「データマイニングとは何か?」と聞かれて、すっきり説明できる方はどのくらいいるでしょうか。
AI、機械学習、ビッグデータ——似たような言葉が飛び交う中で、データマイニングの立ち位置が曖昧なまま使っている人は少なくありません。
本記事では、データマイニングの定義から代表的な手法、業界標準のCRISP-DMプロセス、業界別の活用事例、さらに2026年のAI最新動向まで、この1記事でデータマイニングの全体像を理解できるように体系的に解説します。
データマイニングとは?定義とDIKWモデル
データマイニングとは、膨大なデータの中から統計学やパターン認識を駆使して、隠れた法則や相関関係を発見する手法のことです。「マイニング(mining)」は「採掘」を意味し、鉱山から貴重な鉱石を掘り出すように、データの山から価値ある知見を掘り当てるイメージです。
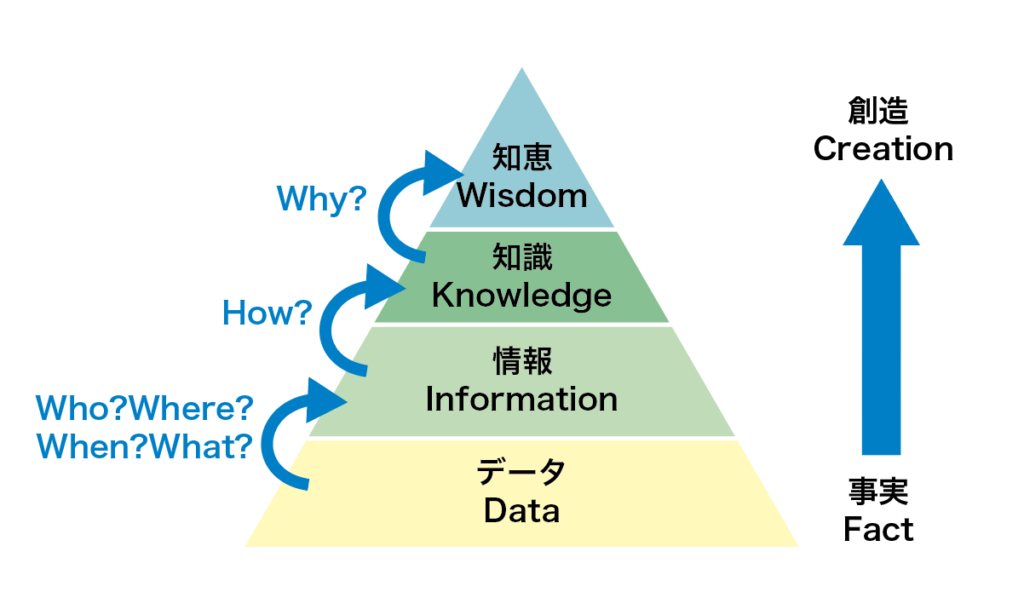
DIKWモデル:データが「知恵」になるまでの4段階
データマイニングの位置づけを理解するには、DIKWモデル(Bellinger et al., 2004に基づく知識階層モデル)が役立ちます。
・DIKWモデル(ピラミッド)
- データ(Data):分析に利用するデータ
- 情報(Information):データを整理した状態
- 知識(Knowledge):情報を分析した状態
- 知恵(Wisdom):知識をもとに意思決定する状態
データは、この①から④の課程を通して価値が高まると言われています。
| 階層 | 意味 | 具体例 |
|---|---|---|
| Data(データ) | それ自体では意味を持たない数値・記号 | 売上高:1,000万、日付:2024年 |
| Information(情報) | データを整理して解釈可能にしたもの | 2024年の年間売上高は1,000万円 |
| Knowledge(知識) | 情報から導かれる傾向や法則 | 過去3年間、売上は毎年10%増加している |
| Wisdom(知恵) | 知識を活かした意思決定力 | 成長率を考慮し、来年は新規事業に投資する |
データマイニングは、データ→情報→知識へと昇華させるプロセスを加速する技術であり、人間はその知識をもとに知恵(=意思決定)を生み出します。
ビッグデータの定義と収集方法についてさらに詳しく知りたい方は、こちらの記事もご参照ください。
データマイニングでできること5選
データマイニングの具体的な効果を把握するために、代表的な活用パターンを5つ紹介します。
①データを予測できる — 過去の販売データを分析し、「何月に・何時に・どの商品が・どれだけ売れるか」を数値で予測。感覚的な判断をデータに置き換えることが可能です。
②異常値を検出できる — 従来のパターンから外れた数値をいち早く検知。製造機器の故障予兆や金融取引の不正利用の発見に活用されています。
③データを分類できる — 顧客や商品を属性ごとにグループ化し、セグメント別のマーケティング施策を展開する基盤を構築します。
④データの関連性を見つけられる — 「Aを買った人はBも買う傾向がある」「この条件の顧客は解約しやすい」など、人間の直感では気づかない相関を数値化します。
⑤テキストマイニングに活用できる — 商品レビュー、SNS投稿、チャットボットの対話ログなど、テキストデータからキーワードやトレンド、感情の傾向を抽出できます。
スクレイピングでデータ分析を向上させる方法では、データ収集と分析の具体的な連携事例を紹介しています。
データマイニングの代表的な手法6選
データマイニングにはさまざまな分析手法がありますが、実務で特に頻繁に使われる6つを紹介します。
1. アソシエーション分析
「Aを買った人はBも買う」という購買パターンを発見する手法。ECサイトのレコメンドエンジンや、小売店の棚割り最適化に活用されています。有名な「おむつとビール」の事例は、このデータマイニング手法から生まれました。
2. 決定木分析
データをツリー構造に分岐させ、特定の結果に至るパターンを可視化する手法。「どの属性の顧客が解約しやすいか」「どの条件が購入に結びつくか」を直感的に理解できるため、経営層への報告にも適しています。
3. クラスタリング(クラスター分析)
類似する特徴を持つデータを自動的にグループ化する手法。顧客セグメンテーション(高級志向/コスパ重視/機能重視など)に広く活用され、グループごとに最適化されたマーケティング施策の基盤となります。
4. 回帰分析
原因と結果の関係性を数値化する手法。「広告費を10%増やすと売上はどれだけ伸びるか」といった定量的な予測を行い、投資対効果の判断に直結します。
5. ロジスティック回帰分析
複数の要因をもとに、特定の事象が発生する確率を予測する手法。「このキャンペーンの反応率は何%か」「この顧客が解約する確率は何%か」といった確率予測に使われます。
6. ABC分析
過去の売上データをもとに商品の重要度をA(売れ筋)・B(中位)・C(低位)に分類し、在庫管理や発注優先度の判断に活用する手法。小売業で最も実務に密着したデータマイニング手法の一つです。
| 手法 | 主な用途 | 身近な活用例 |
|---|---|---|
| アソシエーション分析 | 購買パターンの発見 | ECのレコメンド機能 |
| 決定木分析 | 分類・予測の可視化 | 顧客解約の予兆分析 |
| クラスタリング | グループ化 | 顧客セグメンテーション |
| 回帰分析 | 因果関係の定量化 | 広告費 vs 売上の予測 |
| ロジスティック回帰 | 確率予測 | キャンペーン反応率 |
| ABC分析 | 優先度の分類 | 在庫管理・発注最適化 |
データマイニングの手法については、遺伝的アルゴリズムやニューラルネットワークなど、より高度な手法も別記事で解説しています。
CRISP-DM:データマイニングの6ステッププロセス
データマイニングを実務で成功させるためには、体系的なプロセスに沿って進めることが重要です。業界標準として広く採用されているのがCRISP-DM(CRoss-Industry Standard Process for Data Mining)です。
ステップ1:ビジネスの理解
まず、データマイニングの目的をビジネス視点で明確にします。「クラスタリングをやりたい」ではなく「顧客の離反を防ぎたい」という目的設定が出発点です。
ステップ2:データの理解
分析に使うデータを収集し、データの意味・品質・構造を把握します。ここでデータの傾向を掴むことで、仮説の形成が可能になります。
ステップ3:データの準備
データマイニングの工程全体の60〜80%を占めるとも言われる最重要ステップです。データクレンジング(欠損値の補完、重複の除去、異常値の処理)を行い、分析に適した形に整形します。
ステップ4:モデリング(分析)
適切な分析手法を選択し、データマイニングを実行。構築されたモデルの性能を評価し、精度向上のためにパラメータを調整します。
ステップ5:評価
構築したモデルがビジネス目標を達成しているかを検証します。技術的に優れたモデルでも、実務で役立たなければ意味がありません。
ステップ6:展開・活用
データマイニングの結果をビジネスに反映します。たとえば、発見した購買パターンに基づくキャンペーン施策の実施や、予測モデルを組み込んだシステムの構築などが該当します。
ビッグデータ分析ツール28選では、各ステップで活用できるツールをまとめています。
データマイニングと機械学習の違い
データマイニングと機械学習はしばしば混同されますが、最終目的が異なります。
データマイニングは、データの中から未知のパターンや相関関係を**「発見」**することが目的です。発見された知見は人間が解釈し、意思決定に活用します。
機械学習は、発見されたパターンをアルゴリズムに学習させ、新たなデータに対する**「予測・自動判断」**を行うことが目的です。
つまり、データマイニングは「知見の発見」、機械学習は「発見した知見に基づく自動化」という関係にあります。両者は対立概念ではなく、実務ではデータマイニングで発見したパターンを機械学習モデルに組み込むという補完的な関係が一般的です。
ビッグデータ・データマイニング・機械学習の違いについては、図解付きの解説記事も参考になります。
業界別データマイニング活用事例
小売・EC業界
POSデータ・顧客データ・天候データなどを組み合わせたデータマイニングで、新商品の開発やキャンペーン施策を最適化。価格調査の自動化と組み合わせれば、競合分析にも活用可能です。
金融業界
クレジットカードの取引データからデータマイニングで不正利用パターンを検出し、リアルタイムで警告を発するシステムを構築。消費者ローンの与信審査にも活用されています。
医療業界
電子カルテの膨大なデータからデータマイニングで疾患と症状の相関を発見し、早期診断の精度向上に貢献。薬剤の副作用パターンの検出にも活用されています。
製造業界
製造機器のセンサーデータをデータマイニングで分析し、故障予兆を検知して事前修理を実施。ダウンタイムの削減とメンテナンスコストの最適化を実現しています。
教育業界
生徒の成績・学習行動データをデータマイニングで分析し、個別最適な指導法を発見。学習意欲の低下パターンを早期検知し、フィードバックの質を向上させた大学の事例もあります。
保険業界
地域・年齢・車種・走行距離などのデータをデータマイニングで分析し、最適な保険料算出と新商品開発に活用。事故リスクの高い属性を数値化することで、引受判断の精度が向上しています。
ビッグデータ活用事例15選では、さらに多くの業界事例を紹介しています。
2026年注目:生成AI時代のデータマイニング
生成AIが「データ準備」の負担を激減させた
CRISP-DMのステップ3「データの準備」は、工程全体の60〜80%を占めるとも言われる最大のボトルネックでした。2026年現在、ChatGPTやGeminiなどの生成AIにCSVファイルを読み込ませ「このデータをクレンジングして、欠損値を補完し、分析に適した形にして」と指示するだけで、データ準備が大幅に効率化されています。
AIエージェントが「収集→マイニング→活用」を自律実行
さらに、AIエージェントがOctoparseのMCP AI機能を通じてWebデータを自動収集し、そのデータに対してデータマイニングを実行し、発見された知見をレポートとして出力するまでを自律的に処理できる環境が整いつつあります。
「競合3社のECサイトの価格推移を毎日収集して、値下げパターンを見つけて」という一文の指示だけで、データの収集→整形→分析→レポーティングまでが自動化される——これが2026年のデータマイニングの最前線です。
データマイニングを始めるためのデータ収集方法
データマイニングの精度は、元データの量と質に大きく依存します。優れた手法を選んでも、入力データが貧弱であれば有益な発見は得られません。
Web上の公開データを自動収集する
データマイニングの素材として最も手軽に入手できるのが、Web上に公開されているデータです。ECサイトの価格・レビュー、求人情報、口コミ、政府のオープンデータなど、データマイニングの対象となるデータソースは無数にあります。
オープンデータソース70選では、カテゴリ別に無料で使えるデータソースをまとめています。
Octoparseでノーコードのデータ収集
Octoparseは、プログラミング不要でWebデータを自動収集できるクラウド型ツールです。URLを入力するだけでAIがページ構造を自動解析し、データマイニングに必要なデータを効率的に取得できます。
収集したデータはCSV・Excel・JSONなどでエクスポート可能なので、そのままBIツールやPythonの分析ライブラリに読み込んでデータマイニングを実行できます。
Amazon、楽天、Googleマップなど主要サイト向けのスクレイピングテンプレートも用意されており、パラメータを入力するだけでデータ収集を開始可能です。
Webスクレイピングとデータマイニングの違いについては、FAQ形式でわかりやすく解説しています。
よくある質問(FAQ)
Q1. データマイニングとAI(人工知能)の違いは何ですか?
データマイニングはデータから有益なパターンを発見する「手法」であり、AIはデータマイニングを含むさまざまな知的処理を実行する「技術体系」です。AIの機械学習アルゴリズムがデータマイニングに活用されることも多く、両者は密接に関連しています。
Q2. データマイニングにはどんな知識が必要ですか?
統計学の基礎知識、データベース操作(SQL)、プログラミング(PythonやR)のスキルがあると有利です。ただし2026年現在は、生成AIやノーコードツールの普及により、専門知識がなくてもデータマイニングに取り組める環境が整いつつあります。
Q3. データマイニングを始めるのに費用はどれくらいかかりますか?
Octoparseの無料プラン(10タスクまで)と、無料のBI/分析ツール(Google Colaboratory、Orange等)を組み合わせれば、初期費用ゼロで始められます。エンタープライズ向けの本格的な基盤構築であれば、数百万円以上の投資が必要です。
Q4. データマイニングで失敗しやすいポイントは?
最も多い失敗パターンは、「データを集めること自体が目的化する」ケースです。CRISP-DMのステップ1「ビジネスの理解」を飛ばして手法選定に入ると、技術的には正確でもビジネスに役立たない分析結果になりがちです。
Q5. 小規模なデータでもデータマイニングは可能ですか?
技術的には可能ですが、データ量が少ないと発見されるパターンの信頼性が低くなります。一般的には、データが多ければ多いほど有益な知見を得られる可能性が高まります。Octoparseなどのツールでデータ量を増やすことで、データマイニングの精度が向上します。
まとめ:データマイニングは「探す力」ではなく「問う力」で決まる
正直に言うと、データマイニングを学び始めた頃、筆者は「すごいアルゴリズムを使えば、データが勝手に答えを教えてくれる」と思っていました。
現実は違いました。
最初にOctoparseで集めた商品レビュー3,000件にクラスタリングをかけた結果、出てきたのは「ポジティブなレビューとネガティブなレビューがある」という、わざわざ分析しなくても分かるような知見でした。
失敗の原因は明確でした。「何を知りたいか」を決めずにデータを分析していたのです。
CRISP-DMのステップ1「ビジネスの理解」に立ち返って、「なぜ星1レビューが集中する商品と、そうでない商品があるのか?」という問いを立て直しました。すると、同じクラスタリングの結果から「配送遅延が星1レビューの最大要因であり、特に金曜注文→月曜到着のパターンで集中している」という、具体的なアクションにつながる知見が見つかりました。
つまり、データマイニングの成否を決めるのは、分析手法の洗練度でも、データの量でもなく、「何を知りたいか」という問いの質です。
これからデータマイニングに取り組む方は、まず「自分の業務の中で、データがあれば解決できる問い」を一つだけ見つけてください。その問いが明確であれば、本記事で紹介した手法の中から最適なものを選び、Octoparseで必要なデータを集めて分析するだけです。
データマイニングは、問いを持つ人の味方です。
データマイニングのためのデータ収集を始めるなら → Octoparse 無料ダウンロード



