率直に申し上げます。スクレイピング ユーザーエージェントの適切な設定がなければ、ブロックは防げません。
プロキシのローテーションやCAPTCHAの処理を行ってもスクレイピングがブロックされる場合、根本的なアプローチに問題があります。
具体的には、ユーザーエージェントの不適切な運用が原因です。
問題の核心は、ユーザーエージェントの仕組みやWebスクレイピングにおける重要性、適切なローテーション方法が十分に理解されていない点にあります。
リクエストごとにランダムなChromeのユーザーエージェントをローテーションさせるだけでは、対策として不十分です。
Webサイト側は送信された文字列だけでなく、パターンや一貫性、情報の不一致、全体的な挙動を監視しています。
例えば、以下のようなケースです。
- 同一のブラウザバージョンで数千ページにアクセスしている
- Windows上のChromeを宣言しているにもかかわらず、ヘッダーの挙動がモバイル版Safariに類似している
- IPアドレスはローテーションされているが、ブラウザのフィンガープリントが変化していない
これらの要因だけで、スクレイパーは容易にブロックされます。
本記事では、ユーザーエージェントの定義とブロックされるメカニズムを解説し、Pythonでの適切な処理方法や、複雑な作業をノーコードツールに任せるべきケースについて説明します。
ユーザーエージェントとは何か?
ユーザーエージェント(UA)とは、ブラウザがWebサイトへのリクエスト時に送信する文字列です。使用しているブラウザやオペレーティングシステム(OS)、ブラウザの挙動をサイト側に伝達する役割を持ちます。
MDNの定義によれば、ユーザーエージェントとはWebコンテキストにおけるブラウザなど、ユーザーを代表するコンピュータプログラムを指します。
Webサイト側がリクエストの送信元を識別するための識別情報として機能します。
実際のブラウザのユーザーエージェント文字列の例は以下の通りです。
完全な文字列は複雑に見えますが、実際にはブラウザが自身の情報を構造化して記述しているに過ぎません。
視覚的に分解すると以下のようになります。

Chromeで任意のWebサイトを開き、デベロッパーツールから「ネットワーク」タブを選択してページを更新し、リクエストをクリックすることで、実際のユーザーエージェントを確認できます。
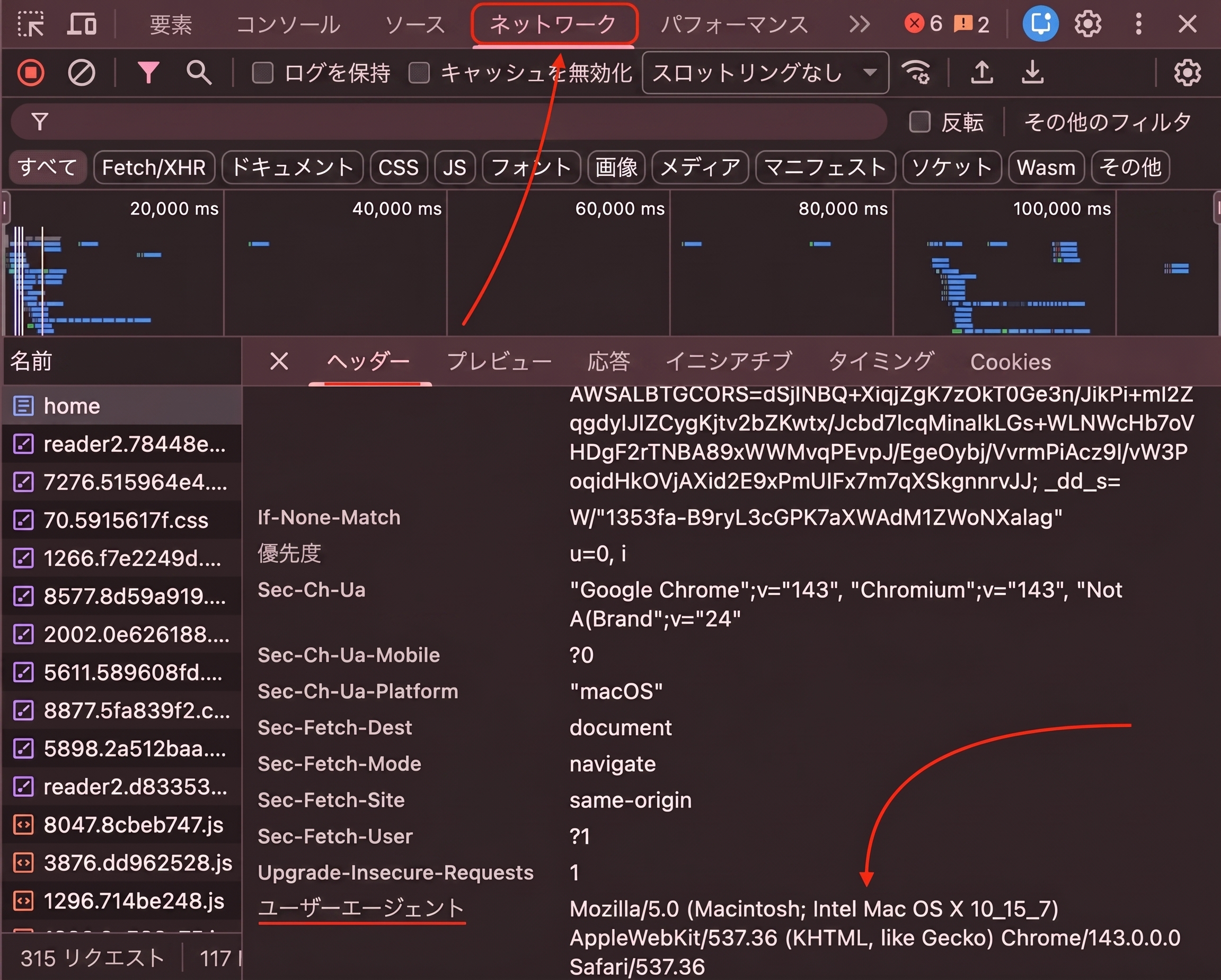
つまり、Webサイトにアクセスするたびに、ブラウザはクライアントを識別させるためにユーザーエージェントを付与しています。
送信するすべてのリクエストにこの識別文字列が含まれるため、ネットワークタブ内のどのリクエストを確認しても同じ文字列が表示されます。
本来、ユーザーエージェントは各デバイスに最適な表示を提供するために存在していましたが、現在ではユーザーの追跡や識別を主な目的として利用されています。
スクレイピング ユーザーエージェントの重要性とブロック発生のメカニズム
Webサイトに大量のリクエストを送信したり、高頻度でアクセスしたりすると、CAPTCHAの解決を求められることがあります。
これは、アクセス元がボットではなく実際の人間であることを確認するための手法の一つです。
バックグラウンドでは、送信されるブラウザのユーザーエージェントを通じて、リクエストごとにクライアントのデータが伝達されています。
大量のリクエストを伴うデータ抽出を実行すると、Webサイト側はリクエストパターンの分析を開始します。
アンチボットシステムは、以下のようなユーザーエージェントに基づく共通のシグナルを検知します。
- 同一のユーザーエージェントによる数千回に及ぶリクエスト
- python-requests、curl、Scrapyなど、自動化プログラムであることを明確に示すユーザーエージェント
- 実際のユーザーが使用していない古いブラウザバージョン
- WindowsのChromeを宣言しながら、ヘッダーがモバイル版Safariのように振る舞う不一致
- IPアドレスがローテーションされているにもかかわらず、ユーザーエージェントが固定されている状態(重大な警告シグナル)
Webサイト側の視点に立てば、価値あるデータが自動化システムによって短時間で抽出されることは望ましくありません。
そのため、以下のような挙動が確認された場合、アクセスを遮断します。
- 1万件のリクエスト
- 複数の異なるIPアドレスからのアクセス
- すべてが完全に同一のChromeバージョンを使用
このようなアクセスは即座にブロックの対象となります。
ビジネス目的のデータ抽出であっても、Webサイト側からは不審な挙動とみなされます。
ここで重要になるのが適切なユーザーエージェントのローテーションです。次項では、実例を交えてその手法を解説します。
Pythonでユーザーエージェントをローテーションする方法
ここからは、Pythonを使用してユーザーエージェントをローテーションする実践的な手法について確認します。
なぜPythonが選ばれるのでしょうか。
Webスクレイピングの分野において、Pythonは専用のライブラリやフレームワークが豊富に揃っており、開発者の間で最も広く利用されている言語の一つです。
これを踏まえ、ユーザーエージェントをローテーションする3つの一般的な手法と、それぞれが機能しなくなる限界点について解説します。
1. fake_useragentの利用(迅速だが脆弱)
多くのチュートリアルで最初に推奨される手法です。
メリット:
- 初期設定が不要
- ランダムなユーザーエージェントを即座に取得可能
- Pythonでの実装が容易
本番環境で失敗する理由:
2. 手動リストとrandom.choice()(単調だが確実)
ユーザーエージェント文字列のリストを用意し、リクエストごとにランダムに選択する手法です。
実装例は以下の通りです。
この手法が優れている理由:
- ブラウザのバージョンを制御可能
- OSの分布を管理可能
- 意図的なローテーションが可能
ただし、これは第一段階に過ぎません。より人間に近い挙動を再現するには、以下の対応も必要です。
- Acceptヘッダーの整合性確保
- Accept-Languageの整合性確保
- TLSフィンガープリントの一致
- リクエストのタイミングと挙動の再現
これらの要件を満たすのは非常に困難であり、大規模なスクレイピングにおいてこの手法単独では限界があります。
3. SeleniumやPuppeteer スクレイピング(リアルだが検知可能)
SeleniumやPuppeteerを使用したスクレイピングでも、ユーザーエージェントを設定することは可能です。
Seleniumを使用した簡単な例を示します。
このアプローチはJavaScriptを多用するWebサイトには有効ですが、最新のサイトはユーザーエージェント文字列のみに依存して判定を行っていません。
以下のような要素も比較検証されます。
- navigator.userAgent
- HTTPヘッダー
- クライアントヒント
- レンダリングの挙動
- インタラクションとタイミングのパターン
これらのシグナルが実際のブラウザの挙動と一致しない場合、スクレイパーはヘッドレスボットとしてフラグ付けされ、ブロックされます。
したがって、単にユーザーエージェントを変更するだけでは検知を回避することはできません。
手動でのUAローテーションが抱える本当の課題
前項では、Pythonでユーザーエージェントをローテーションする手法とその限界について触れました。
ここでは、より具体的な課題について掘り下げていきます。
1. 古いユーザーエージェントは即座に検知される
ブラウザは頻繁にアップデートされ、多くの場合毎月更新が行われます。
そのため、古いブラウザバージョンを使用していると即座に不審とみなされます。
さらに、多くのPythonライブラリは「python-requests/x.y.z」のようなデフォルトヘッダーを送信するため、自動化プログラムであることが明白になります。
つまり、ブラウザのリリース情報を常に追跡し、ユーザーエージェントのリストを更新して古いエントリを削除し続ける必要があります。
時間の経過とともに、この作業は煩雑になり、エラーを引き起こす原因となります。
2. 他のフィンガープリントとの一貫性
最新のWebサイトはユーザーエージェント文字列のみに依存していません。
アンチボットシステムは完全なブラウザフィンガープリントを実行し、リクエストの全要素がユーザーエージェントの宣言と一致しているかを検証します。
具体的には、最新のブラウザフィンガープリント技術は、HTTPヘッダー、JavaScript API、低レベルのシグナルを組み合わせ、Cookieに依存しない安定したデバイスIDを構築します。
簡単に言えば、ユーザーエージェントがWindowsのChromeを宣言しているのに、ヘッダーがモバイル版Safariのように振る舞う場合、ほぼ瞬時にブロックされます。
検証はさらに深部まで及びます。
random.choice()を使用した手動ローテーションでは、Webサイトは以下の要素も評価します。
- AcceptおよびAccept-Languageヘッダー
- TLSフィンガープリント
- リクエストのタイミングと挙動
SeleniumやPuppeteerを使用している場合、チェックはさらに厳格になります。サイト側はnavigator.userAgent、HTTPヘッダー、クライアントヒント、レンダリングの挙動、インタラクションのパターンを精査します。
3. クローラー メンテナンスが膨大な負担になる
大規模なスクレイピングを開始すると、ユーザーエージェントの管理は継続的なインフラ運用の課題となります。
以下の要素を維持管理する必要があります。
- ユーザーエージェントのリスト
- ヘッダーの組み合わせ
- プロキシとロケーションの整合性
- フェイルオーバーと再試行ロジック
この段階になると、スクレイピングは単なるコード記述の範疇を超えます。
脆弱なシステムの管理が中心となり、多くの開発者がクローラー メンテナンスの負担から挫折するか、より優れた代替手段を模索し始めます。
自動ユーザーエージェントローテーションが優れている理由
前項では、手動でのユーザーエージェント管理がいかに煩雑で拡張性に欠けるかを確認しました。
では、どのような解決策があるのでしょうか。
ここで役立つのが、Octoparseのようなノーコードツールです。
これらのツールはユーザーエージェントを自動的にローテーションし、最新状態に保ちながらヘッダーを正確に一致させ、実際のブラウザの挙動をシミュレートします。
それでは、具体的なOctoparse 使い方について見ていきましょう。
OctoparseのWebサイトにアクセスし、「無料トライアルを開始」ボタンをクリックするだけで始められます。
特定のWebサイトのスクレイピングを開始する際は、以下の手順を実行します。
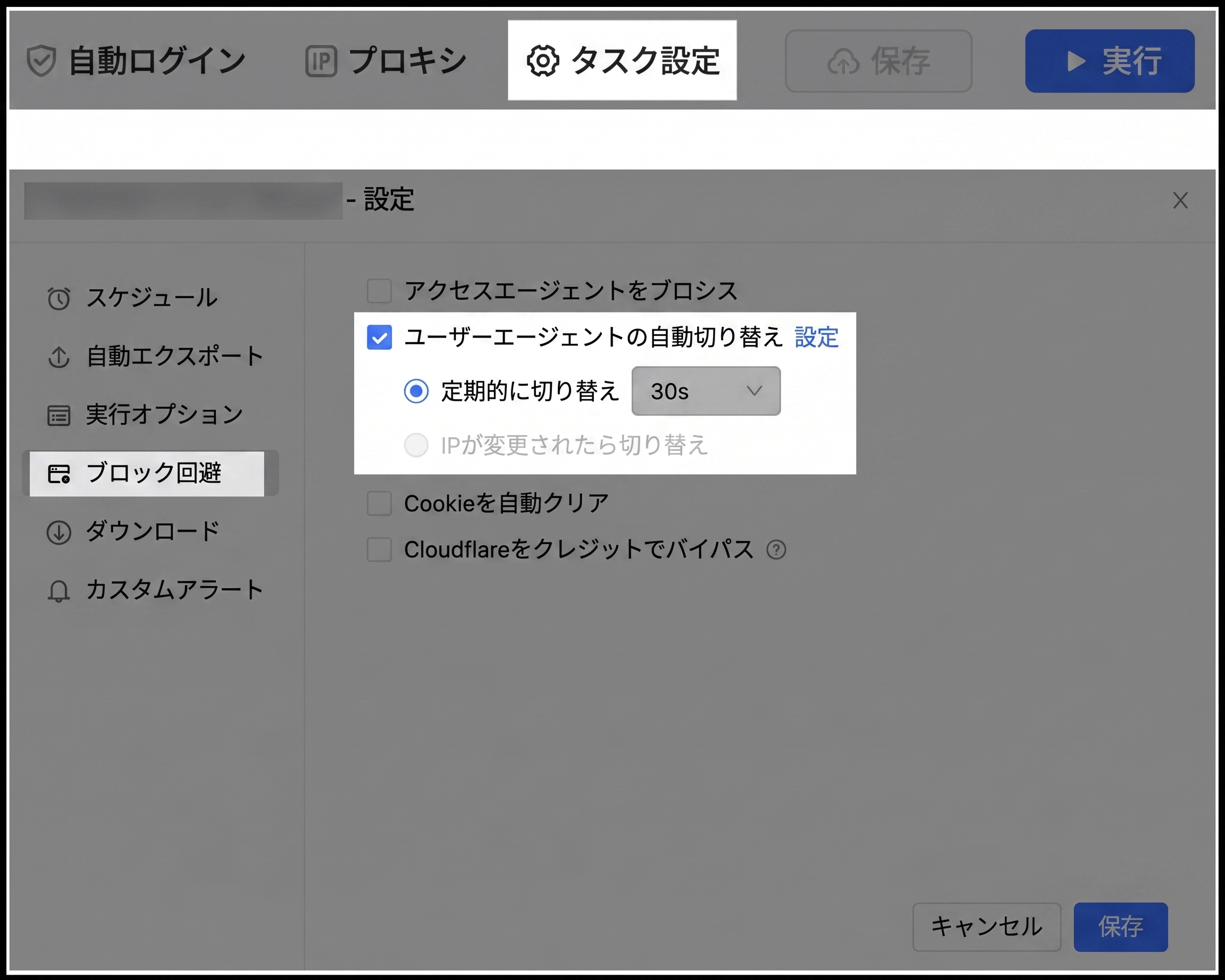
- タスク設定から「アンチブロック」に移動します。
- 「ブラウザエージェントを自動切り替え」のチェックボックスをオンにします。
- 「設定」をクリックし、利用可能なユーザーエージェントのリストから選択します。
- 重要:対象となるデバイスタイプに一致するエージェントを選択してください。
- PC/デスクトップ向けスクレイピング:デスクトップ用のユーザーエージェント(WindowsのChromeやFirefoxなど)のみを選択します。
- モバイル向けスクレイピング:モバイル用のユーザーエージェント(モバイル版FirefoxやiPhoneのSafariなど)のみを選択します。
- ローテーションの頻度(例:X分ごとに切り替え)を設定するか、最大限のバリエーションを持たせるために「UAを同時に切り替え」を選択します。
- 設定を確定します。
このアプローチが適しているケース:
- インフラ構築よりもデータ抽出自体を重視している
- スクレイパーの障害対応に手間をかけたくない
- ビジネスに不可欠な重要なデータをスクレイピングしている
- 深夜にフィンガープリントの不一致をデバッグするような事態を避けたい
Pythonとノーコード:どちらが適しているか?
ここまでお読みいただければ、ご自身の目的にどちらが適しているか、明確なイメージが掴めたのではないでしょうか。
より具体的に理解していただくため、両者の比較をまとめました。
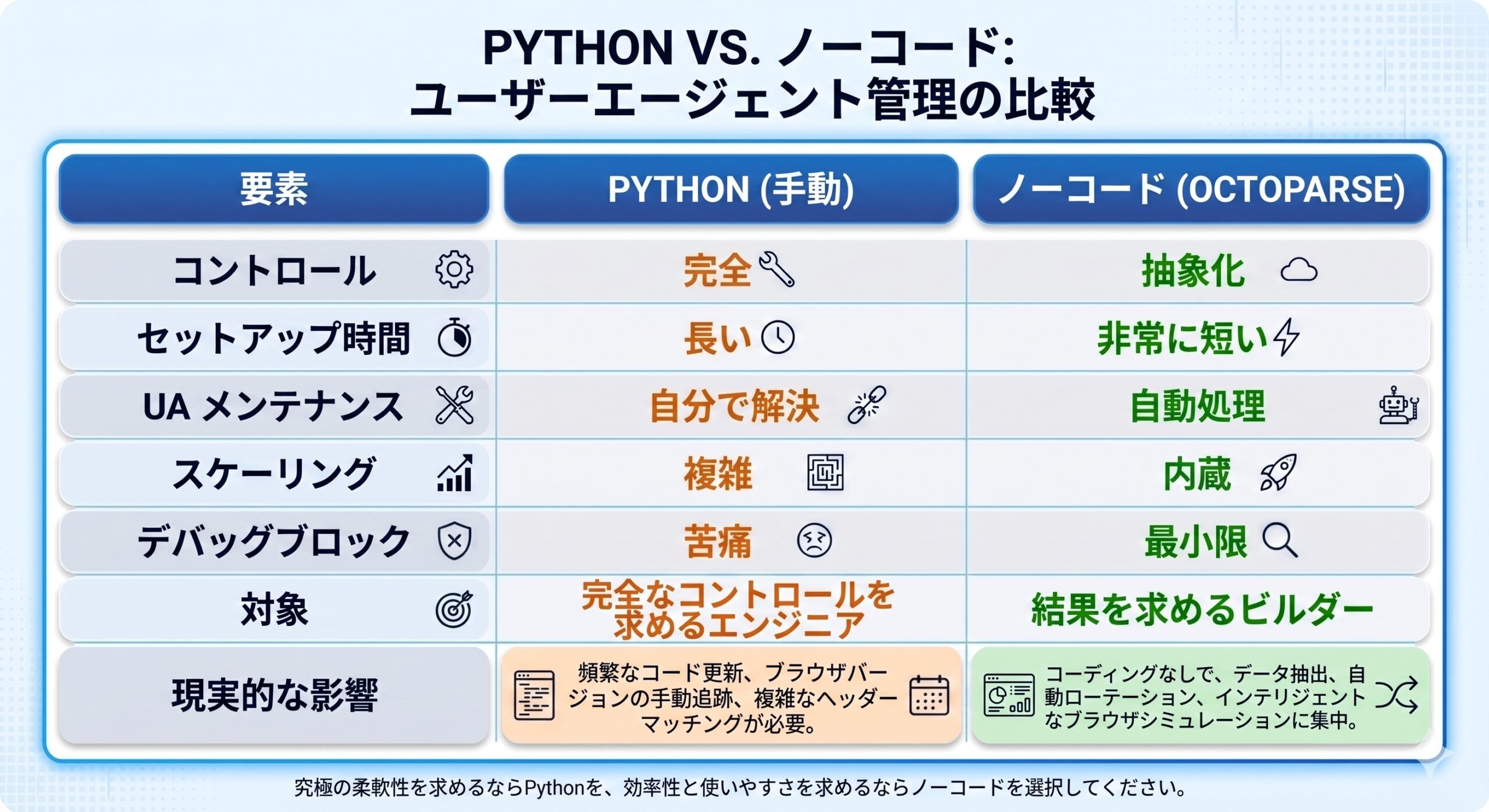
詳細に言えば、完全な制御を求め、以下のような運用コストを許容できる場合はPythonが適しています。
- 最新のユーザーエージェントリストの維持
- ユーザーエージェント、ヘッダー、TLS、プロキシのロケーションが確実に一致するような設定
- 仕様のサイレント変更によって発生するブロックのデバッグ
- ブラウザの継続的な更新に合わせ、常にリアルな挙動を維持する作業
一方、複雑なインフラ管理を避け、データ抽出そのものを最優先とする場合は、Octoparseのようなノーコードツールを選択すべきです。
ノーコードツールは以下の要件に合致する際に有効です。
- ブラウザのアップデートを常に追跡したくない
- ユーザーエージェントとヘッダーの不一致によるデバッグ作業を避けたい
- 大規模なデータ抽出を安定して継続させたい
これらを踏まえ、一つのシンプルな問いを投げかけてみてください。「スクレイピングのインフラを構築・維持したいのか、それともデータを抽出して次の業務に進みたいのか?」
その答えが、最適な選択肢となります。
スクレイピング ユーザーエージェント管理のベストプラクティス
ここまで、ユーザーエージェントの概要、各アプローチを通じた利用方法、そしてそれぞれの限界について解説しました。
最後に、ユーザーエージェントを適切に管理するためのベストプラクティスについて説明します。
以下の実践的なガイドラインに従うことを推奨します。
1. ユーザーエージェントの数が多いほど安全というわけではない
数百ものユーザーエージェントを使用しても、実質的なメリットはなく不必要な複雑さを招くだけです。
代わりに、10〜20種類の最新かつ実在するブラウザのユーザーエージェントを用意し、ゆっくりとローテーションさせてください。
この手法が有効な理由:
- 実際のユーザーはリクエストごとにブラウザを変更しない
- 一貫性があることで人間らしい挙動とみなされる
- ランダムすぎる挙動は自動化プログラムと判定されやすい
リクエストごとにユーザーエージェントを切り替えている場合、即座にブロックされなくても、すでにフラグが立てられている可能性が高いです。
2. ユーザーエージェントとヘッダーをセットで固定する
最新のWebサイトは他のリクエストヘッダーも検証するため、ユーザーエージェントのみをローテーションさせることは避けてください。
各ユーザーエージェントは、常に以下の要素とセットで送信する必要があります。
- 整合性のあるAcceptヘッダー
- 整合性のあるAccept-Language
- WindowsやiPhoneなど、一致するプラットフォーム情報
- 一致するプロキシのロケーション
ユーザーエージェントが「米国のWindows上のChrome」を宣言しているにもかかわらず、ヘッダーが「インドからのモバイル版Safari」のように振る舞う場合、プロキシをどれだけローテーションさせても意味がありません。
3. 障害発生時ではなく、定期的なスケジュールで更新する
ブラウザは頻繁に更新されており、アンチボットシステムもその事実を把握しています。
Chromeのユーザーエージェントが数バージョン古い場合、リクエスト数が少なくても不審とみなされます。
基本的な運用ルール:
- 月に1回、ブラウザのリリース情報を確認する
- 古いユーザーエージェントは積極的に削除する
- 多数の古いユーザーエージェントを保持するより、少数の最新ユーザーエージェントを使用する方が効果的
4. IPローテーションによってユーザーエージェントのパターンを露呈させない
最も早くブロックされる典型的なパターンは以下の通りです。
- リクエストごとにIPアドレスが変化する
- ユーザーエージェントが一切変化しない
この挙動は、自動化プログラムであることを明確に示しています。
IPアドレスをローテーションする場合は、以下の点に注意してください。
- ユーザーエージェントも適度な頻度でローテーションする
- 1つのIPアドレスからの複数リクエストにおいて、同一のユーザーエージェントを保持する
- セッションが連続的でリアルに見えるように制御する
5. 可能な限りノーコードツールを活用する
ユーザーエージェントの正確な管理には膨大な時間がかかり、システムとしても脆弱になりがちです。
Octoparseのようなノーコードツールは、ユーザーエージェントの自動ローテーション、最新状態の維持、ヘッダーの正確なマッチング、リアルなブラウザ挙動のシミュレーションを実行します。
これにより、スクレイピングインフラの管理に追われることなく、データ抽出と成果の獲得に専念できます。
よくある質問(FAQ)
1. 住宅用プロキシを使用していれば、ユーザーエージェントは気にしなくてもよいですか?
いいえ、依然として重要です。プロキシはIPレピュテーションという問題の一部を解決するに過ぎません。
多くのアンチボットシステムは、IPアドレスだけでなく、ユーザーエージェント、ヘッダー、TLSフィンガープリント、リクエストのタイミングなども監視しています。
そのため、IPアドレスをローテーションしても、数百のセッションで同じユーザーエージェントを使用し続ければ、そのパターンだけでブロックの対象となります。
2. リクエストごとにランダムなユーザーエージェントをローテーションさせるのは避けるべきですか?
はい、これは最もよくある間違いの一つです。
実際のユーザーは、ページを読み込むたびにブラウザの識別情報を変更することはありません。
スクレイパーがリクエストごとにWindowsのChrome 120からmacOSのChrome 121に切り替わると、自動化プログラムであると容易に見抜かれます。
3. fake_useragentのようなPythonライブラリは、本番環境のスクレイピングでも安全ですか?
安全とは言えません。
簡単な実験には適していますが、大規模な本格的スクレイピングには脆弱です。ユーザーエージェントが古かったり、ソースがダウンしたりするリスクがあり、何より生成されたユーザーエージェントが他のリクエストヘッダーと一致しないことが多いためです。
4. 「本物」のChromeユーザーエージェントを使用してもスクレイパーがブロックされるのはなぜですか?
Chromeのユーザーエージェントだけでは、リクエストが実際のブラウザのように見えるわけではないからです。
最新のアンチボットシステムの多くは、その宣言をヘッダー、TLSフィンガープリント、ブラウザAPI、行動シグナルなどの他の要素と相互チェックします。
したがって、「Windows上のChrome」を宣言しながらPythonスクリプトのように振る舞うと、その矛盾が即座に検知されます。
5. Pythonでのスクレイピング ユーザーエージェント管理は、どのタイミングで限界を迎えますか?
スクレイパーがビジネスに不可欠な存在となり、Python使用時の煩雑なプロセスに対処することが困難になった時点です。
その段階でノーコードツールが有効になります。これはPythonが劣っているからではなく、背後に潜む複雑な運用コストが膨大になるためです。

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール