結論からお伝えすると、Chrome拡張機能「Web Scraper」はコードなしでWebデータを収集できる入門向けツールですが、動的サイト・定期自動収集・大量データには限界があります。この記事では、Web Scraperのインストールから実際のデータ収集・CSV出力までの使い方をステップバイステップで解説し、さらに「Web Scraperでは難しい」と感じたときの代替手段まで正直に比較します。「とにかく今日中にデータを抜きたい」という方はステップ2のインストール手順からお読みください。
Octoparse編集部では、Web Scraper・Octoparse・Pythonなど複数の手法で実際にデータ収集を行い、ツールの挙動・制限・使い勝手を比較検証しています。本記事はその経験をもとに、日本のユーザーが現場で直面しやすい「サイトマップが作れない」「ページネーションがうまく取れない」「動的サイトで止まる」といった実際の問題点も含めて解説しています。
「Web Scraper」とは?Chrome拡張機能でデータスクレイピングできる仕組み
Web Scraperは、ラトビア発のスタートアップ「webscraper.io」が開発したChrome向けデータスクレイピング拡張機能です。2026年4月時点でChromeウェブストアに90万人以上のユーザーを抱え、コードを書かずにWebサイトのデータ収集ができるツールとして世界中で利用されています。
仕組みはシンプルで、Chromeの開発者ツール(デベロッパーツール)のパネルとして動作し、「サイトマップ」と呼ばれる収集ルールを設定することでデータを自動抽出します。PythonやJavaScriptの知識は不要で、マウス操作だけで商品名・価格・URLなどの情報を一括取得できるのが最大の特徴です。
Web Scraperでできること・できないこと
| 項目 | できること | できないこと・苦手なこと |
|---|---|---|
| 対象サイトの種類 | 静的ページ、シンプルな一覧ページ | JavaScriptで遅延読み込みされる動的ページ |
| 取得できるデータ型 | テキスト・リンク・画像URL・テーブルデータ | PDFの中身、画像ファイルの直接DL |
| ページネーション対応 | 「次のページ」ボタンが存在するサイトは対応可 | 無限スクロール(Infinite scroll)は不安定 |
| スケジュール実行 | 無料プランは不可 | 有料クラウドプランのみ対応 |
| ログインが必要なページ | 手動ログイン後のセッションを利用すれば可能な場合あり | 自動ログインには未対応 |
| 出力形式 | CSV、CouchDB | Excel(.xlsx)の直接出力は不可 |
Chrome拡張機能Web Scraperでデータを収集する方法|インストール〜CSV出力まで
Web Scraperの使い方は大きく「①インストール → ②サイトマップ作成 → ③スクレイピング実行 → ④CSV出力」の4ステップで完結します。以下で各ステップを詳しく解説します。
Google Chromeブラウザがインストールされていれば、追加ソフトのインストールは不要です。Chromeがない場合はまず公式サイトからダウンロードしてください。
Web Scraperはどんな人に合うのか?メリット・デメリットを正直に解説
Web Scraperは「今すぐ、無料で、コードなしにデータを取りたい」というニーズに応える一方で、業務レベルの自動データ収集には明確な限界があります。以下に実際に使って感じたメリット・デメリットをまとめます。
✅ メリット
- 完全無料で今すぐ始められる
- Chromeに追加するだけ・環境構築不要
- コーディング不要・マウス操作だけ
- 静的な一覧ページなら高精度に収集できる
- サイトマップをJSON形式でエクスポート・共有できる
- 90万人以上が使う信頼性のある定番ツール
❌ デメリット
- 日本語の公式ドキュメントがほぼない
- サイトマップの設定に学習コスト(初回30分〜)
- 動的コンテンツ・無限スクロールは苦手
- 定期自動収集は有料プランのみ
- PCを開いた状態でないと実行できない
- 大量ページのスクレイピングはブラウザに負荷
- XPathやCSSセレクターの知識があると効果UP(初心者には難)
Web Scraperが向いている人・向いていない人
| こんな人に向いている | こんな人には向いていない |
|---|---|
| ・スクレイピング初体験で「まず試してみたい」 ・1回限りの少量データ収集(数十〜数百件) ・静的なECサイトや記事一覧から価格・タイトルを取得したい ・プログラミングの勉強前に仕組みを体感したい | ・毎日・毎週の定期的な自動データ収集が必要 ・JavaScriptで動く動的サイトが対象 ・数千〜数万件の大量データを処理したい ・複数サイトを並行してスクレイピングしたい ・チームで作業を分担・共有したい |
Web Scraperでスクレイピングする操作方法を画面付きで解説
ここでは実際のスクレイピング手順を6ステップで解説します。例として「商品一覧ページから商品名・価格・URLを取得する」シナリオを想定しています。
Chromeブラウザで Chrome ウェブストアの「Web Scraper」ページ にアクセスし、「Chromeに追加」ボタンをクリックします。確認ダイアログが表示されたら「拡張機能を追加」を押せばインストール完了。ブラウザ右上のツールバーにクモ
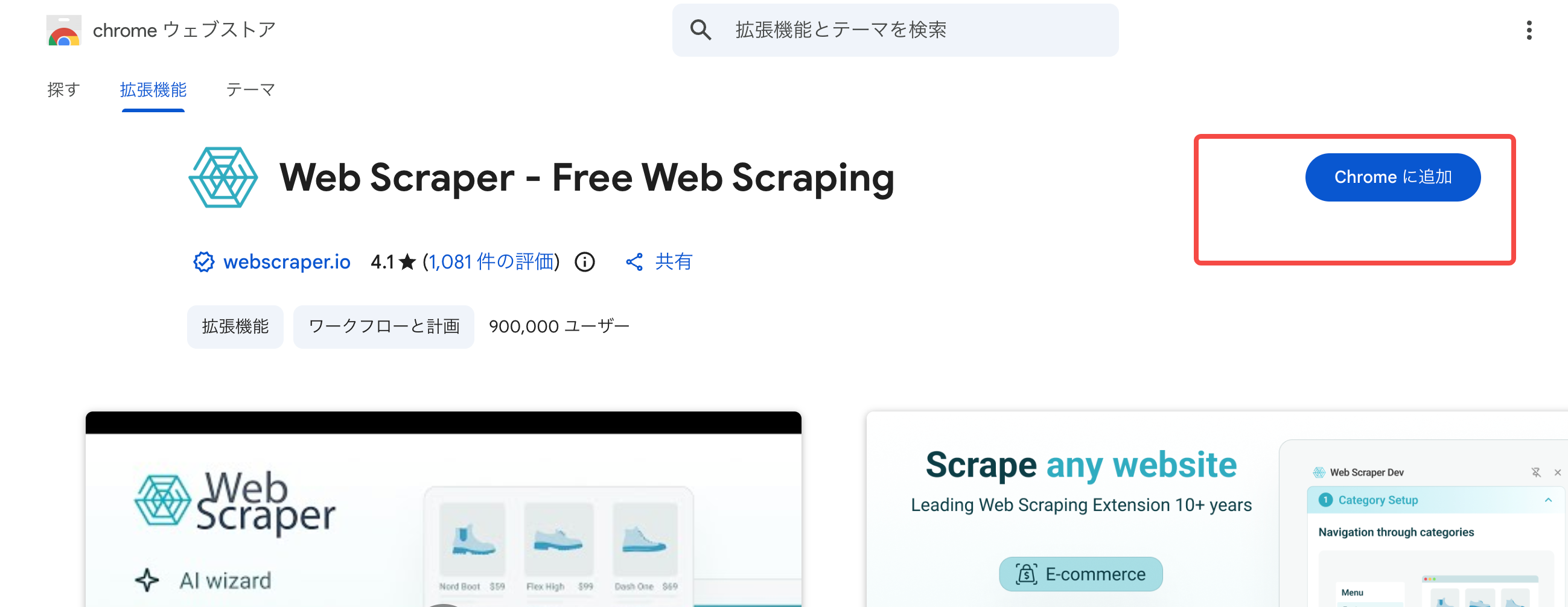
スクレイピングしたいページを開き、キーボードの F12(Macは Command + Option + I)を押してデベロッパーツールを起動します。上部タブの中に「Web Scraper」が追加されているのでクリック。タブが見えない場合は >> ボタンを押すと折りたたまれたタブが表示されます。
- Sitemap name:任意の名前を英数字で入力(例:
product_list)。日本語・記号は避けてください。 - Start URL:スクレイピング対象ページのURLを貼り付けます。
入力後「Create Sitemap」をクリック。これがデータ収集の「設計図」になります。
Sitemap nameに全角文字・スペース・日本語を使うとエラーになります。必ず半角英数字と一部の記号(_、$、-など)を使ってください。
「Add new selector」をクリックして取得したいデータ要素を定義します。
| 設定項目 | 内容 | 例 |
|---|---|---|
| id | この要素の識別名(任意) | product_name |
| Type | 取得するデータ型 | Text(テキスト)、Link(URL)、Image(画像URL)など |
| Selector | 取得したいHTML要素 | 「Select」ボタン押下→ページ上の要素をクリック |
| Multiple | 複数要素を一括取得する場合はON | 商品一覧全件を取得する場合はチェック |
設定後「Save selector」をクリック。商品名・価格・URLなど取得したい項目の数だけこの手順を繰り返します。
Web Scraperの無料プランではCSVを経由してGoogleスプレッドシートへ取り込む必要があります。自動連携を実現したい場合は、スクレイピングデータをGoogleスプレッドシートに自動取り込みする方法もご参照ください。
ページネーション(複数ページ)に対応するには?
「1ページ目だけでなく次のページのデータも全部取りたい」という場合は、セレクター設定にページネーション用のセレクターを追加します。Typeを「Link」に設定し、「次のページ」や「>」ボタンのHTML要素を指定することで自動的に全ページを巡回します。
TwitterやInstagramのようなスクロールするたびに新しいコンテンツが読み込まれるサイトは、Web Scraperでの収集が難しく、エラーや取得漏れが発生しやすいです。そのようなサイトにはOctoparseなどのデスクトップ専用ツールが適しています。
簡単にデータを抽出できる方法は?Web Scraperだけでは足りないときの選択肢
Web Scraperを実際に使ってみると、「動的ページが取れない」「定期自動収集ができない」「大量データで途中で止まる」という壁にぶつかることが多いです。そんなときに検討すべき2つのWeb Scraperの代替選択肢を紹介します。
方法1:専門ツール Octoparse でデータ収集する
「ページを閉じたら収集が止まる」「動的サイトでエラーが出る」「毎日手動で実行するのが面倒」――Web Scraperを使っていてそう感じたことはありませんか?Octoparseはそうした課題を、コードなしで解決できるデータ収集専用ツールです。ブラウザ上の要素をクリックして取得ルールを設定でき、プログラミング知識がなくても比較的扱いやすいのが特徴です。また、テンプレート機能も用意されており、ECサイトや求人サイトなど、よく使われる収集シーンでは設定作業を簡略化できます。
さらに、最近ではMCP機能にも対応しており、AIと連携しながらデータ収集を自動的に行えるようになっています。たとえば、「競合商品の価格を収集したい」「指定サイトから最新情報を取得したい」といった指示をAIに伝え、収集フローをサポートさせることも可能です。従来の手動設定だけでなく、AIを活用したデータスクレイピングを試したい方にとって、選択肢の一つになるでしょう。
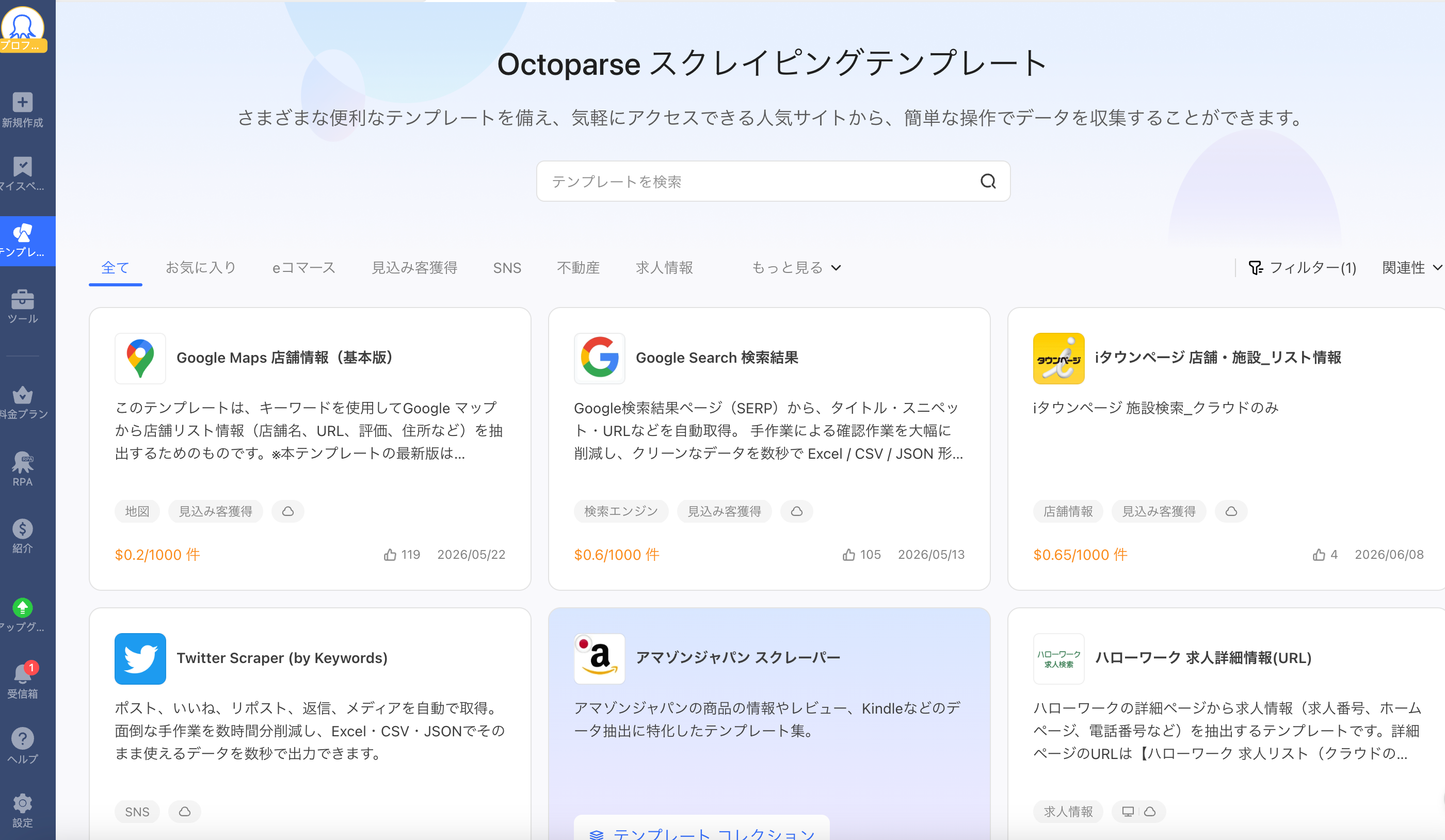
Octoparseの具体的な使い方:スクレイピングで最速3ステップ
Octoparseを起動し、「テンプレートギャラリー」から収集したいデータに合ったテンプレートを選択します。たとえば、X(旧Twitter)の投稿データを取得したい場合は、「Twitter Scraper(by Keywords)」テンプレートを選びます。
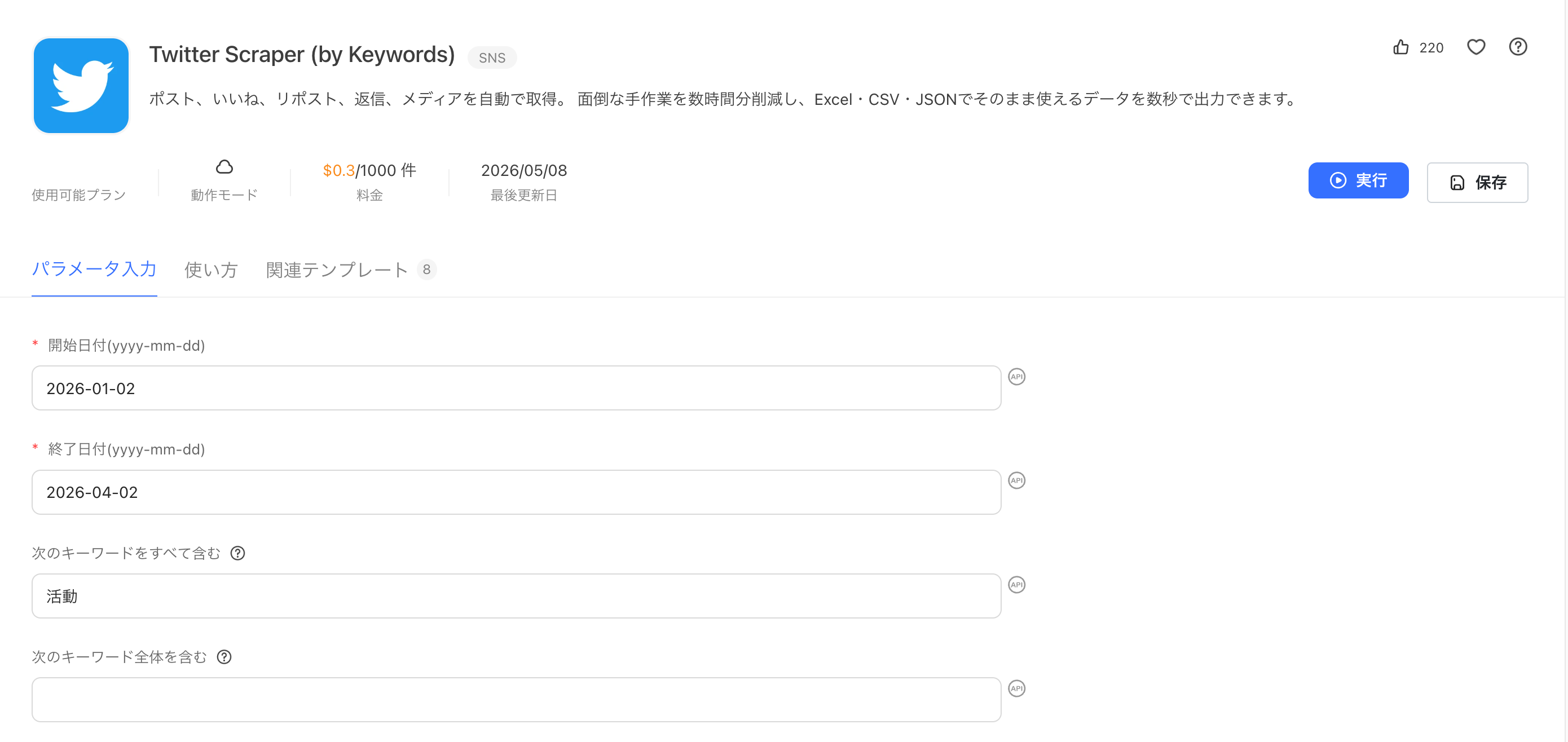
パラメータの設定が完了したら、「実行(Run)」ボタンをクリックしてスクレイピングを開始します。処理完了後、取得データはExcel(XLSX)やCSV形式でエクスポートできます。
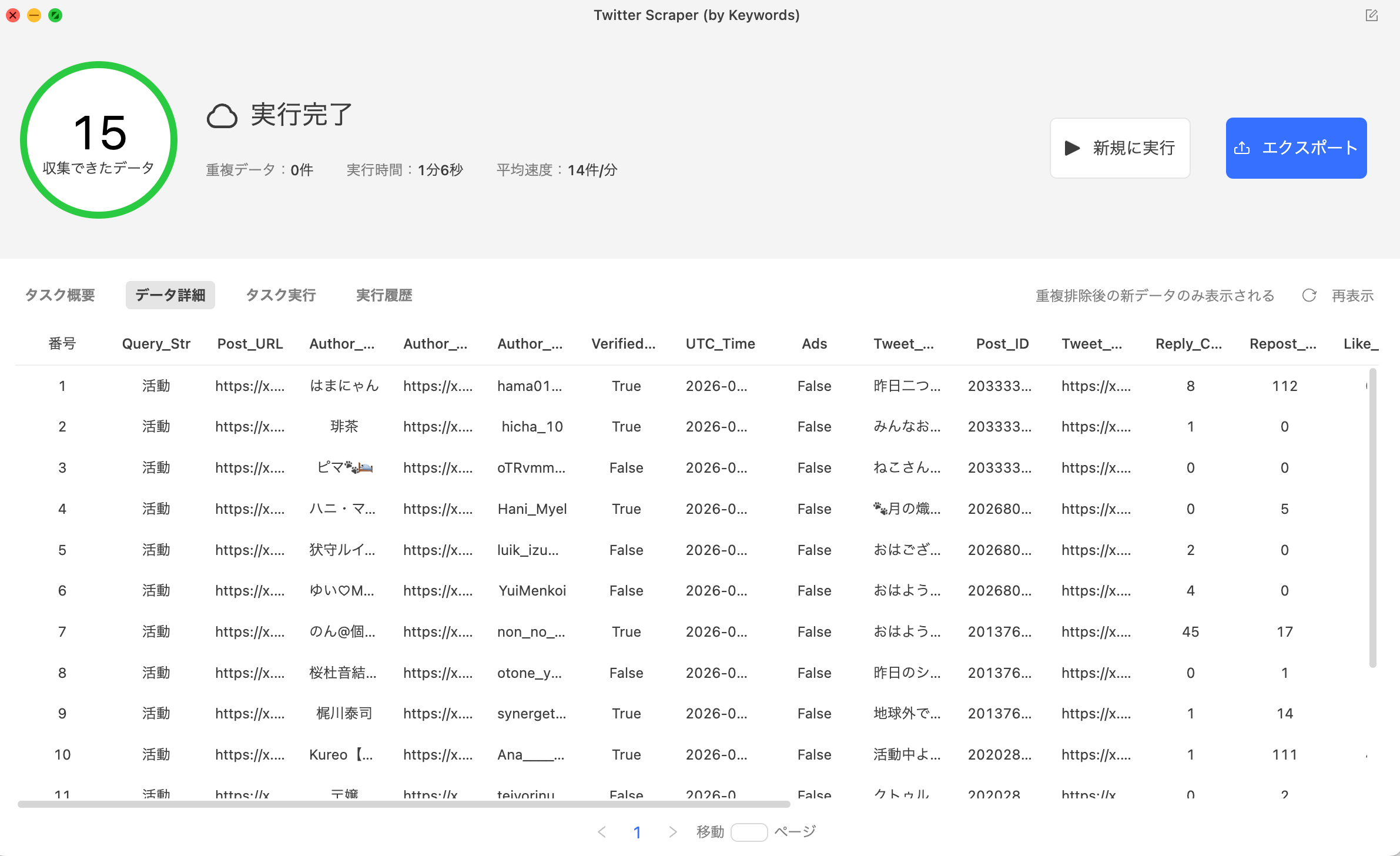
なお、Octoparseは人気サイト向けのテンプレートを利用できるだけではありません。収集したいWebサイトのURLを入力することで、独自のスクレイピング設定を作成することも可能です。
たとえば、商品名・価格・レビュー数のみ取得したい場合など、必要な項目(フィールド)を自由に選択・調整できます。最近ではAIスクレイピング機能やMCP連携にも対応しており、URLを入力してAIに取得項目を提案させながら、データ収集フローを効率的に作成することもできます。テンプレートがないサイトでも、用途に応じて柔軟にデータ収集を行える点が特徴です。
よく使われるサイト向けのスクレイピング設定がテンプレートとして用意されています。以下のような日本の主要サイトにも対応しています:
- SNS・口コミ:SNSデータ収集テンプレート一覧
- 不動産:不動産情報テンプレート一覧
- 全テンプレート:Octoparse テンプレート一覧ページ
方法2:VBAでデータのスクレイピングを実現する
Excelを日常的に使っている方には、VBA(Visual Basic for Applications)でスクレイピングを実装する方法もあります。ExcelのVBAエディタからIEオブジェクト(またはWebRequest)を使ってページの内容を取得し、セルに書き出す方法です。
ただし、VBAによるスクレイピングはMicrosoftが2023年以降Internet ExplorerとIEオブジェクトのサポートを終了しており、現在はPower Queryを利用した代替手法が主流になっています。また、JavaScriptが必要なモダンなサイトにはほぼ対応できません。定期的・大量のデータ収集には向いていないため、「Excelで管理したい」という場合はOctoparseからExcelへのエクスポートを組み合わせる方が現実的です。
Chrome拡張機能Web ScraperとOctoparseの徹底比較
「Web Scraperで始めたけど、Octoparseに移行すべき?」という疑問を持つ方のために、ユーザーが最も気にする観点で中立的に比較しました。
| 比較項目 | Web Scraper(Chrome拡張) | Octoparse(デスクトップ型) |
|---|---|---|
| 費用 | 基本無料(クラウド実行は有料) | 無料プランあり / 有料プランあり |
| インストール | Chromeに追加するだけ(30秒) | デスクトップアプリのDL・インストールが必要 |
| 操作のしやすさ | サイトマップ設定に学習コスト(30分〜) | AIで自動設定 / 直感的なGUI |
| 動的サイト対応 | 一部のみ(JS動的読み込みは苦手) | JavaScript完全対応・無限スクロールも可 |
| ページネーション | 設定すれば対応可 | 自動検出・自動対応 |
| ログイン必要なページ | 手動ログイン後なら可能な場合あり | ログインフロー自動化に対応 |
| スケジュール自動実行 | 有料プランのみ | 無料プランでも一部対応 / クラウドで24時間実行 |
| 処理できるデータ量 | 数百〜数千件(PCスペック依存) | 数万〜数十万件(クラウドなら無制限級) |
| AIスクレイピング | 非対応 | URL貼り付けだけでAIが設定を自動生成 |
| 出力形式 | CSV、CouchDB | CSV、Excel、Google Sheets、API連携 |
| 日本語サポート | 公式日本語ドキュメントほぼなし | 日本語ヘルプセンター・サポートあり |
| テンプレート | なし | Indeed・マイナビ・ハローワーク等の日本サイト対応テンプレートあり |
| こんな人におすすめ | 今すぐ無料で試したい初心者・単発少量収集 | 定期自動収集・動的サイト・大量データが必要なユーザー |
Web Scraperを使っていて「取れないデータがある」「毎回手動で実行するのが面倒」「動的サイトで止まる」と感じたら、Octoparseへの移行を検討するタイミングです。Octoparseは無料プランで試すことができますので、まずは同じサイトで両方を試してみることをおすすめします。
Web Scraperに関するよくあるご質問
Q1. Web ScraperはMacでも使えますか?
はい、Web ScraperはChrome拡張機能のためWindowsとMac両方で使用可能です。Google ChromeブラウザさえインストールされていればOSを問わず動作します。ただし日本語の公式ドキュメントが少ないため、初めての方は英語の公式チュートリアル動画を参考にするか、本記事のように日本語解説を参照してください。
Q2. Web Scraperは無料で使えますか?有料プランとの違いは?
基本機能は完全無料です。ただしクラウドスクレイピング(PCを閉じた状態での自動実行)や大量データの並列処理、スケジュール実行には月額有料プランが必要です。無料でできることは「手動実行・PC起動中のみのスクレイピング・CSVエクスポート」に限られます。定期自動収集が必要な場合はOctoparseなどの代替ツールも比較検討することをおすすめします。
Q3. Web ScraperでJavaScriptが多用されている動的サイトをスクレイピングできますか?
一部の動的コンテンツには対応していますが、完全なJavaScript実行が必要なページや、スクロールで非同期読み込みされるデータは取得できない場合があります。TwitterやInstagram、楽天市場などの高度なJSサイトでは正常に動作しないケースが多いです。そのような場合はOctoparseのデスクトップ版が適しています。Octoparseについては公式サイトをご確認ください。
Q4. Web Scraperでログインが必要なサイトはスクレイピングできますか?
手動でログインした状態のChromeセッションを利用することで、技術的には可能な場合があります。ただし自動でログイン処理を実行する機能は備えていません。また、対象サイトの利用規約でスクレイピングを禁止している場合は利用規約違反になる可能性があるため、必ず確認してから実行してください。
Q5. スクレイピングは法律的に問題ありませんか?
公開されているデータを個人利用や研究目的で収集すること自体は一般的に違法ではありません。ただし、①対象サイトのrobots.txtや利用規約でスクレイピングを禁止していないか、②サーバーへの過度な負荷をかけていないか、③個人情報(氏名・メールアドレスなど)を不正に収集していないか、の3点は必ず確認してください。詳細はWebスクレイピングの違法性と安全に使うためのルールをご参照ください。
Q6. Web Scraperでデータを定期的に自動収集することはできますか?
無料プランでの定期自動収集は基本的にできません。Web Scraperの有料クラウドプランに移行するか、スケジュール実行に標準対応しているOctoparseなどのツールを使う必要があります。「毎日価格を自動収集してスプレッドシートに記録したい」といった用途にはOctoparseのクラウドスクレイピング機能が適しています。
関連記事
まとめ:Web Scraper 使い方ガイドのポイント
- Web Scraperは無料・コードなしでChrome拡張機能として使えるスクレイピングツール
- 「サイトマップ作成 → セレクター設定 → 実行 → CSV出力」の4ステップでデータ収集できる
- 静的ページの少量収集には適しているが、動的サイト・大量データ・定期自動収集には限界がある
- 日本語ドキュメントが少なく、サイトマップ設定には一定の学習コストが必要
- 「Web Scraperでは足りない」と感じたら、AIスクレイピング・クラウド自動実行・日本語サポートを備えたOctoparseへの移行が有力な選択肢
- スクレイピングを行う際は対象サイトの利用規約とrobots.txtを必ず確認する



