PythonでWebスクレイピングを行う方法には、requestsやBeautifulSoupを使う方法、Scrapyを使う方法、そしてSeleniumでブラウザを自動操作する方法があります。
この中でSeleniumが特に役立つのは、JavaScriptによってデータが後から表示されるページや、検索条件の入力、ボタンのクリック、スクロールなど、ブラウザ上の操作が必要なページです。ブラウザではデータが見えているのに、通常のHTML取得では空白になる場合、Seleniumを使うことで取得できる可能性があります。
本記事では、PythonでSeleniumを使う具体的なスクレイピング使い方を、インストールから実践でつまずきやすいポイントに絞って解説します。環境構築、要素の取得、待機処理、CSV保存、クリック・スクロール操作、よくあるエラーの確認方法まで順番に見ていきましょう。なお、コードを書かずに同じようなデータを取得したい場合の選択肢についても、記事の中で比較しながら紹介します。
Seleniumとは?できることは?
Seleniumは、Chrome、Firefox、EdgeなどのWebブラウザをプログラムから操作できるオープンソースツールです。もともとはWebアプリケーションの自動テストでよく使われてきましたが、実際のブラウザを起動してページを表示できるため、動的なWebページのスクレイピングにも活用されています。
Python×Seleniumの組み合わせでできることを紹介すると、主に次の4つです。
- Webスクレイピング:JavaScriptで表示されるデータや、クリック・スクロール後に表示される情報を取得する
- ブラウザの自動操作:フォーム入力、ログイン処理、ページ遷移などを自動化する
- Webアプリケーションの自動テスト:操作シナリオを記述し、画面の挙動を自動確認する
- 定型作業の自動化:検索、データ収集、スクリーンショット取得など、繰り返し作業を自動化する
Seleniumでは、URLを開く、フォームに文字を入力する、ボタンをクリックする、ページをスクロールする、表示されたテキストやリンクを取得するといった操作をPythonコードで実行できます。
PythonとSeleniumの環境構築とインストール方法は?
PythonでSeleniumを使ってスクレイピングを始めるには、次の3ステップで環境を説明します。
STEP1. Pythonのインストール確認
Pythonがすでにインストールされているか、コマンドプロンプトまたはターミナルで確認します。バージョンが表示されない場合は、Python公式サイトから最新版をダウンロードしてインストールしてください。
STEP2. Seleniumのインストール
Pythonの準備ができたら、pipコマンドでSeleniumをインストールします。「Successfully installed selenium-x.x.x」のように表示されれば、インストールは完了です。バージョンを確認したい場合は、以下のコマンドで確認できます。
⚠️ Selenium 3とSelenium 4で書き方が異なる点に注意
ネット上のサンプルコードには、古いSelenium 3の書き方(find_element_by_idやfind_element_by_class_nameなど)がまだ多く残っています。現在の主流であるSelenium 4以降では、要素の指定にByクラスを使う書き方に統一されています。
コピペしたコードが動かない場合、まずはこのバージョン差が原因になっていないかを確認しましょう。
STEP3. ChromeDriver(WebDriver)について
SeleniumでChromeを操作するには、「ChromeDriver」というブラウザ専用ドライバーが必要です。Selenium 4.6以降では、Selenium ManagerによってChromeDriverの管理が自動化されているため、多くの場合、以下のシンプルなコードだけでChromeを起動できます。
一方で、社内ネットワークやプロキシ環境などでドライバーの自動取得がうまくいかない場合は、手動でChromeDriverを指定する方法や、webdriver-managerライブラリを使う方法もあります。手動でのインストール手順や具体的なコード例は、後述の「実践2」で詳しく紹介します。まずは上記のシンプルなコードで動作確認してから、必要に応じて手動設定を検討するのがおすすめです。
Seleniumを使うべきページ・使わなくてもよいページ
Pythonでスクレイピングする場合、すべてのページでSeleniumを使う必要はありません。Seleniumは便利ですが、実際のブラウザを起動するため、軽量なHTML取得よりも処理が重くなります。まずは対象ページの性質を確認し、必要な場合にだけSeleniumを使うのが効率的です
| ページの状態 | おすすめの方法 | 理由 |
|---|---|---|
| HTMLソースに必要なデータが含まれている | requests + BeautifulSoup | 軽くて速く、ブラウザ起動が不要 |
| JavaScript実行後にデータが表示される | Selenium | 実際のブラウザで表示後のDOMを取得できる |
| 検索フォーム、クリック、タブ切替が必要 | Selenium | 人間の操作に近いブラウザ操作を自動化できる |
| APIや公式データ提供がある | API利用を優先 | 安定性・合法性・メンテナンス性が高い |
| 短時間に大量取得したい | 取得範囲と頻度を再設計 | Seleniumだけで大量取得すると負荷やエラーが出やすい |
Seleniumの基本操作
| 操作 | コード例 | 用途 |
| ページを開く | driver.get(“URL”) | 対象ページへアクセスする |
| 要素を探す | driver.find_element(By.CSS_SELECTOR, “.item”) | 1つの要素を取得する |
| 複数要素を探す | driver.find_elements(By.CSS_SELECTOR, “.item”) | 一覧データをまとめて取得する |
| テキスト取得 | element.text | 画面に表示されている文字を取得する |
| 属性取得 | element.get_attribute(“href”) | リンクURLや画像URLを取得する |
| クリック | element.click() | ボタンやリンクを押す |
| 入力 | element.send_keys(“キーワード”) | 検索フォームに文字を入力する |
| スクロール | driver.execute_script(“window.scrollTo(0, document.body.scrollHeight);”) | 下部読み込みや遅延表示を確認する |
Selenium 4では、要素の指定に By を使う書き方が基本です。古い記事で見かける find_element_by_id やfind_element_by_class_name のような書き方ではなく、以下のように記述します。
実践1:JavaScriptで表示されるデータを取得する
ここでは、学習用サイト「Quotes to Scrape」のJavaScript版ページを例に、Seleniumで表示後のデータを取得し、CSVに保存する流れを紹介します。実際の業務サイトで試す場合は、必ず利用規約、アクセス頻度、著作権、個人情報の取り扱いを確認してください。
取得するデータ
- 引用文
- 著者名
- タグ
サンプルコード
コードのポイント
- webdriver.Chrome() でChromeを起動します。Selenium 4.6以降では、基本的にSelenium Managerがドライバーを自動管理します。
- WebDriverWait を使い、.quote 要素が表示されるまで待機します。
- find_elements で引用ブロックをまとめて取得し、各ブロック内から引用文、著者名、タグを取り出します。
- CSVはExcelで開きやすいように utf-8-sig で保存します。
- finally で driver.quit() を実行し、処理終了時にブラウザを閉じます。
実際にこのコードをローカル環境(Python 3.11、Selenium 4系)で実行したところ、約3〜4秒の待機で全件のデータ取得が完了しました。ページの読み込み速度によって待機時間は変動するため、WebDriverWaitのタイムアウト値は対象サイトに応じて調整してください。
time.sleepではなくWebDriverWaitを使う理由
初心者向けのサンプルでは time.sleep(3) のように固定秒数待つコードもよく見かけます。しかし、動的ページでは回線速度やサーバー応答、JavaScriptの実行タイミングによって、データが表示されるまでの時間が変わります。
そのため、実務では「3秒待つ」のではなく、「必要な要素が表示されるまで最大10秒待つ」という考え方にしたほうが安定します。これがWebDriverWaitです。
Selenium公式ドキュメントでも、明示的な待機処理では WebDriverWait を使い、条件が満たされるまで待つ形が紹介されています。固定秒数の待機だけに頼ると、ページによっては速すぎたり遅すぎたりするため、取得漏れや無駄な待機が発生しやすくなります。
クリック・入力・スクロールが必要な場合
Seleniumの強みは、単にHTMLを取得するだけでなく、ブラウザ上の操作を自動化できる点です。検索条件を入力する、ボタンを押す、下までスクロールするなど、人間が画面上で行う操作をコード化できます。
検索フォームに入力する例
ボタンをクリックする例
button = driver.find_element(By.CSS_SELECTOR, “.search-button”)
button.click()
ページ下部までスクロールする例
driver.execute_script(
“window.scrollTo(0, document.body.scrollHeight);”
)
無限スクロール型ページでは、1回スクロールしただけでは全データが表示されないことがあります。その場合は、スクロール後に新しい要素が増えたか確認しながら繰り返す必要があります。ただし、必要以上にスクロールを繰り返すと対象サイトに負荷をかけるため、取得件数や実行回数の上限を決めておきましょう。
CSSセレクターを選ぶコツ
Seleniumでデータを取得する際は、どの要素を取得するかをCSSセレクターやXPathで指定します。安定したスクレイピングには、セレクター選びが重要です。
| セレクター | 例 | 特徴 |
| ID | #product-title | 一意であれば安定しやすい |
| class | .price | 複数要素の取得に便利。ただしデザイン変更で変わることがある |
| 属性 | a[href] | リンクや画像など、属性を持つ要素の抽出に便利 |
| 親子関係 | .item .name | 一覧内の特定項目を取りたいときに使いやすい |
| XPath | //div[@class=”item”] | 複雑な条件指定ができるが、長すぎるとメンテナンスしにくい |
Chrome DevToolsで対象要素を確認し、できるだけ意味のあるclass名やdata属性を使うと、ページ変更の影響を受けにくくなります。自動生成されたような長いclass名や、階層に依存しすぎるXPathは、ページの小さな変更で壊れやすいため注意が必要です。
実践2【サンプルコード付き】SeleniumでChromeブラウザを操作する方法
ChromeDriverのインストール
SeleniumでChromeブラウザを操作するには、「ChromeDriver」と呼ばれる専用ドライバーが必要です。手動でインストールする場合は、まず自分のChromeのバージョンを確認し、以下の公式サイトから対応するChromeDriverをダウンロードします。
Chrome Driver: https://chromedriver.chromium.org/downloads
ダウンロードしたzipファイルを解凍し、chromedriverという名前の実行ファイルが確認できれば準備完了です。なお、後述のサンプルコードではwebdriver-managerを利用するため、環境によってはChromeDriverを自動で管理できます。
Chromeブラウザを自動起動してGoogleを開く
それでは、実際にブラウザを自動起動してWebページを開いてみましょう。
以下は、Googleのトップページを表示させる基本的なスクリプトです。テキストエディタを起動し、ファイルを「.py」という拡張子で保存します。
コマンドプロンプトを起動し、保存したファイルのあるディレクトリへ移動したうえで「python ◯◯.py」と入力して実行します。
以下のようなウィンドウが表示されれば成功です。
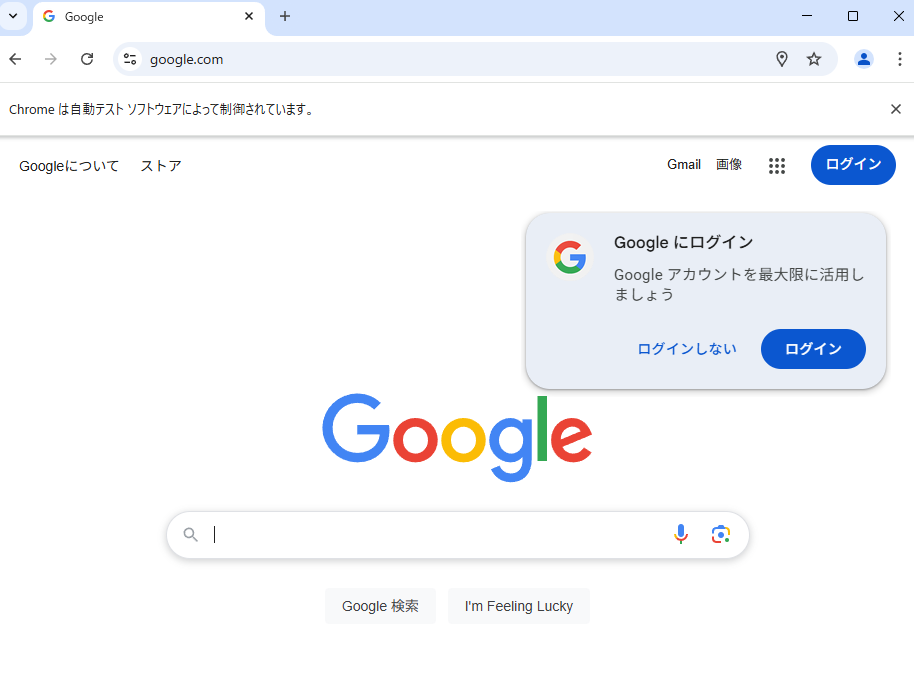
Google検索結果を取得する
次に、任意のキーワードでGoogle検索を行う操作を自動化してみましょう。
以下のコードをコピペして実行してください。
以下のように、自動で検索結果画面まで遷移すれば成功です。
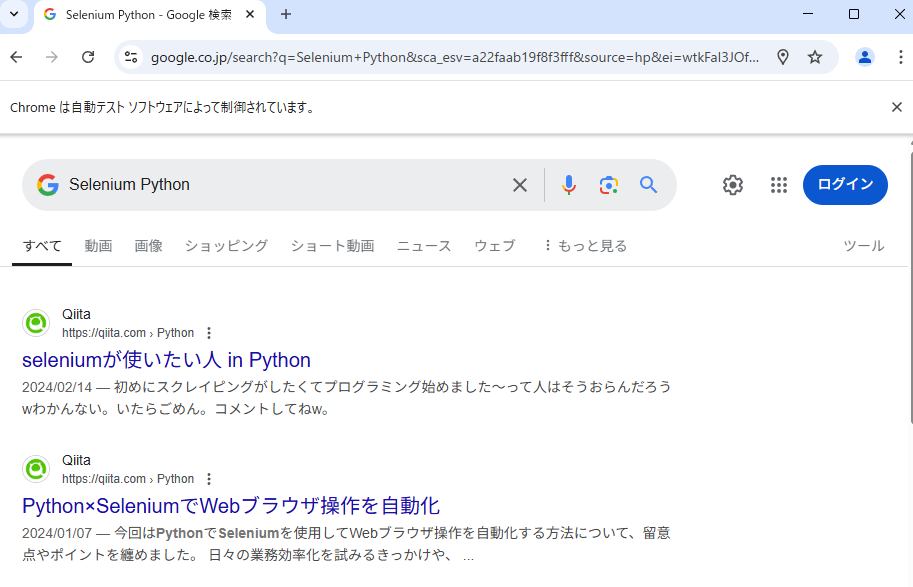
Octoparseでスクレイピングする方法(Selenium不要)
Seleniumは柔軟性が高く、複雑な処理にも対応できる一方で、Pythonの知識や実行環境の構築、コードの保守が必要になります。特に、サイト構造の変更に応じてセレクターの修正やデバッグが発生するため、継続的な運用には一定の技術的な負担が伴います。
一方、Octoparseではプログラミング不要で、画面上のクリック操作だけで取得したいデータを指定できます。ページ内のデータを自動検出できるため、Webスクレイピングの経験がない方でも短時間でデータ収集を開始できます。また、定期実行やクラウド抽出機能が標準で利用できるため、Seleniumでスケジューラーを構築する場合と比べて運用負荷を大幅に抑えられます。
さらに、OctoparseはMCP(Model Context Protocol)にも対応しており、対応するAIアシスタントからデータ収集タスクを直接実行できる環境も提供しています。まずは14日間の無料トライアルで主要機能を試せるため、「コードを書く前に手軽にデータ収集を始めたい」「まずは結果を確認してから本格導入を検討したい」という方にも適しています。ここでは、既存の画面イメージに沿って基本的な操作手順を紹介します。
- URLの入力
Octoparseを起動し、検索ウィンドウからスクレイピングしたいWebページのURLを入力します。その後、「スタート」をクリックします。
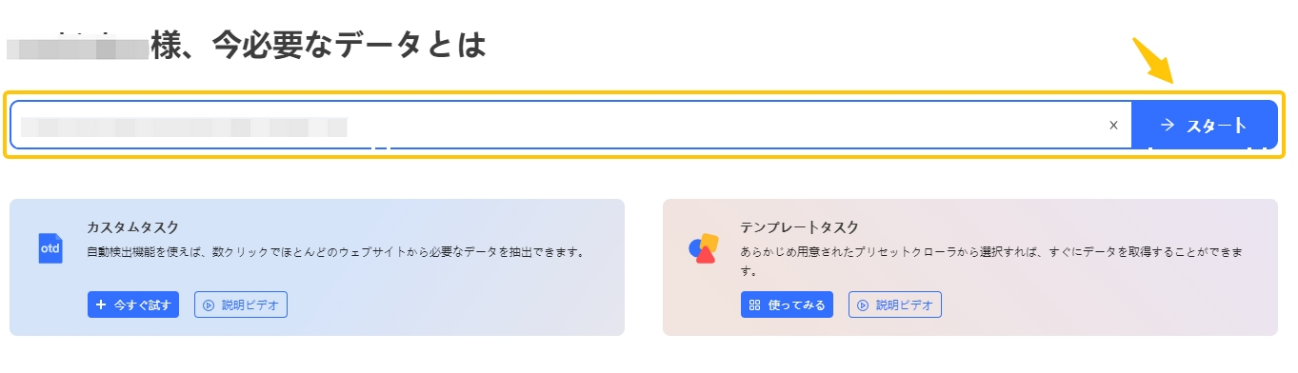
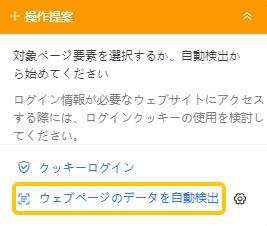
- データ検出
「ウェブページのデータを自動検出」を選択します。すると、ページ上のデータが自動的に検出されます。
「次のページ」や「スクロールダウン」後の情報も取得したい場合は、操作提案上の指示に従ってスクロールダウンやページネーションを設定できます。
たとえば、Amazonの商品データを取得したい場合は、用意されているhttps://www.octoparse.jp/template/amazon-jp-review-details-scraper Amazonスクレイパーテンプレートを使えば、ASIN・商品名・価格・画像URL・在庫状況・出品者情報などのデータをワークフローを自分で組まずに取得できます。SNSデータの収集を検討している場合は、https://www.octoparse.jp/template/twitter-scraper-by-keywordsX(Twitter)スクレイパーテンプレートで、ユーザー名・投稿テキスト・画像・いいね数・リツイート数・フォロワー数を取得することも可能です。
SeleniumとOctoparseの比較|どちらを選ぶべきか
ここまで、PythonとSeleniumを使ったスクレイピングの手順を解説してきました。環境構築やコードの記述に一定の時間がかかることを実感した方も多いのではないでしょうか。
ここで一度、Seleniumでの自作と、ノーコードツール「Octoparse」を使う方法を、複数の観点から比較してみましょう。
| 比較項目 | Selenium(Python) | Octoparse |
|---|---|---|
| プログラミング知識 | 必要(Python・CSS/XPathの理解) | 不要(クリック操作で設定) |
| 環境構築 | Python・Selenium・ChromeDriverの準備が必要 | インストールのみで開始可能 |
| 学習コスト | 中〜高(待機処理・セレクター設計の理解が必要) | 低(数十分で基本操作を習得可能) |
| 動的ページへの対応 | ◯(コードで個別に対応) | ◯(自動識別機能で対応) |
| サイト変更時のメンテナンス | 自分でコードを修正する必要がある | テンプレート提供サイトは自動更新 |
| 大量・定期実行 | 自分でスケジューラーを実装する必要がある | クラウド実行・スケジュール機能が標準搭載 |
| AIとの連携 | 別途実装が必要 | MCP対応でAIアシスタントから直接実行可能 |
| 向いている人 | エンジニアで細かいロジックを制御したい方 | コードを書かずに早くデータ収集を始めたい方(個人から大企業まで) |
表からもわかるように、Seleniumは「処理の自由度」を重視する方に向いており、Octoparseは、プログラミングの知識がなくても大量のデータ収集を効率化したい方や、AIを活用してWebデータをより簡単に抽出・自動化したい企業・個人ユーザーに適しています。特に、サイトのHTML構造が変わるたびにコードを修正する手間や、複数サイトを定期的に巡回する運用負荷を考えると、ビジネス用途では後者を選ぶケースも少なくありません。
また、取得したデータをAIエージェントに直接渡して分析・活用したい場合は、OctoparseのMCP Serverを使う方法もあります。ChatGPTやClaudeなどのAIアシスタントに接続するだけで、「Amazonで人気の◯◯上位5件を教えて」といった自然言語の指示だけで、構造化されたデータをそのまま取得できます。設定方法はMCPの使用教程、MCPの概要については「 MCPとは」の解説記事で詳しく解説しています。
よくあるエラーと確認ポイント
| 症状 | よくある原因 | 確認・対処 |
| 取得結果が空白になる | JavaScript表示前に取得している | WebDriverWaitで対象要素の表示を待つ |
| NoSuchElementException | セレクターが間違っている、要素がまだ表示されていない | DevToolsでセレクターを確認し、待機処理を追加する |
| TimeoutException | 指定した要素が時間内に表示されない | URL、セレクター、読み込み条件、ログイン状態を確認する |
| ElementClickInterceptedException | 別の要素やポップアップが重なっている | ポップアップを閉じる、スクロールしてからクリックする |
| 文字化けする | CSVの文字コードがExcel向けでない | utf-8-sigで保存する |
| 403・429・CAPTCHAが出る | アクセス頻度が高い、対象サイトの制限に触れている | 取得範囲、待機時間、同時実行数、利用規約を見直す |
403・429エラーやCAPTCHAが頻発する場合は、待機時間やUser-Agentの見直しだけでは解決しないこともあります。より詳しい回避策は、スクレイピングのブロック回避方法|原因・対策・Octoparseでの設定手順を解説でも紹介しています。
ヘッドレスモードで実行する方法
ブラウザ画面を表示せずに実行したい場合は、ヘッドレスモードを使えます。サーバー上で定期実行したい場合や、画面を開かずに処理したい場合に便利です。
ただし、ヘッドレスモードでは通常表示と挙動が異なるサイトもあります。まずは画面ありで動作を確認し、正常に取得できることを確認してからヘッドレスモードに切り替えるとよいでしょう。
Seleniumでスクレイピングするときの注意点
- 検知を無理に回避することを目的にせず、対象サイトへの負荷を抑えた設計にする
- 短時間に大量アクセスせず、待機時間や取得件数の上限を設定する
- 画像、口コミ、記事本文、個人情報などを扱う場合は、利用目的と権利関係を確認する
- 対象サイトにAPIやデータ提供サービスがある場合は、そちらを優先する
- HTML構造が変わるとセレクターが使えなくなるため、定期的なメンテナンスを前提にする
Seleniumでスクレイピングする前に確認すること
- 対象サイトの利用規約やrobots.txtを確認する
- ログインが必要なページの場合、取得・利用が許可されているデータか確認する
- ページの「ソースを表示」とChrome DevToolsの「Elements」で、データの表示タイミングを比べる
- Networkタブで公式APIやXHR通信が使えるか確認する
- 取得対象を必要最小限に絞り、アクセス間隔を空ける
特に「ブラウザでは見えるのに、取得結果が空白になる」場合は、ページ読み込み直後にはデータが存在せず、JavaScript実行後に追加されている可能性があります。このようなケースでは、Seleniumでページを開いたあと、必要な要素が表示されるまで待機してから取得することが重要です。
Seleniumのユースケース・活用事例
次に、Seleniumがよく使われる場面を紹介します。Seleniumは、単にHTMLを取得するだけでなく、ブラウザ上の操作を伴うページで特に力を発揮します。
- ID・パスワードの入力やログインボタンのクリックなど、人間が行う一連の操作を自動化できます。ログイン後に表示されるページのデータ取得を検討する場合に役立ちます。具体的な実装パターンは、ログインが必要なサイトでスクレイピングする際の課題と対策でも詳しく解説しています。
- 無限スクロールページの対応
SNSやECサイトに多い「下までスクロールすると次のデータが読み込まれる」形式のページでも、スクロール操作を自動化することでデータを取得しやすくなります。
- Webアプリケーションの自動テスト
テストケースを作成し、Seleniumでテストスクリプトを実行することで、ブラウザ上での操作確認を自動化できます。
Seleniumの弱点や負荷については、文末のFAQでまとめて解説します。ここからは、実際の環境構築とコードの書き方を見ていきましょう。
よくある質問
Q1.Seleniumでスクレイピングは禁止されていますか?
Selenium自体の利用や、スクレイピングという行為そのものは法律で一律に禁止されているわけではありません。ただし、対象サイトの利用規約でスクレイピングを禁止している場合や、robots.txtで制限が示されている場合は、それに従う必要があります。また、短時間に大量アクセスを行うとサーバーへの負荷や不正アクセスとみなされるリスクもあるため、アクセス頻度の調整や利用規約の確認は事前に行いましょう。より詳しいルールについては、スクレイピングのよくある誤解10選【2026年版】でも解説しています。
Q2.PythonのSeleniumはスクレイピングに使えますか?
はい、使えます。Seleniumは実際のブラウザを起動してページを表示できるため、通常のHTML取得(requestsなど)では空白になってしまう、JavaScriptで後から表示されるデータの取得に適しています。一方で、静的なページや大量データの高速取得には、軽量なrequestsやBeautifulSoupのほうが向いている場合もあります。対象ページの性質に応じて使い分けることが重要です。
Q3.SeleniumとBeautifulSoupは併用できますか?
はい、併用可能です。Seleniumでブラウザを操作してJavaScript実行後のページを表示させ、driver.page_sourceで取得したHTMLをBeautifulSoupに渡して解析する、という組み合わせがよく使われます。Seleniumは「ページを表示・操作する」役割、BeautifulSoupは「表示されたHTMLから必要な情報を抜き出す」役割と考えるとわかりやすいでしょう。
Q4.Seleniumは重いと聞きましたが、本当ですか?
はい。Seleniumは実際のブラウザを起動して操作するため、RequestsやBeautifulSoupのような軽量ライブラリと比べると動作は重くなりやすいです。その分、動的ページや操作が必要なページに対応しやすいというメリットがあります。処理速度を重視する場合は、ヘッドレスモードを使う、必要最小限の箇所だけSeleniumを使うなどの工夫で改善できます。
まとめ
本記事では、PythonでSeleniumを使ったWebスクレイピングのインストール手順から、基本操作、エラー対処までを解説しました。Seleniumは、ブラウザ操作を自動化できるため、JavaScriptで表示される動的ページや操作が必要なページのデータ取得に向いています。とくに、Selenium 4以降の書き方やWebDriverWaitによる待機処理を正しく理解することが、エラーを減らす近道です。
一方で、Seleniumを使うにはPythonの基礎知識や環境構築が必要であり、サイト構造が変わった際のメンテナンスも前提になります。できるだけ手軽に、かつ継続的にWebスクレイピングを運用したい場合は、Octoparseのようなノーコードツールを使う方法もあります。目的やスキル、運用の継続性に応じて、自分に合った方法を選びましょう。

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール



