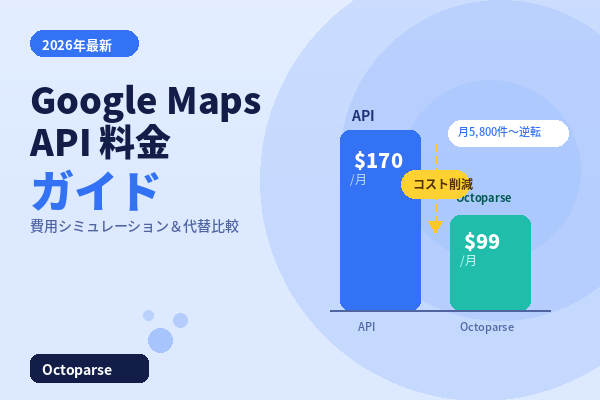
飲食店向けの営業担当者にとって、「営業リストをゼロから作る手間」は長年の課題です。食べログ スクレイピングを使えば、その課題を根本から解決できます。
本記事では、食べログ スクレイピングの合法的な活用方法から、ノーコードツール「Octoparse」を使ったうなぎ百名店データの5分一括取得まで、実際の操作手順を解説します。プログラミング不要で今日から使えるので、焼肉・寿司・ラーメンなど、あらゆる業態の営業リスト作成に応用してください。なお、食べログ スクレイピングの利用規約・合法性を先に確認したい方は、食べログのスクレイピングが禁止かどうかを解説した記事もご参照ください。
飲食店営業で営業リストが重要な理由
飲食業界向けの営業担当者であれば、「良い商材なのに全く相手にされない」という経験をした方も多いでしょう。その根本原因の多くは、ターゲット選定の精度にあります。闇雲なテレアポや飛び込み営業は、成約率が低いだけでなく担当者のモチベーション低下にもつながります。
飲食店は、エリア・ジャンル・客単価・店舗規模によってニーズが大きく異なります。たとえば、高価格帯のうなぎ専門店と大衆居酒屋では、仕入れや設備投資の予算感がまったく違います。こうしたセグメントを事前に把握し、自社商材と相性の良い層を特定することが、効率的な営業活動の出発点です。
そのために必要なのが、精度の高い営業リストです。食べログ スクレイピングを使えば、エリア・ジャンル・評点・口コミ数などのデータを組み合わせて「投資意欲が高い店舗」を絞り込み、アプローチの優先順位を素早くつけることができます。なお、スクレイピングを使った営業リスト自動作成の体系的な方法については、こちらの記事で詳しくまとめています。
営業リスト作成には「ビッグデータ」の活用が最適
食べログをはじめ、ホットペッパー・Googleマップ・SNSなど、飲食店情報はインターネット上の至るところに分散して存在しています。こうした大量のデータは「ビッグデータ」と呼ばれ、営業・マーケティング・競合調査・新規出店リサーチなど、幅広い用途で活用が進んでいます。
飲食店のビッグデータを営業活動に活用するメリットは、主に以下の3点です。
- 飲食業界のトレンドと動向をリアルタイムで把握できる
- エリア・ジャンル・評点など多軸でターゲット店舗を絞り込める
- 競合分析・新規出店リサーチ・市場調査にも同じデータを転用できる
しかし、飲食店情報を一店舗ずつ手作業で収集するのは現実的ではありません。飲食店は閉店・移転・営業変更が頻繁で、数ヶ月ごとに情報を更新するだけでも膨大な時間がかかります。こうした課題を解決するのが「食べログ スクレイピング」です。
ビッグデータ収集に役立つWebスクレイピングとは
Webスクレイピングとは、インターネット上の情報を「クローラー」と呼ばれるプログラムが自動的に巡回・収集する技術です。食べログ スクレイピングの文脈でいえば、店舗名・評点・口コミ数・住所・電話番号・営業時間・定休日といったデータをまとめて自動取得することができます。
従来は、PythonやBeautifulSoupなどのプログラミング知識が必要でした。しかし現在はノーコードツールの普及により、ITの専門知識を持たない営業担当者でも食べログ スクレイピングを手軽に実行できる環境が整っています。Webスクレイピングの仕組みや活用事例をより詳しく知りたい方は、Webスクレイピングの基礎から活用事例まで解説した記事をご参照ください。
食べログ スクレイピングは違法?利用規約で確認すべき注意点
食べログ スクレイピングを始める前に、利用規約の確認は必須です。結論から言えば、食べログの利用規約はスクレイピングを明示的に禁止していません。ただし、「収集したデータの使い方」によっては規約違反になる可能性があります。
以下のOK/NGを守ることで、安全に食べログ スクレイピングを活用できます。
- 【OK】 個人の調査・社内分析・営業リスト作成(社内利用)
- 【OK】 ログアウト状態でのスクレイピング
- 【OK】 サーバーに過度な負担をかけないアクセス間隔の設定(robots.txtではCrawl-delay 5〜10秒が推奨)
- 【NG】 収集したデータを第三者へ販売・配布
- 【NG】 口コミ・評点を自社サービスや外部メディアに転載
- 【NG】 ログイン状態でのスクレイピング(アカウント停止リスク)
食べログのrobots.txt・利用規約の詳細な解釈については、食べログのスクレイピングが禁止かどうかを解説した記事で詳しく解説しています。
非エンジニアでも使えるスクレイピングツール「Octoparse」
食べログ スクレイピングは以前、PythonやSeleniumなどのプログラミング知識が必要でした。しかし現在は、ノーコードのスクレイピングツールが普及し、営業担当者でも手軽に使えるようになっています。
その中でも「Octoparse(オクトパス・オクトパース)」は、食べログ スクレイピングで特に実績のあるツールです。Octoparseが提供する食べログ専用テンプレートは、自社テンプレート利用ランキングで第2位を獲得しており(出典:Octoparseテンプレート利用統計)、すでに多くの営業担当者・マーケター・データ担当者が活用しています。「使われているツールを使う」という選択が、最も効率的なアプローチです。他のスクレイピングツールとの比較を確認したい方は、スクレイピングツール12選の比較記事もご参照ください。
食べログはOctoparseで最も使われるテンプレート第2位
「食べログ スクレイピングは本当に実用的なのか?」という疑問に答えるのが、Octoparse自社データです。当社のテンプレート利用状況を集計したところ、食べログは全対象サイトの中で第2位にランクインしています(出典:データ収集量で見る!ウェブクローラーが訪れる人気サイト)。
本記事で紹介する「食べログ スクレイピングによる営業リスト作成」は、すでに多くのビジネスパーソンが実践している実績ある手法です。なぜ食べログがこれほど選ばれているのか、理由は3点あります。
理由1:情報の網羅性と信頼性
食べログには全国約90万件以上の飲食店情報が掲載されており、店舗名・住所・電話番号・評点・口コミ数・営業時間・定休日といった営業実務に必要なデータが一元化されています。他のグルメサイトと比較しても評点の信頼性と情報の更新頻度が高く、「訪問前に店舗状況を把握する」営業の事前準備に最適です。
理由2:百名店・アワードによるターゲット絞り込み
食べログには「百名店」「食べログアワード」など客観的基準で選ばれた優良店舗リストがあります。このリストをスクレイピングすることで、「投資意欲が高い可能性のある店舗」に絞り込んだ営業リストを最初から作成でき、闇雲に全店舗を回るより成約率が向上します。
理由3:Octoparseとの専用テンプレートによる高い相性
Octoparseは食べログ専用テンプレートを3種類(グルメ店リスト・グルメ店詳細・エリア別店舗リスト)提供しています。URLを貼り付けるだけで即座にデータ収集が開始でき、https://www.octoparse.jp/template/tabelog-store-list-scraper。
| 実ユーザーの声(ITreviewレビューより) | |
| 口コミ内容 | 「プログラミング言語は一つもわからないが、もともとあるテンプレートである程度満足いくデータ収集が可能。テンプレートの数が豊富(SUUMO、メルカリ、楽天、Yahoo、食べログなどのレシピが用意されている)」 |
| 出典 | ITreview Octoparse口コミページ https://www.itreview.jp/products/octoparse/reviews |
Octoparseで食べログ スクレイピング実践|うなぎ百名店を5ステップで一括取得
ここからは、Octoparseを使った食べログ スクレイピングの実際の操作手順を解説します。
なぜ「うなぎ店」を題材にするのか
営業戦略の鉄則は「成長市場を狙う」ことです。うなぎ店はコロナ禍での「巣ごもり×プレミアム消費」ニーズにより、飲食業界全体が低迷した時期にも売上を伸ばした数少ないジャンルです。市場が成長しているカテゴリは設備投資にも積極的な店舗が多く、営業成約率が高まりやすいという実践的なメリットがあります。焼肉・寿司・フレンチ等、他の成長ジャンルにも同じロジックが適用できます。
食べログ百名店をデータベースとして、以下の5ステップでうなぎ名店リストをスクレイピングします。
ステップ1.取得したいページのURLを取得する
食べログの「うなぎ百名店」ページ(https://award.tabelog.com/hyakumeiten/unagi)にアクセスし、URLをコピーします。
ステップ2.OctoparseにURLをペーストして「抽出開始」を実行する
Octoparseのホーム画面でURLを貼り付け「抽出開始」をクリックします。食べログ専用テンプレートを使う場合は、検索欄に「食べログ」と入力してテンプレートを選択する方法も利用可能です(設定をさらに短縮できます)。
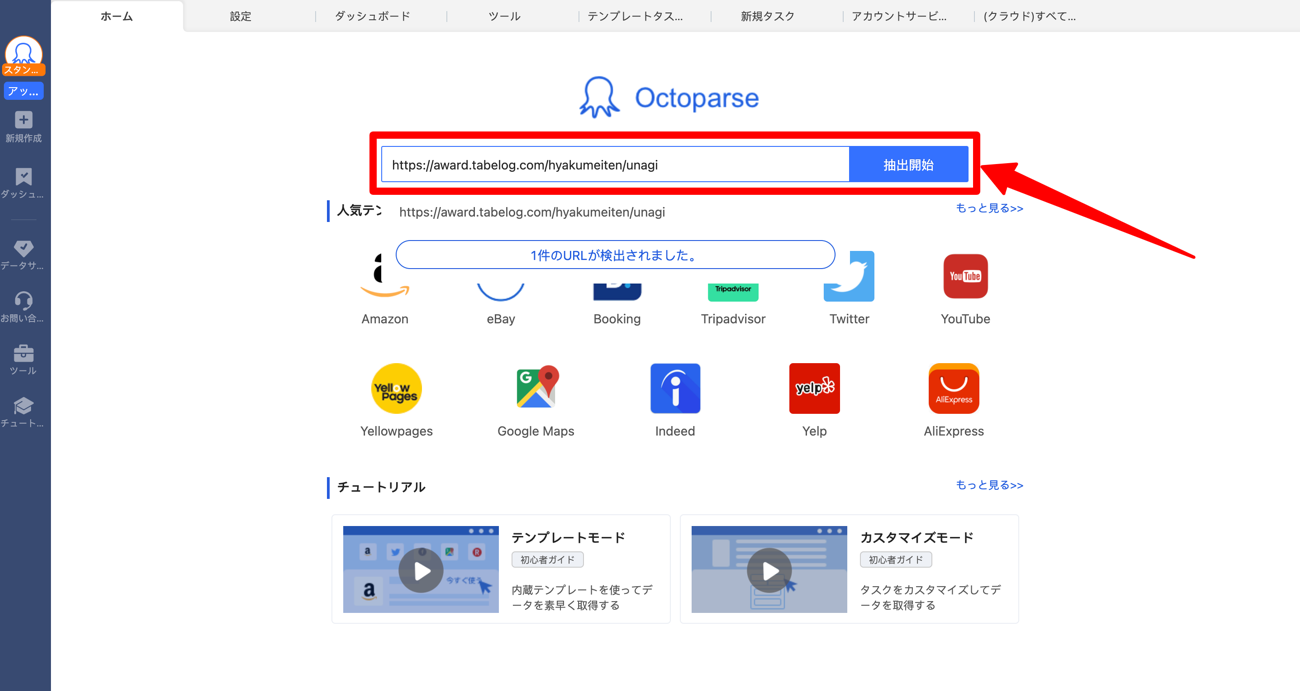
抽出が開始されると、下記のような画面が表示されます。
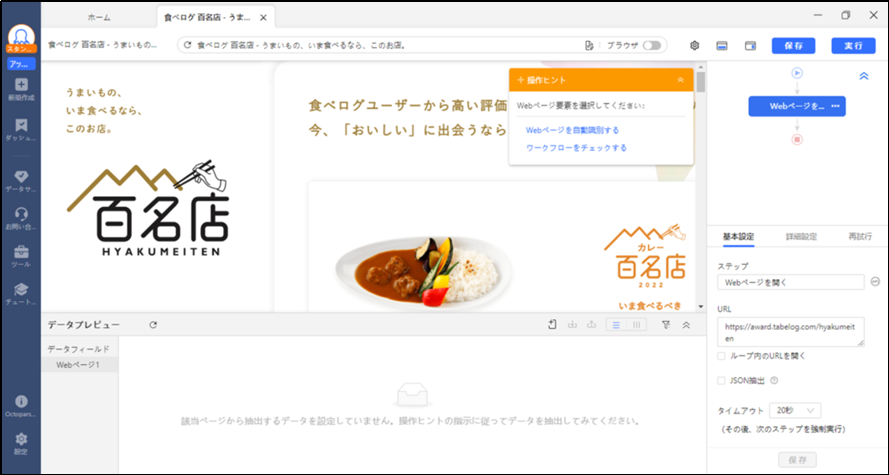
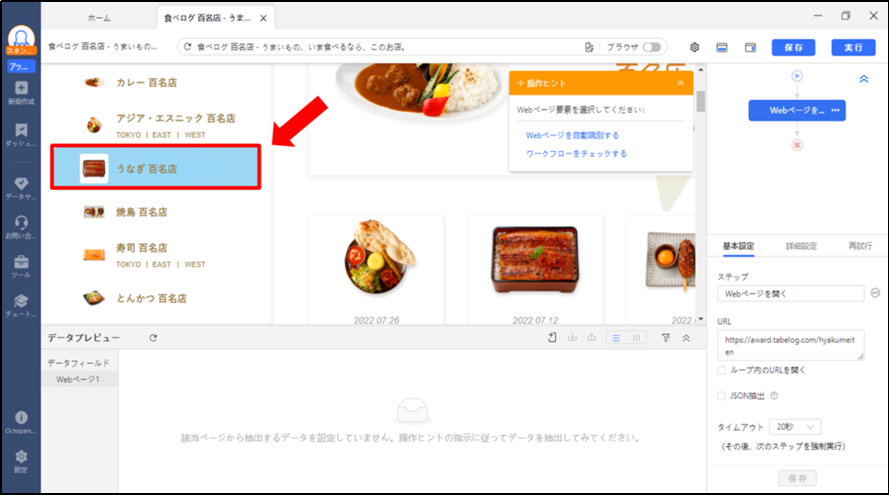
ステップ3.うなぎ店の一覧を表示する
画面左側をスクロールし「うなぎ百名店」をクリック後、「操作ヒント」から「選択したリンクをクリックする」を選択します。
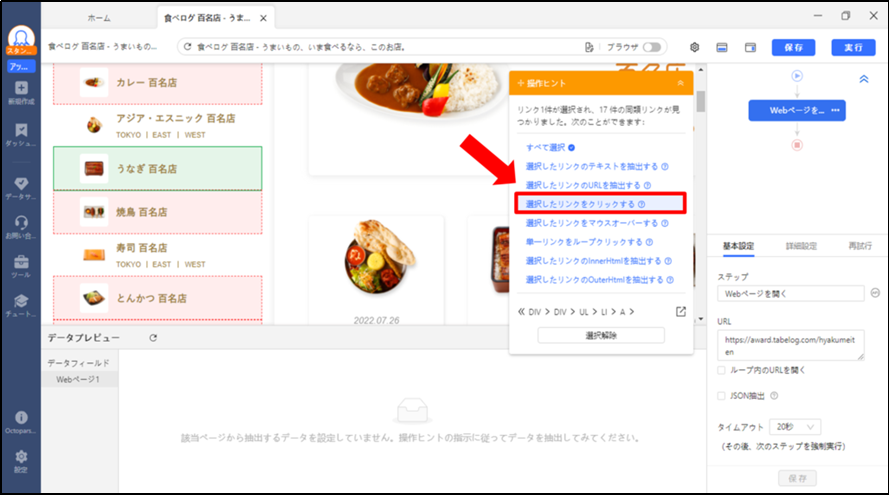
ステップ4. 食べログの店舗ページを抽出する
「操作ヒント」から「Webページを自動識別する」をクリックすると、食べログ各店舗ページへのリンクが自動で抽出されます(処理に数十秒かかります)。
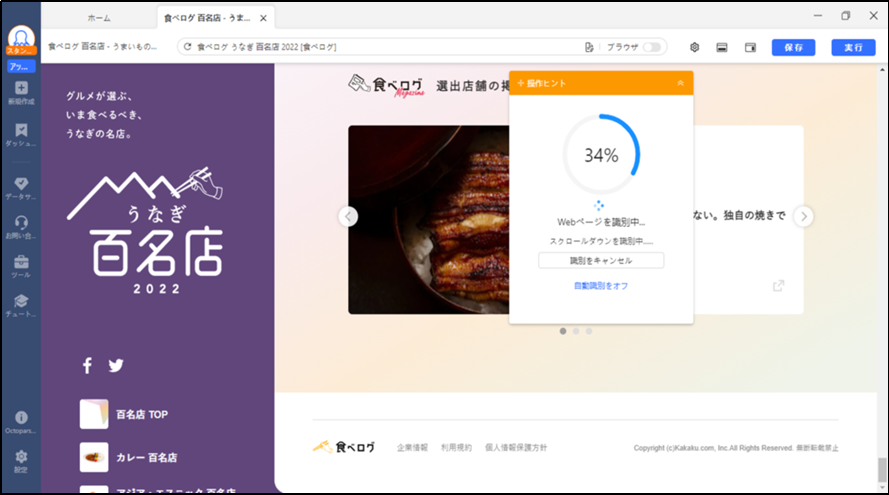
ステップ5.店舗データの抽出を開始する
ここまで設定したら準備は完了です。画面から「実行」をクリックするだけで抽出が開始されます。
抽出した情報を確認する
「実行」をクリックして抽出を開始。完了後は「エクスポート」からExcel・CSV・JSON形式で保存できます。店舗名・住所・評点・口コミ数・定休日が一覧化され、ピボットテーブルでエリア別集計も即座に可能です。
さらに多くの飲食店情報が必要な場合は、Googleマップから店舗情報をスクレイピングする方法と組み合わせることで、より網羅的な営業リストを構築できます。
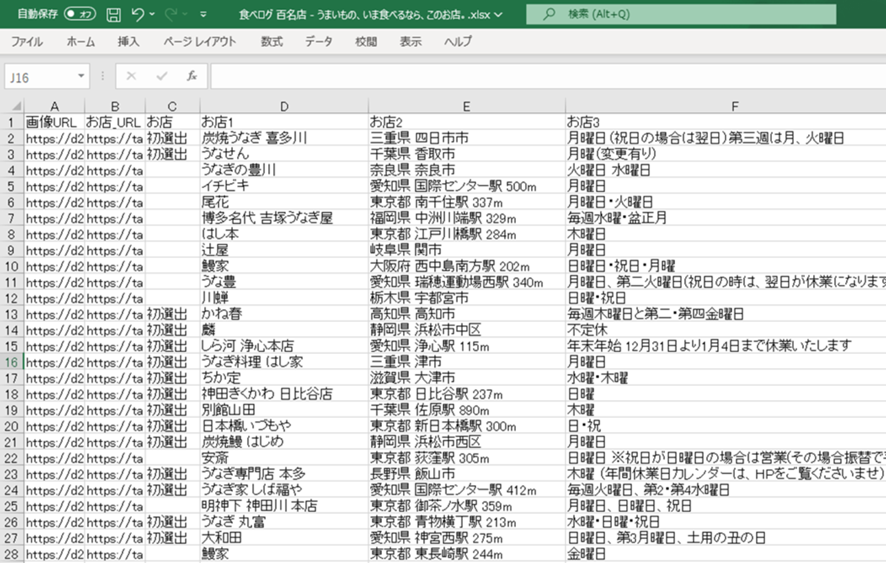
Excelで出力した後は、営業力の見せどころです。住所や定休日が一覧で抽出されるので、集計したり特定地域に絞って店舗情報を絞り込めたりできます。ピボットテーブルを組めば、どのエリアに何店舗あるかなど、お店が集中しているエリアもかんたんに把握できます。
このように、短時間で質の高い営業リストを作成し、効率的にアプローチすることが、生産性が高い営業パーソンの仕事術といえるでしょう。
Octoparseのテンプレート
プログラミング知識を持っていない方にも手軽にデータを取得するために、ソフトウェアの中で飲食業界だけではなく、様々な分野のテンプレートを用意しています。データを抽出したいURLや商品のキーワードを入力するだけで、簡単にデータを抽出することができます。
そして、ブラウザ上でテンプレートを操作し、ウェブデータを直接収集できるようになりました。いつでもどこからでもアクセスし、ウェブページからデータを直接収集できます。テンプレートの作成・編集・実行が手軽に行え、ストレスなく効率的にデータ収集ができます。
https://www.octoparse.jp/template/tabelog-details-scraper
FAQ(よくある質問)
Q1. 食べログ スクレイピングではどんなデータが取得できますか?
食べログ スクレイピングを活用すると、営業リスト作成に必要な以下の情報を一括取得できます:
店舗名
住所
電話番号
評点
口コミ数
営業時間・定休日
これらのデータを組み合わせることで、 「高評価 × 口コミ数が多い店舗」など、成約確度の高いターゲット抽出が可能になります。
Q2. 食べログ スクレイピングとGoogleマップはどちらを使うべきですか
Google Mapsとの違いは以下の通りです:食べログ スクレイピング:評点・口コミの信頼性が高く、質の高い店舗選定に向いているGoogleマップ:掲載数が多く、網羅的なリスト作成に向いている
実務では、 👉 食べログ スクレイピングで精査 → Googleマップで拡張 という併用が最も効果的です。
Q3. 食べログ スクレイピングで取得したデータはどう活用すれば良いですか?
取得データはそのまま使うのではなく、以下のように加工することで営業効率が大幅に向上します:
- 評点 × 口コミ数で優先度スコア化
- エリア別・業態別でセグメント分け
- 定休日を考慮したアプローチ設計
特にExcelのピボット分析を活用すれば、
「攻めるべきエリア・ジャンル」が可視化され、無駄な営業を削減できます。
Q4. 食べログ スクレイピングは他の用途にも使えますか?
はい、営業リスト作成以外にも幅広く活用できます:
- 競合分析(人気店舗の特徴把握)
- 新規出店リサーチ(エリア分析)
- 市場調査(トレンド把握)
また、Octoparseのようなツールを使えば、
食べログ以外のEC・不動産・SNSなどにも応用可能です。
👉 一度仕組みを作れば、複数業界で横展開できるのが強みです。
Q5. 食べログ スクレイピングで取得した電話番号に営業しても問題ありませんか?
食べログ スクレイピングで取得した公開情報をもとに営業すること自体は一般的ですが、以下に注意が必要です:
- 過度なテレアポや迷惑行為は避ける
- 個人情報の不適切利用をしない
- 営業時間・業態に配慮する
重要なのは、
👉 **「量」ではなく「精度の高いターゲット選定」**です。
食べログ スクレイピングを活用すれば、
闇雲な営業ではなく、ニーズに合った店舗への効率的なアプローチが可能になります。
まとめ
本記事では、食べログ スクレイピングの基礎知識・注意点から、Octoparseを使ったうなぎ百名店データの一括取得まで、実際に使える手順を解説しました。
ポイントをまとめると:
- 食べログ スクレイピング自体は利用規約上問題なし(ただしデータの商用転売・転載は禁止)
- Octoparseの食べログテンプレートは自社利用ランキング第2位の実績。プログラミング不要で最短5分で営業リストが完成する
- うなぎ・焼肉・寿司など業態を変えるだけで、あらゆる飲食ジャンルの営業リストに応用可能
- 終業時にスクレイピングをセットしておけば、翌朝出勤時には最新の営業リストが完成している
食べログ以外の情報源と組み合わせることで営業リストをさらに強化できます。ホットペッパービューティーのサロン情報収集方法やiタウンページからの営業リスト自動作成もぜひご活用ください。
Octoparseは無料プランから利用可能。まずはhttps://www.octoparse.jp/template/tabelog-store-list-scraperところから始めて、食べログ スクレイピングによる営業効率化を実感してください。

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール