Indeed(インディード)の求人情報を大量に収集したいと思ったとき、手作業では限界があります。求人タイトル・会社名・給与・勤務地をまとめてデータ化したい——そんなニーズに応えるのが「Indeedスクレイピング」です。
厚生労働省の「一般職業紹介状況」によると、2025年6月時点の有効求人倍率は1.22倍となっており、求職者1人あたりの求人が1件以上ある“売り手市場”の状態が続いています。
このように労働市場では人材需要が依然として高く、採用活動や求人情報の迅速な収集・分析の重要性は引き続き高まっています。
本記事では、ノーコードでIndeed(インディード)をスクレイピングできるツール「Octoparse」を中心に、3つの方法のメリット・デメリット、法的注意点、そして取得データの活用事例まで体系的に解説します。プログラミング経験のない方でも最短5分でデータ収集を開始できます。
求人情報を自動収集するメリット
そもそも求人情報を自動収集するメリットはどのようなものが考えられるでしょうか?
情報を自動で取得できるということは、常に最新で鮮度の高い情報が手に入るということです。企業側にとって、鮮度の高い求人情報を入手することは以下のようなメリットがあります。
- 求人の傾向や市場の変化を掴み、自社事業の分析・調整に役立つ
- ベンチマークしている競合他社の動向を追跡・分析できる
- 営業リストを自動で整理・作成できる
特に今まで手作業でリスト作成をしていた場合は、大幅な業務時間の短縮が期待できるため、浮いた時間でより生産的な活動に時間を費やすことが可能です。
求人情報を自動で収集する方法3選
ナビサイトやIndeedなどに掲載されている求人情報を自動で収集するには、どのような方法があるのでしょうか。ここでは、求人情報を自動で取得するための3つの方法をメリットとデメリットとあわせて解説します。
1.プログラミング言語を使ってWebクローラーを構築する
プログラミング言語を使ってゼロからWebクローラーを構築する方法です。特に機械学習に強い「Python」などがおすすめです。ただし、プログラミング未経験者が自力でWebクローラーを構築できるようになるには、少なくとも数ヶ月のプログラミング学習が必要です。
近年ではYouTubeやブログなどで、プログラミングの方法をわかりやすく解説しているコンテンツが豊富なので、独学で覚えたい方にはぜひおすすめです。
参考:【Pythonクローラー入門】クローリング スクレイピング方法 総まとめ|SAMURAI ENGINEERブログ
メリット
- クローリングプロセスを完全にコントロールことができる
- コミュニケーションの手間が少なく、迅速な対応が可能
デメリット
- プログラミング学習の時間が必要
- クローラーの配置・運用・保守といった技術力が必要
- 初期開発コストが高い
2.データ代行収集サービス(DaaS)を依頼する
データ代行収集サービスは、データ取得の作業を外部企業やフリーランスに依頼する方法です。「餅は餅屋」という通り、何ごともその道の専門家に任せるのが最も手軽な方法です。
ただし外注する分、それなりのコストがかかります。データ収集を依頼するサイトの数、サイトのHTML構造、取得するデータ量などによって料金が変動します。
メリット
- IT専門知識を学習する時間を省く
- 事務負担及び収集時に発生するリスクを軽減
デメリット
- 依頼先に支払う代行費用が比較的高くなる
- 依頼先とのコミュニケーションに時間がかかる
- 依頼先に発注から納品までに時間を要する
3.Webスクレイピングツールを使う
Webスクレイピングツールは、プログラミングの知識がなくても、マウス操作を中心にWebページ上のデータを指定して自動取得できるツールです。近年ではノーコードで利用できるツールも増えており、業務用途でも導入が進んでいます。
中でもOctoparseのようなツールは、日本語対応やテンプレート機能が用意されており、事前設定されたワークフローを利用することで、比較的短時間でデータ収集を開始できます。また、クラウド収集機能により、ローカル環境の影響を受けにくい設計となっています。
一方で、取得対象のWebサイトの仕様変更やサーバー状況によっては、データ取得の安定性が変動する場合があります。そのため、運用時には定期的な確認や設定の見直しが必要です。
メリット
- ノーコードでデータ取得が可能(プログラミング不要)
- テンプレートを活用することで設定負荷を軽減できる
- スケジュール実行により定期的なデータ収集が可能
- クラウド実行により環境依存を抑えられる
留意点
- 初期設定や操作方法の理解には一定の学習コストが発生する
- 対象サイトの構造変更や制限により取得結果が影響を受ける場合がある
より多くのツールを比較しながら選びたい場合は、スクレイピングツールの選び方や特徴についてまとめた「【2026年版】スクレイピングツール12選!無料&AI対応を用途別に徹底比較」も参考になります。

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール
Octoparseでインディード求人情報を取得する方法
Octoparseはノーコード操作で誰でも使えるWebスクレイピングツールです。世界180カ国以上・200万人以上のユーザーに利用されており、日本語インターフェースと日本語サポートも完備しています。
Indeed(インディード)をはじめとするWebページのHTML構造を自動認識し、必要なデータをクリック操作で選択・抽出できます。無料プランから始められるため、初めてのデータ収集にも最適です。
実際に「東京都 ウェブデザイナー」の条件で以下のデータを取得した手順を紹介します。
https://www.octoparse.jp/template/indeed-job-listing-scraper-jp-by-keywords
https://www.octoparse.jp/template/jp-indeed-job-url-scraper-cloud
ステップ1:Octoparseをダウンロードして、サービスを立ち上げます。
ステップ2:トップページの「おすすめ」の中からIndeedのテンプレートをクリックします。
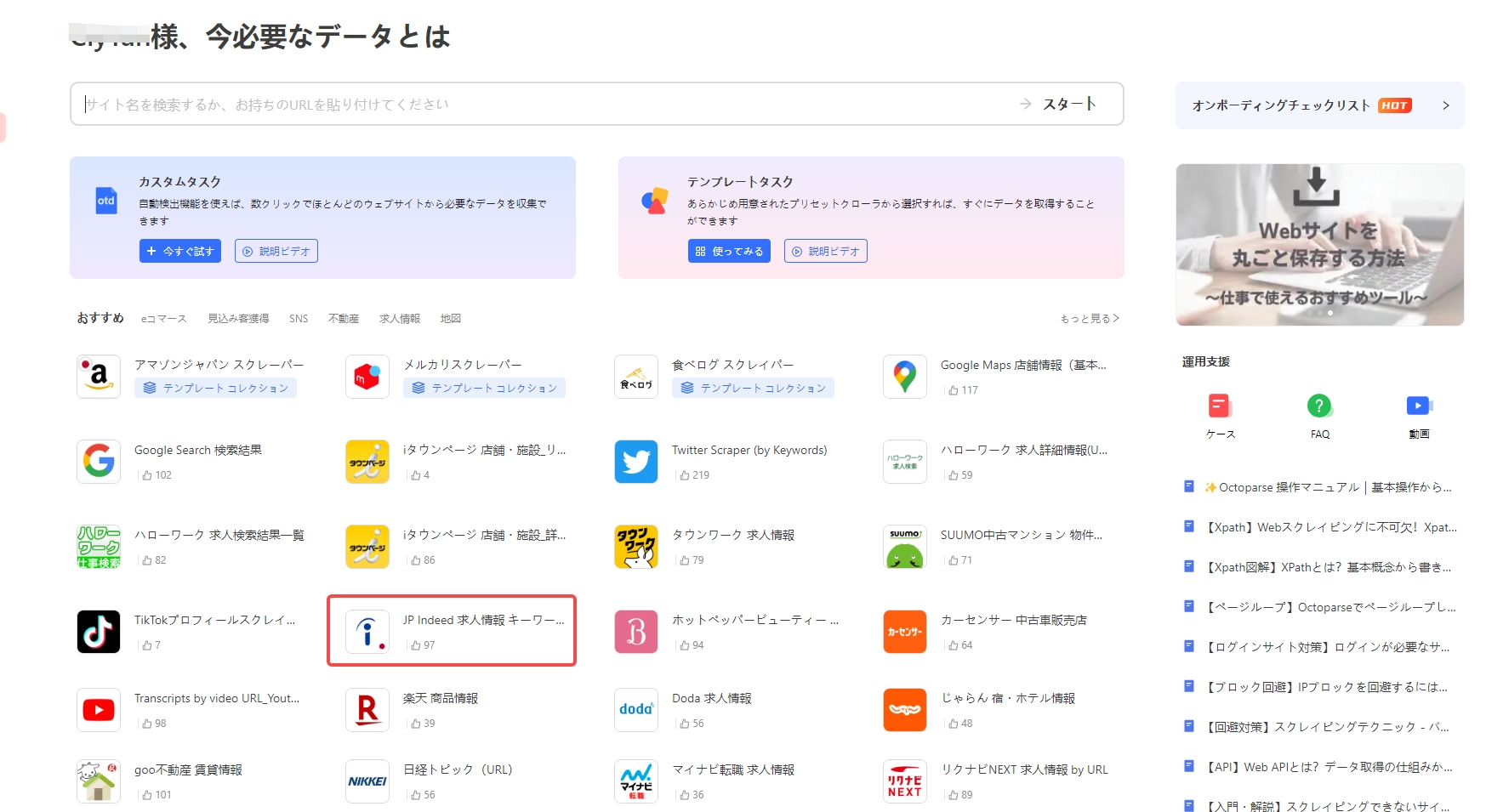
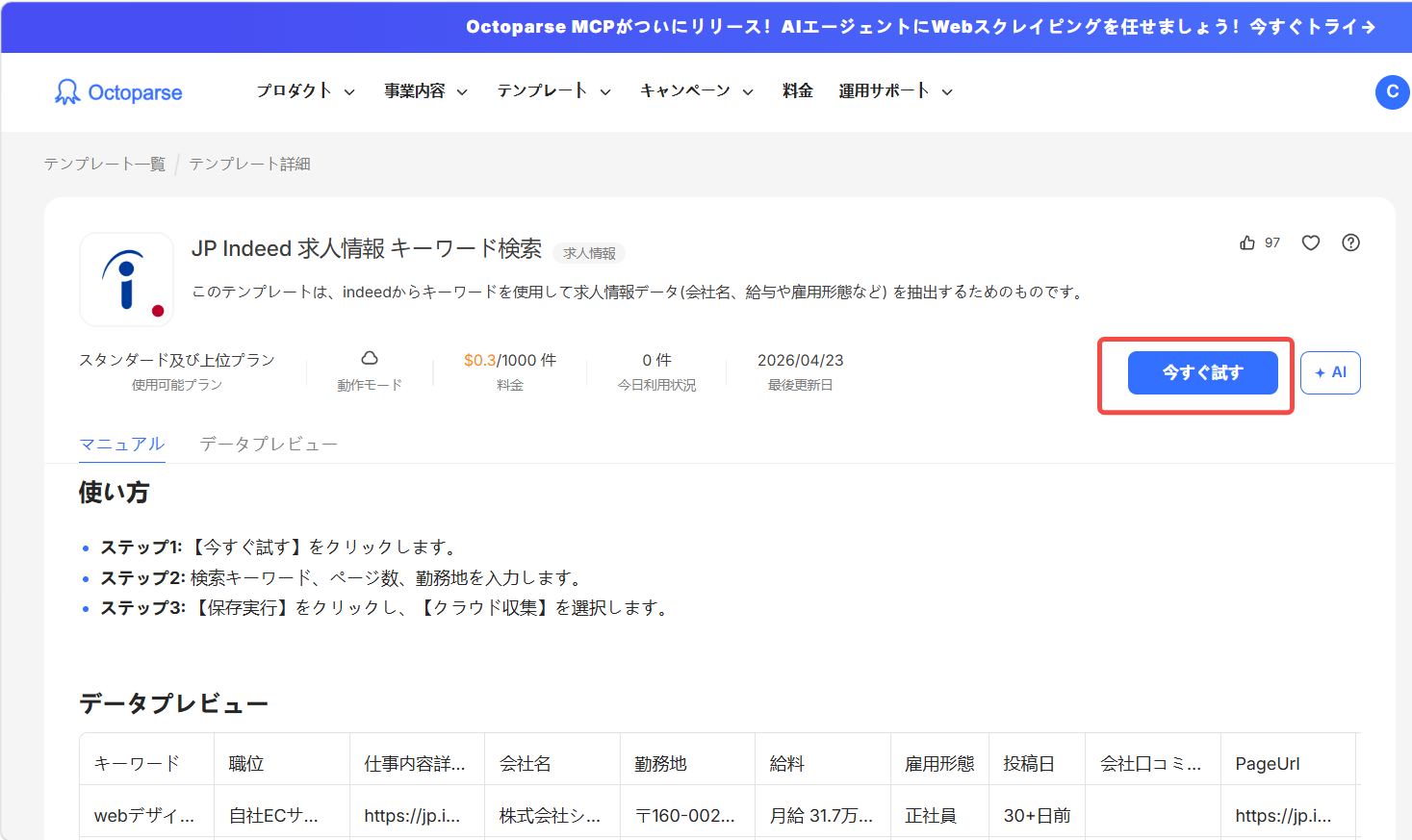
Web版からもIndeedのテンプレートを利用できます。[今すぐ試す]をクリックしてください。
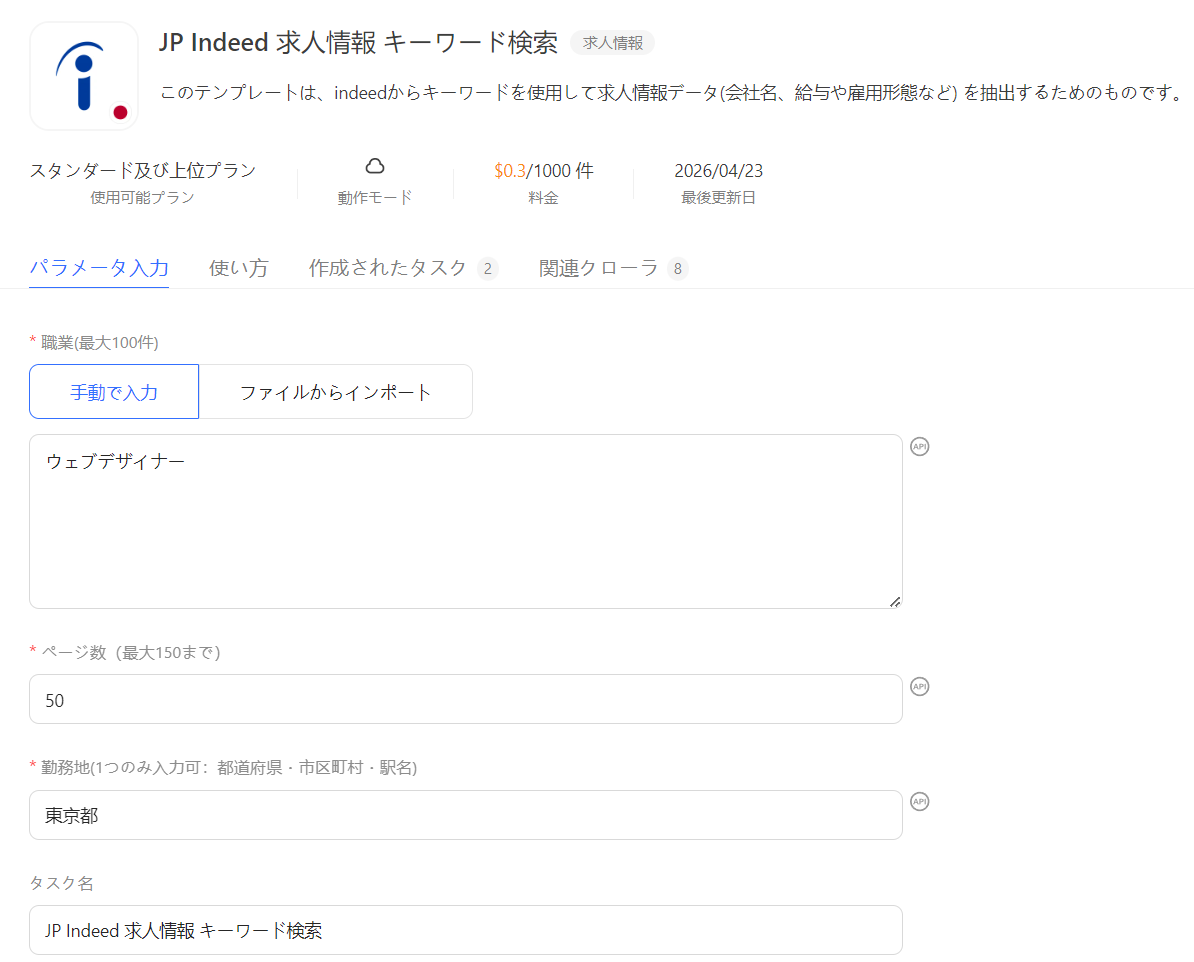
ステップ3:パラメーターの「職業」に検索キーワード、「ページ数」に何ページまで読み込むか、「勤務地」に検索エリアを入力します。
ここでは、参考として「ウェブデザイナー」「50」「東京都」と設定しました。
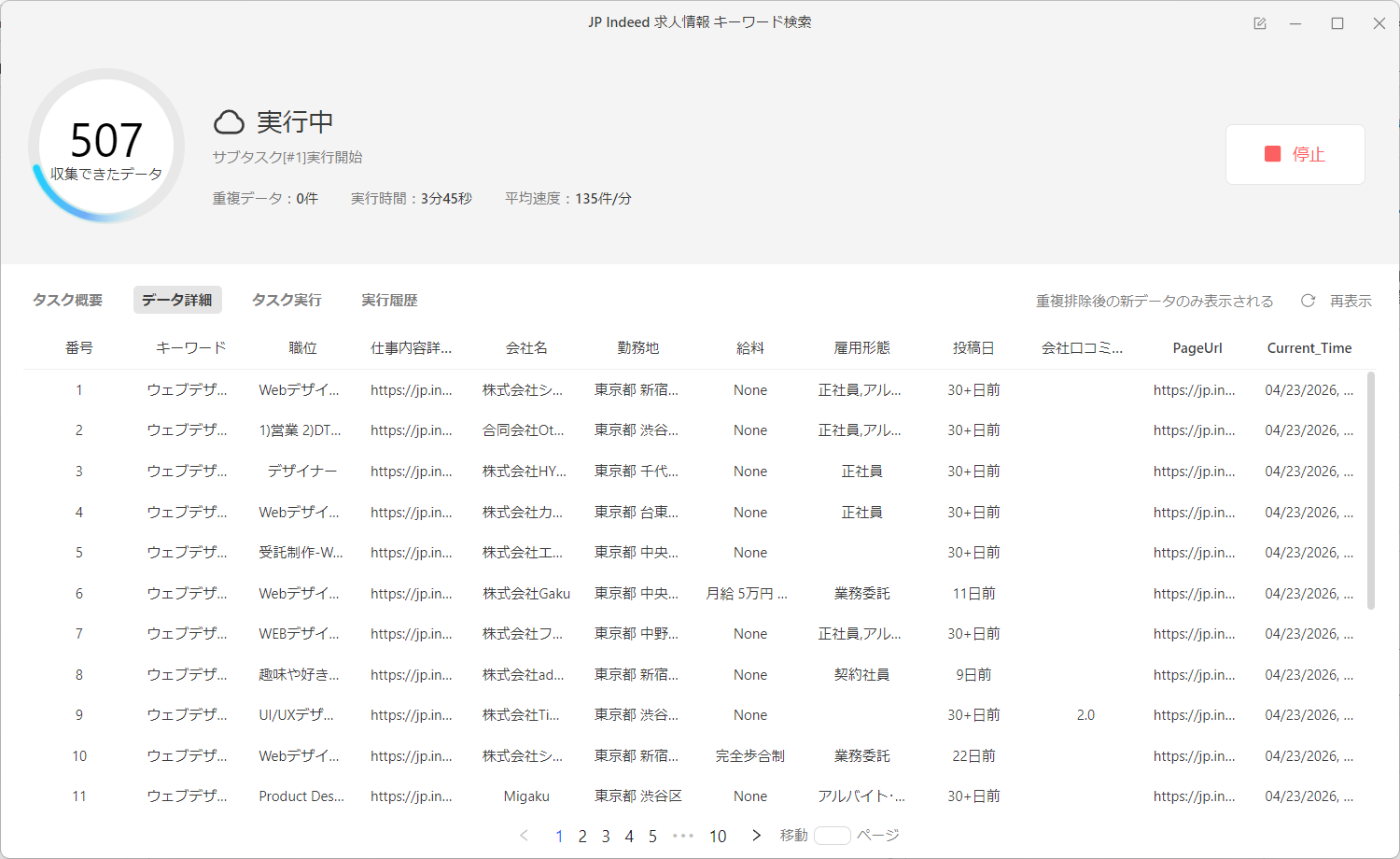
ステップ4:.「保存して実行する」をクリックして、最後に「クラウド抽出」を選択します。5分ほどで、約500件のデータが抽出されます。
データをエクスポートする CSV・Excel形式でエクスポートし、Excel/Google スプレッドシートで分析・活用できます。 タスクを自作したい場合は、こちらのOctoparseヘルプセンターの詳細チュートリアルをご参照ください。
OctoparseはIndeed(インディード)だけでなく、リクナビNEXT・マイナビ転職・ハローワークなど国内主要求人サイトの専用テンプレートも揃えています。それぞれの求人サイトを自動収集したい方は、「求人サイトのデータを効率よく収集する方法」をあわせてご覧ください。
Indeed スクレイピングの法的・倫理的注意点
IndeedをスクレイピングするにあたっT、以下の点に注意が必要です。
■ Indeedの利用規約について Indeedの利用規約では、自動化ツールによる大量データ収集を制限している条項が含まれます。個人利用・研究目的の小規模収集は実務上グレーゾーンとなることも多いですが、商業利用や大量収集の場合はIndeed公式APIの利用を検討してください。
■ 個人情報保護(個人情報保護法) 求職者の氏名・連絡先などの個人情報が含まれる場合は、日本の個人情報保護法の適用範囲となります。収集したデータの目的外利用・第三者提供には注意が必要です。
■ サーバーへの負荷について 短時間に大量のリクエストを送信するとIndeedのサーバーに負荷をかけ、アクセスブロックを受ける場合があります。
Octoparseのクラウド抽出では、IPローテーション機能により適切なリクエスト間隔を保てます。 詳細はOctoparseの利用ガイドラインをご確認ください。
FAQ(よくある質問)
Q1. Indeedのスクレイピングは違法ですか?
Webスクレイピング自体は日本では直接禁止する法律はありません。ただし、Indeedの利用規約や個人情報保護法に抵触しないよう注意が必要です。個人的な求人情報調査や市場分析目的の小規模収集であれば実務上問題になるケースは少ないですが、商業目的・大量収集の場合はIndeed公式APIの利用を検討してください。詳しくはOctoparseのブログ記事もご参照ください。
Q2. OctoparseのIndeedテンプレートは無料で使えますか?
はい、Octoparseの無料プランでもテンプレートを利用できます。ただし、無料プランには同時実行タスク数やクラウド収集の制限があります。大量データの定期収集には有料プランの利用をご検討ください。
Q3. Indeedで取得できるデータ項目は何ですか?
OctoparseのIndeedテンプレートでは、求人タイトル・会社名・勤務地・給与・雇用形態・投稿日・求人詳細URL・仕事内容の概要などを取得できます。詳細情報ページにアクセスするテンプレートでは、より詳細な仕事内容・応募条件なども収集可能です。
Q4. IndeedのスクレイピングにPythonは必要ですか?
Octoparseを使えばPythonなどのプログラミング知識は一切不要です。ノーコードのGUI操作でデータ収集の設定・実行・エクスポートができます。Pythonでの自作スクレイパーも可能ですが、Indeedは動的ページのためSeleniumやundetected-chromedriverなどの使用が必要で、難易度は高めです。
Q5. IndeedのデータをExcelで管理するには?
Octoparseで収集したデータはCSVまたはExcel(.xlsx)形式で直接エクスポートできます。Google スプレッドシートへのエクスポートも可能なため、チームでの求人データ管理・分析にもすぐに活用できます。
まとめ
今回は、求人情報を一括で自動取得する方法を解説しました。各求人サイトには、業界・業種・地域ごとに膨大な数の求人情報が掲載されています。それらのデータを使えば、営業リスト作成・市場分析・競合分析などに活用できます。
今回紹介した方法を使えば、リストアップに無駄な時間を費やす必要はありません。浮いた時間を使って、より深い検証やアクションプランの作成に役立てましょう。また、OctoparseにWebブラウザ上でテンプレート操作ができる新機能が追加されました。いつでもどこからでもアクセスし、ウェブデータを直接収集できます。テンプレートの作成・編集・実行が手軽で、効率よくデータ収集が行えます。
https://www.octoparse.jp/template/indeed-job-listing-scraper-jp
他の求人情報サイトのデータを自動取得したい場合は、以下のテンプレートも用意されています。」
https://www.octoparse.jp/template/hellowork-job-listings-url-scraper
https://www.octoparse.jp/template/doda-job-detail-scraper
https://www.octoparse.jp/template/linkedin-job-search-scraper-by-url
プログラミングスキルの有無に関わらず、様々な方法から最適なソリューションを選択できます。Octoparseは無料で使えるテンプレートも豊富に備わっているので、スクレイピングが初めての方はぜひお試しください。
競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール



