「Webクローラーを自作したいけど、プログラミングの壁が高すぎる」と感じたことはありませんか?
Webデータの自動収集は、競合分析・価格モニタリング・営業リストの自動作成など、あらゆるビジネス場面で活用されています。しかし実際にPythonでWebクローラーを自作しようとすると、ライブラリのインストール・非同期処理・動的サイト対応など、初心者には多くの壁が立ちはだかります。
この記事では、Pythonによるクローラー自作の基本コードを紹介しつつ、「コードなしで今日からWebクローラーを動かす」ノーコードの代替手段も比較解説します。目的・スキルに応じた最適な方法を選んでください。
「でも、本当に自分でできるの?」と思う方のために、まずOctoparseで実際に5分でデータを取得した例をご覧ください。
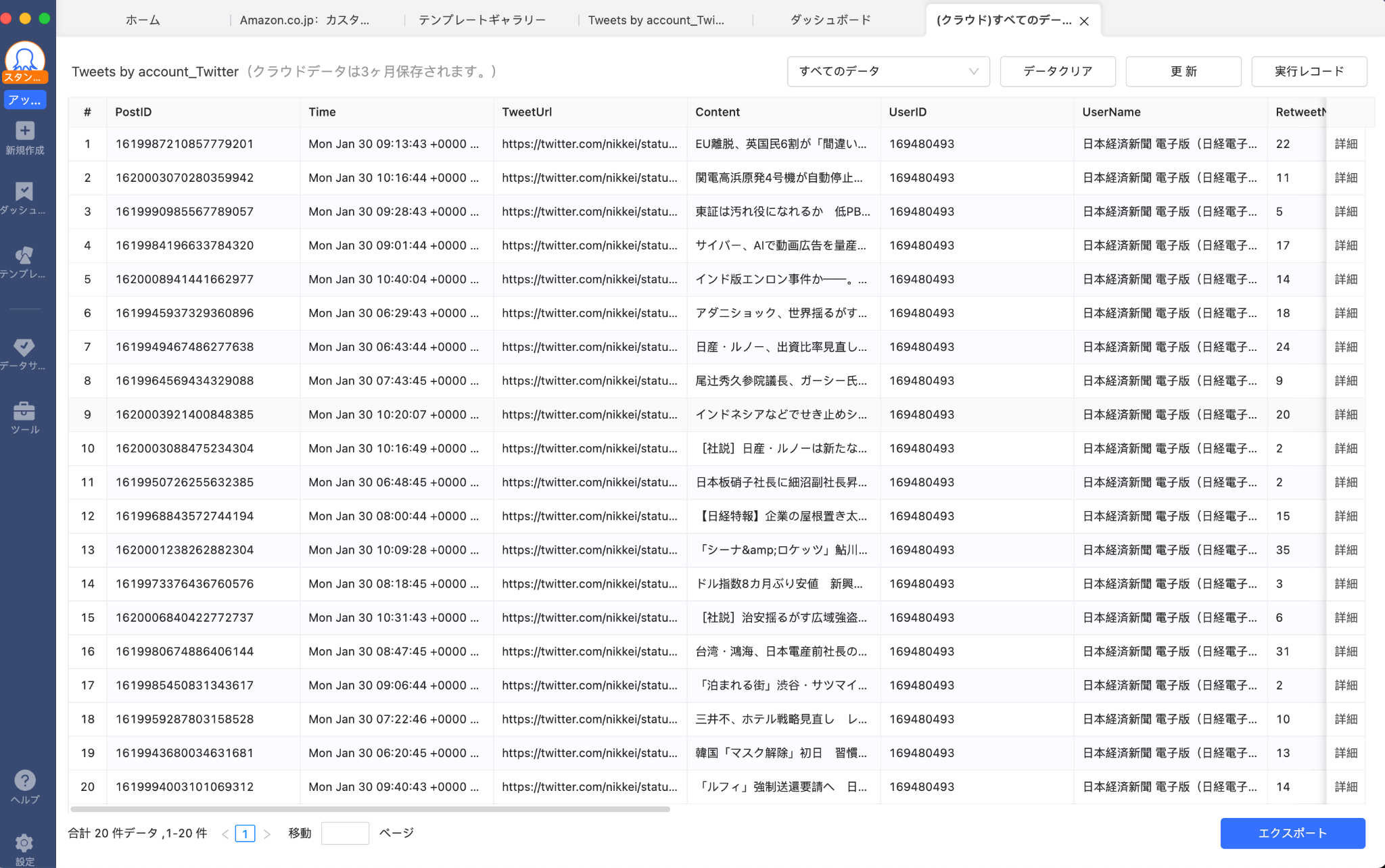
下の画像は、Octoparse(オクトパス・オクトパース)を使ってX(旧Twitter)の情報を収集した結果です。ポスト・発表時間・URL・内容・ユーザー名などが、クリック操作だけで自動的に構造化データとして取得されています。
▲ Octoparseのデータプレビュー画面。取得したデータは、CSV・Excel(.xlsx)・JSON・HTMLなど複数形式でそのままエクスポート可能。ExcelやGoogleスプレッドシートに貼り付けてすぐ分析に使えます。 この操作に必要なのは、URLを貼り付けてクリックするだけ。コードは1行も書いていません。
競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール

Webクローラーとは?仕組みをわかりやすく解説
Webクローラーとは、インターネット上のWebサイトを自動的に巡回し、ページのデータを取得するプログラムです。Googleの検索エンジンも、自社クローラー「Googlebot」でWebサイトをスキャンすることで検索インデックスを作成しています。
Webクローラーを自作・活用することで、大量のWebページを人手なしに効率よく巡回し、必要なデータを自動収集できます。基本的な動作フローは以下の通りです。
- 開始URLを設定:クローラーが最初に訪問するページのURLを指定します。
- ページのHTMLを取得:指定URLにHTTPリクエストを送信し、WebページのHTMLデータを取得します。
- リンクを解析して新URLを取得:取得したHTMLから他ページへのリンクを抽出し、新たなURLリストを作成します。
- 新しいページに移動して繰り返す:取得リンクをもとに次ページに移動し、同じ処理を再帰的に繰り返します。
- データの保存:収集したデータをCSV・JSON・SQLなどの形式で保存します。
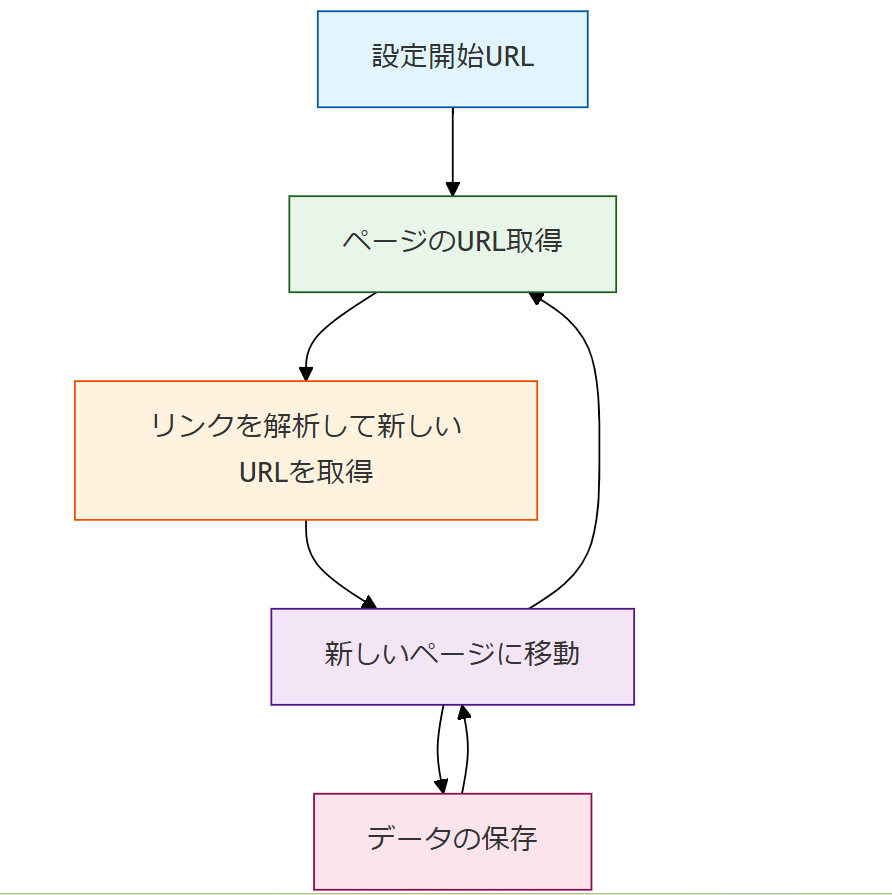
クローラーの設計次第で、特定テーマの記事のみ収集したり、特定サイトに絞って情報取得したりすることも可能です。Webクローリングとスクレイピングの違いや合法性についても合わせてご確認ください。
なぜWebクローラーが必要なのか?
インターネット上には無数のWebページが存在し、日々膨大な量の情報が更新されています。手作業での収集・整理は現実的ではありません。
例えば、企業が競合サイトの価格情報を定期取得したり、研究者が特定分野のニュース記事を収集したりする際に、Webクローラーは大きな力を発揮します。さらに、サイトの更新頻度が高い場合でも、クローラーを活用すれば新しい記事・価格変動・製品情報の更新を自動取得し、データを常に最新状態に保つことが可能です。
Webクローラーで実現できること:主な活用シーン3選
1. コンテンツ集約(コンテンツアグリゲーション)
様々なメディアのコンテンツを1つのプラットフォームに集約します。情報配信サービス「SmartNews」は複数のニュースメディアから記事をクローリングし、カテゴリ別に配信する代表的な例です。コンテンツ集約ビジネスの実践事例も参考にしてみてください。
2. 感情分析(センチメント分析)
製品・サービスに対するユーザーの態度や感情を分析するために、レビューやSNSコメントを大量収集します。感情分析は、マーケティング戦略の改善やブランドモニタリングに欠かせない手法です。YouTubeコメントをスクレイピングで自動取得する方法も合わせてご覧ください。
3. 見込み客の獲得(リード獲得)
従来の展示会・訪問営業による名刺収集に代わり、Webクローラーを使えばリクナビ・食べログ・iタウンページなどから企業情報を自動収集できます。無料ツールで営業リストを自動作成する方法も参考にどうぞ。
Webクローラーを自作する2つの方法:Python vs ノーコード徹底比較
Webクローラーを構築する方法は大きく2つに分かれます。それぞれの特徴を以下の比較表で確認してください。
| 比較項目 | Pythonで自作 | Octoparse(ノーコード) |
|---|---|---|
| 学習コスト | 数週間〜数ヶ月 | ⚡ 最短5分で開始 |
| 必要スキル | Python・HTML・HTTP知識 | ✅ 不要(マウス操作のみ) |
| 動的サイト対応 | Selenium等の別途設定が必要 | ✅ デフォルト対応(JS・Ajax) |
| スケジュール自動実行 | Cronジョブ等の別途設定 | ✅ GUI上で簡単設定 |
| メンテナンス | サイト変更のたびコード修正 | ✅ ビジュアルエディタで即修正 |
| コスト | 無料(サーバー費別途) | ✅ 無料プランあり(10タスク) |
| カスタマイズ性 | ◎ 非常に高い(上級者向け) | ◯ テンプレート+カスタムモード |
Pythonでのクローラー自作はカスタマイズ性に優れていますが、実用レベルに達するまでの学習コストが高めです。一方、ノーコードでスクレイピングを始めるならOctoparse(オクトパス)が最短ルートです。
方法1:Pythonでクローラーを自作する
プログラミングでWebクローラーを自作する場合、最も手軽なのはPythonです。PHP・Java・C/C++でも構築可能ですが、Pythonは文法がシンプルで初心者にも比較的学びやすい言語です。
以下は、指定URLのHTMLを取得して他ページのリンクを再帰的に抽出するPythonクローラーのサンプルコードです。
このコードは学習用のシンプルなサンプルです。実用では以下の点も考慮が必要です。
- 対象サイトのrobots.txtと利用規約を必ず確認する
- time.sleep()でアクセス間隔を確保し、サーバーに過負荷をかけない
- 動的サイト(JS/Ajax)にはSeleniumなど別途ブラウザ自動化ツールが必要(詳細:PythonとSeleniumを使ったクローラー開発手順)
- IPブロックを回避しながらスクレイピングを実行する対策も必要
Pythonは比較的扱いやすい言語ですが、実用レベルのWebクローラーを自作できるようになるには、少なくとも数週間〜数ヶ月の学習が必要です。初心者には「Progate」「ドットインストール」などがおすすめです。また、オープンソースのWebクローラーツール10選も参考になります。
方法2:Webスクレイピングツール(ノーコード)を活用する
プログラミング学習に時間を割けない方、今すぐWebクローラーを動かしたい方には、Webスクレイピングツールの活用が最短ルートです。
Octoparse(オクトパース・オクトパス)は、世界180か国以上・100万人超のユーザーが利用するノーコードWebスクレイピングツールです。コード記述ゼロで、ビジュアルエディタのクリック操作だけでクローリング&スクレイピングが可能。初心者でも平均15分以内に最初のクローラーを起動できます。
Octoparseが選ばれる主な理由:
- ✅ ノーコード設計:プログラミング知識一切不要
- ✅ 豊富なテンプレート:食べログ・Amazon・Indeed・Google Mapsなど100種以上
- ✅ 動的サイト完全対応:JavaScript・AJAX・無限スクロールもデフォルト対応
- ✅ クラウド自動実行:24時間365日スケジュール実行(ローカル抽出の最大20倍速)
- ✅ 多様なデータ形式出力:CSV・Excel・JSON・DB(MySQL・SQL Server・Oracle)対応
例えば、Google検索結果をクロールして特定キーワードに関連するページを収集することも可能です。他のスクレイピングツールとの比較も参考にしてみてください。
Octoparseを使ってX(旧Twitter)から特定のポストをスクレイピングする
ここでは実際にOctoparseのテンプレートを使ってX(旧Twitter)のデータを取得する手順を紹介します。このテンプレートで取得できるデータフィールドは以下の通りです:ポスト内容(Text)・投稿日時(Post Time)・いいね数(Likes)・リポスト数(Retweets)・返信数(Comments)・閲覧数(Views)・アカウントURL
ステップ1:Octoparseをパソコンにダウンロードします。起動後、管理画面にアクセスしてください。
ステップ2:テンプレート選択画面で「SNS」カテゴリを選び、目的に合ったTwitterテンプレートを選択します(2025年2月時点で6種類)。ここでは「Twitter Scraper (by Account URL)」を使用します。
| テンプレート名 | 取得できる主なデータ |
|---|---|
| https://www.octoparse.jp/template/twitter-scraper-by-keywords | キーワードでポストを検索→内容・リプライ数・RT数・いいね数・閲覧数 |
| https://www.octoparse.jp/template/get-twitter-cookies | クッキー情報の取得 |
| https://www.octoparse.jp/template/twitter-scraper-by-hashtag | アカウントの各ポスト内容・投稿日時・いいね数・RT数・閲覧数 |
| https://www.octoparse.jp/template/twitter-scraper-by-hashtag | ハッシュタグから最新ポスト・返信数・リポスト数・いいね数・閲覧数 |
| https://www.octoparse.jp/template/tweets-comments-scraper-by-search-result-url | ポスト内容・投稿者・投稿時間・返信内容・返信送信者・返信時間 |
| https://www.octoparse.jp/template/twitter-follower-list-scraper | フォロワー・フォロー情報 |
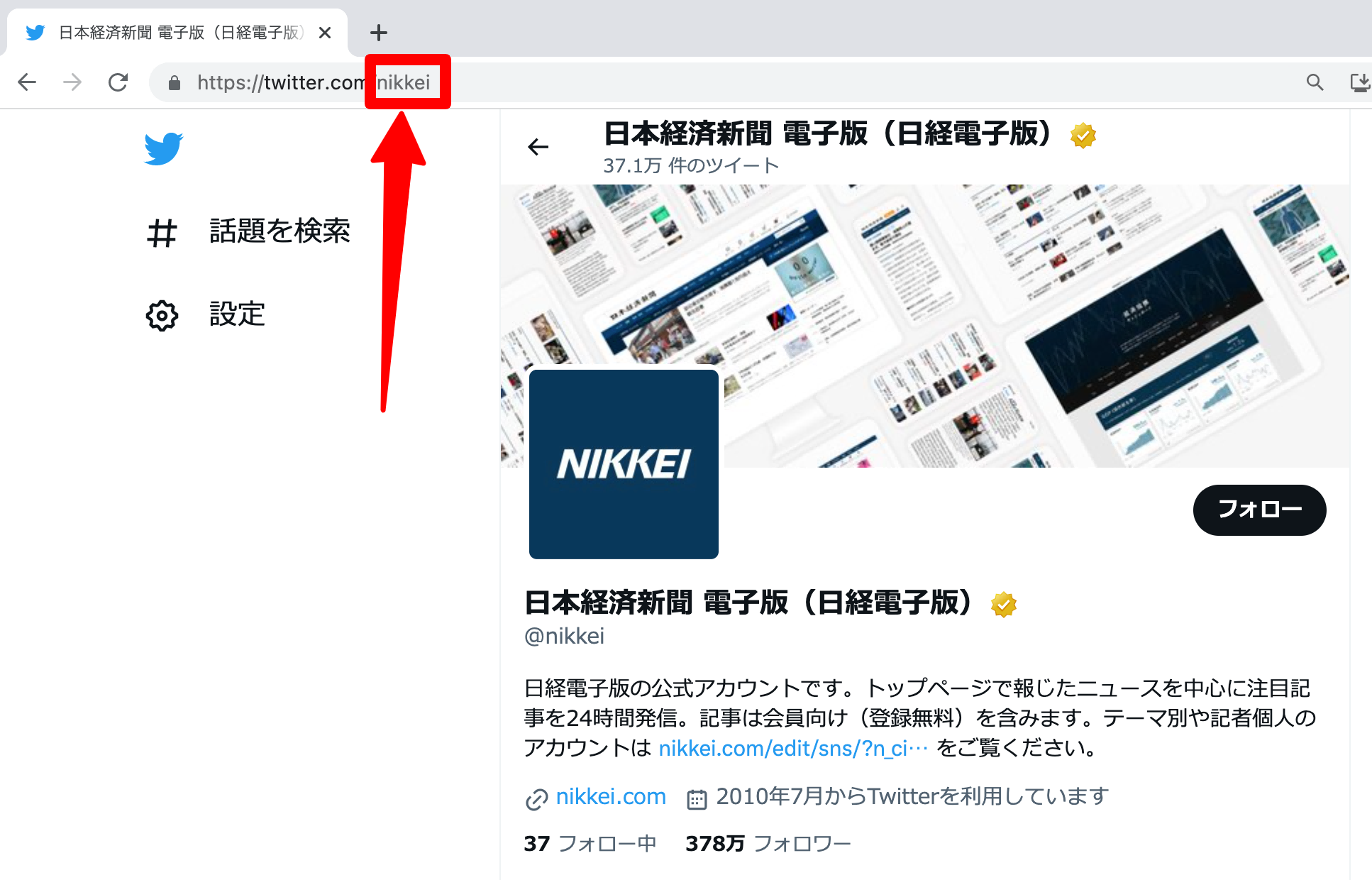
ステップ3:テンプレート起動後、パラメーター入力欄に以下を入力して「保存して実行」をクリックします。
- スクレイピングしたいXアカウント名(最大10個まで / 1行に1つ入力)
- ページサイズ(スクレイピングしたいページ数)
例:「日本経済新聞 電子版」のアカウントなら「nikkei」と入力します。
ステップ4:抽出方法(ローカル or クラウド)を選択して実行します。データ量が少なければローカル抽出で対応可能。クラウド抽出は最大20倍の速度で処理できます(有料プランが必要)。
ステップ5:数分後に抽出完了。画面右下の「エクスポート」ボタンで、Excel・CSV・HTML・JSON形式でデータをダウンロードできます。
詳しい手順はこちら:X(旧Twitter)からデータを無料取得する詳細手順
【新機能】OctoparseをAI・外部ツールと連携させる:MCP対応
「収集したWebデータをAIに自動分析させたい」「自社システムにリアルタイムでWebデータを流し込みたい」という方に朗報です。
Octoparse(オクトパス)は新たにMCP(Model Context Protocol)に対応しました。Claude Desktop・Cursor・Gemini CLIなどのAIクライアントから、自然言語でOctoparseのスクレイピングテンプレートを呼び出し、リアルタイムにWebデータをAIワークフローへ流し込むことが可能です。
- 「毎日の競合価格データを自動取得してSlackに通知したい」
- 「AIエージェントにWebデータを自動リサーチさせたい」
- 「自社のデータパイプラインにWebスクレイピングを組み込みたい」
このような自動化・システム連携のニーズがある方は、Octoparse MCP機能の詳細とMCP使用チュートリアルをご確認ください。また、OctoparseのAPIでシステム連携する方法もご参照ください。
Octoparseを使用する際の注意点
Webサイトの構造が複雑な場合、テンプレートモードではWebスクレイピングを完全に実行できないことがあります。
①テンプレートで対応できない複雑なサイトには「カスタマイズモード」を活用しましょう。ログインが必要なサイト・JavaScriptの動的インタラクションが多いサイトに対応でき、柔軟なワークフロー設定が可能です。クローラーとXPathの関係を理解しておくと、カスタム設定が容易になります。
②robots.txtや利用規約の確認はどのツールでも必須です。スクレイピングの合法性についてよくある誤解を解説した記事も参考にしてください。
③サーバー負荷を抑えるため、アクセス間隔の設定を忘れずに。OctoparseのIPローテーション機能でIPブロックを回避しながらスクレイピングを実行することも可能です。
よくある質問(FAQ)
Q1. WebクローラーとWebスクレイピングの違いは何ですか?
Webクローラーはリンクをたどって複数ページを「巡回」するプログラムで、スクレイピングは特定のページから「データを抽出」する処理です。多くの場合、クローリング(巡回)→スクレイピング(抽出)という流れで使われます。Octoparse(オクトパス)はどちらもGUI操作で設定可能です。
Q2. Webクローラーを自作するには何から始めればいいですか?
まずPythonの基礎(変数・ループ・関数)を学び、requestsとBeautifulSoupライブラリをインストールして小さなスクリプトを試すのが定石です。学習に時間を割けない場合は、ノーコードのOctoparse(オクトパス)が最短ルートです。
Q3. Webクローラーの使用は違法ですか?
技術自体は違法ではありません。ただし、対象サイトのrobots.txtや利用規約に違反するクロール、著作権のあるデータの無断利用は法的問題になる可能性があります。詳しくはスクレイピングの合法性についてよくある誤解をご参照ください。
Q4. JavaScript(動的サイト)のクローリングはできますか?
Pythonのrequestsライブラリだけでは動的サイトに対応できません。Seleniumなどのブラウザ自動化ツールが別途必要です(参考:PythonとSeleniumを使ったクローラー開発手順)。Octoparseは内蔵ブラウザがJavaScript・Ajaxを自動処理するため、追加設定不要で動的サイトに対応できます。
Q5. 無料でWebクローラーを使い始める方法は?
Octoparse(オクトパス)の無料プランでは10タスクまでコスト0で利用できます。クレジットカード登録不要でアカウント作成後すぐに使い始められます。
Q6. OctoparseをClaude・CursorなどのAIと連携できますか?
はい、OctoparseはMCP(Model Context Protocol)に対応しており、Claude Desktop・Cursor・Gemini CLIなどのAIクライアントから自然言語でスクレイピングを呼び出せます。AIエージェントに最新の競合データを自動収集・分析させるワークフローを簡単に構築できます。
まとめ:Webクローラー自作の最速ルートはどれか?
この記事では、Webクローラーの仕組みと、ゼロから構築する2つの方法(Python自作 / Octoparseノーコード)を解説しました。
データ活用が求められる現代において、必要な情報を素早く・正確に収集できるかどうかは、ビジネスの成長や意思決定のスピードに直結します。
「プログラミングをこれから覚えるのは難しそう」「まず試してみたい」という方は、ノーコードのOctoparse(オクトパース・オクトパス)を活用してみてください。
- ✅ 無料プランで10タスクまで即日利用可能(クレジットカード不要)
- ✅ 日本語サポート・チュートリアル完備
- ✅ 食べログ・Amazon・X(旧Twitter)など人気サイトのテンプレートをすぐ利用
- ✅ AIツールとのMCP連携でさらなる自動化も実現
データを活用する第一歩として、今すぐWebクローラーを体験してみてください。
競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール



