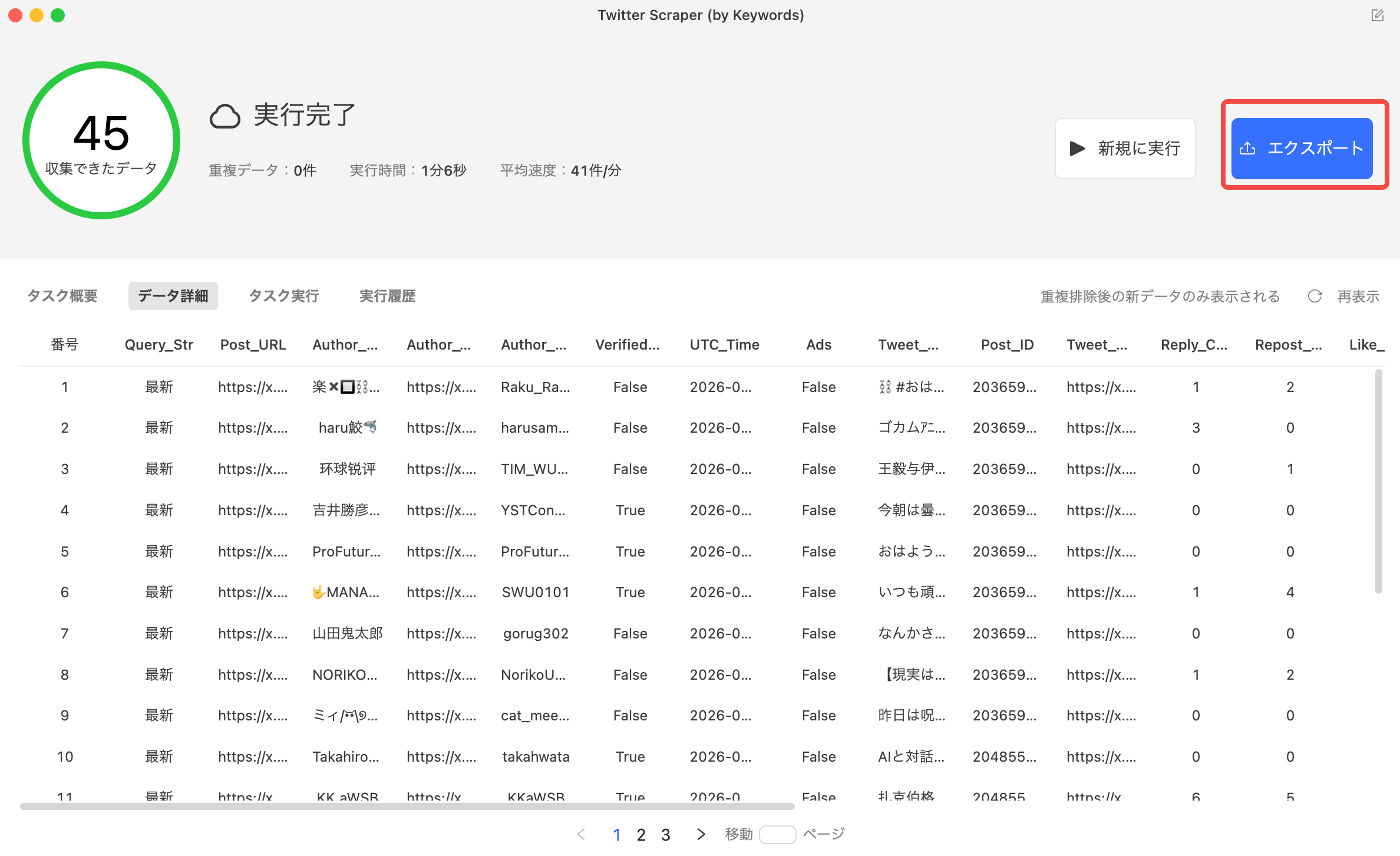
たとえば、食べログのレストラン一覧テンプレートを使えば、エリア・ジャンル・評価・予算・営業時間などのデータフィールドを入力するだけで自動取得できます。同様に、IndeedのJP求人情報テンプレートでは求人タイトル・会社名・給与・勤務地・URLなどが一括取得可能です。
https://www.octoparse.jp/template/indeed-job-listing-scraper-jp-by-keywords
さらに、テンプレートにないケースでも、クリック操作ベースで抽出ルールを自由にカスタマイズ可能。取得したい項目(価格、商品情報、レビュー、連絡先、リストデータなど)やページ遷移、ログイン、無限スクロール、ページネーションなども柔軟に設定でき、プログラミング不要で目的に合わせたWebデータ収集を実現します。
Instant Data Scraperでうまくいかないときの対処法──よくあるトラブル3選
Instant Data Scraperを使っていて「うまくデータが取れない」と感じるケースには、ほぼ共通のパターンがあります。以下に実際のユーザーが遭遇しやすい3つのトラブルと対処法をまとめました。
トラブル①:拡張機能を起動しても何もハイライトされない・ポップアップが空白のまま
原因:ページがJavaScriptで動的に描画されているため、Instant Data ScraperのAIが構造化データを検出できていない状態です。
対処法:
- ページが完全に読み込まれるまで数秒待ってから再度拡張機能を起動する
- 「Try Another Table」を数回クリックして候補を切り替える
- それでも解決しない場合は、そのサイトはInstant Data Scraperの対応範囲外の可能性が高い。
トラブル②:データは取れるが一部の列が空白・欠損している
原因:取得したいデータの一部が後から非同期でロードされる「遅延読み込み」方式のため、AIが検出した時点ではデータがまだ表示されていない状態です。
対処法:
- ページを最下部までスクロールしてすべてのコンテンツを読み込んでから拡張機能を起動する
- 画像や価格など遅延読み込みが多い項目は、ページをリロード後に少し待ってから実行する
- 根本的な解決策として、OctoparseはJavaScript実行を待ってからデータ取得するため欠損が起きにくい
Instant Data Scraperのよくある質問
Q1. Instant Data ScraperはEdgeやFirefoxでも使えますか?
Instant Data ScraperはGoogle Chrome専用の拡張機能です。Microsoft EdgeはChromiumベースのため「EdgeアドオンとしてChromeウェブストアの拡張機能を許可する」設定を有効にすれば動作する場合がありますが、公式サポートはChromeのみです。FirefoxおよびSafariには対応していません。
Q2. Instant Data Scraperは安全ですか?個人情報は収集されますか?
ChromeウェブストアのInstant Data Scraperの開示情報によると、取得したデータは第三者への販売・中心機能以外への転用はしないと明記されています。ただし、拡張機能はウェブ閲覧履歴へのアクセス権限を持ちます。業務上の機密データを扱うサイトで使用する場合は、データがローカルで完結するOctoparseのデスクトップ版のほうが安心感があります。
Q3. Instant Data Scraperでログインが必要なページはスクレイピングできますか?
事前にChromeでそのサイトにログインした状態であれば、ログイン後のページにもアクセスできます。ただし、二段階認証・CAPTCHA・厳しいセッション管理が設定されているサイトでは正常に動作しないケースがほとんどです。そのようなサイトにはOctoparseが適しています。
Q4. Instant Data Scraperで取得できるデータ件数に上限はありますか?
公式の明示はありませんが、コミュニティの報告では1回の取得上限は約1,000件とされています。それ以上のデータが必要な場合は、Octoparseの無料プラン(1万件まで対応)への移行をおすすめします。
関連記事
まとめ:Web Scraper 使い方ガイドのポイント
この記事では、Chrome拡張機能Instant Data Scraperの使い方をを解説しました。最後に要点を整理します。
- ✅ Instant Data Scraperは完全無料・登録不要・コーディング不要でWebデータを抽出できるChrome拡張機能
- ✅ 静的ページ・商品一覧・求人リストなどシンプルな構造のサイトに特に有効
- ✅ ページネーション・無限スクロールに対応し、複数ページを自動巡回できる
- ✅ CSV・XLSX形式でエクスポートしてGoogleスプレッドシートやExcelにすぐ活用できる
- ⚠️ 動的サイト・大量データ定期取得・スケジュール実行はInstant Data Scraperでは対応不可
もし各原因でInstant Data Scraperを使いたくなくてその代替ツールを探す場合、Web ScraperまたはOctoparseのようなデータスクレイピングツールがたくさんあるので、ぜひ自分のニーズに応じて最適なものをご利用ください。