Webページ上の画像をすべて保存したいとき、1枚ずつ保存するのは非常に面倒です。単調な作業の繰り返しに嫌気が差したり、他の業務に取りかかれず業務生産性を大きく低下させます。
そこでおすすめなのが、Webサイトから画像を一括ダウンロードできる「Webスクレイピングツール」の活用です。Webスクレイピングツールを使えば、わずか5分程度の設定作業だけで、Webクローラーを作成し、サイト内に掲載されている画像の自動取得が可能になります。
本記事では、Webサイトから画像を一括ダウンロードする「Webスクレイピングツール」の活用方法を手順に沿って解説します。
Webスクレイピングとは
Webスクレイピングとは、Webサイトから特定の情報を自動的に抽出するコンピュータソフトウェア技術のことです。Webスクレイピングを使えば、インターネット上に存在するWebサイトやデータベースを探り、大量のデータの中から特定のデータのみを抽出させることができます。
例えば、Amazonに出品されている商品価格、レビュー、メーカー、ASINコードなど、あらゆる情報を自動で抽出してくれるため、手作業で商品リストを作成する手間が不要になります。Webスクレイピングを活用することで、面倒で退屈なデータ抽出プロセスから解放され、付加価値の高い市場分析などに時間を費やすことが可能です。
Webスクレイピングは、画像ダウンロードに関しても作業を自動化するのに最適な選択肢です。Webページを手作業でクリックする代わりに、スクレイピングタスクを設定するだけで、クローラーがすべての画像URLを取得してくれます。抽出した画像URLは、画像ダウンロードツールにコピーすれば、わずかな時間で一括ダウンロードが完了します。
WebスクレイピングツールOctoparseとは
Webスクレイピングの領域には多くのツールが存在しますが、Octoparse(オクトパス)はその中でも多くのユーザーに支持されています。このクラウドベースのツールは、特定のソフトウェアをインストールし、アカウントを開設するだけで、簡単に利用開始できます。
ここでは、Octoparseの魅力的な機能をいくつかピックアップしてご紹介します。興味を持たれた方は、公式ページから詳細を確認してみてください。
リンク:Octoparse公式ページ
手軽にWebスクレイピング
Octoparseは、プログラミングの経験がない方でも、簡単にウェブから情報を取得できるツールとして設計されています。専用のデザインツールを使って、視覚的にスクレイピングの流れを作成することができます。
AI技術を駆使したスクレイピング
Octoparseは、AI技術を活用して、自動的にデータを取得する機能を持っています。このAuto-detect機能により、効率的に情報収集を行うことが可能です。さらに、スクレイピング中に有用なヒントも提供されるため、初心者でも安心して利用できます。
多彩なスクレイピングテンプレート
Octoparseには、様々なウェブサイト向けのテンプレートが豊富に用意されています。これらのテンプレートを利用することで、特定のサイトからの情報収集が非常に簡単になります。
たとえば、Amazon向けのテンプレートを使用することで、商品のレビューや価格の調査を手間なく行うことができます。テンプレートを試してみたい方は、以下のリンクからアクセスしてみてください。
リンク:Webスクレイピングテンプレート
ステップ1. Webスクレイピングツールをダウンロードする
今回は、数あるWebスクレイピングツールの中から「Octoparse(オクトパス)」を例に挙げ、実際に画像をダウンロードする手順を紹介します。プログラミングの知識・経験は一切必要ありませんので、ぜひ実際に操作してみてください。
Octoparseのトップページを開き、「ダウンロード」をクリックします。お使いのOSにあわせて、ダウンロードをしてください。
Octoparseをダウンロードする
注:Octoparseでは無料プランを提供しています。このガイドに記載されている機能にお金を払う必要はありません。
ステップ2.画像を一括ダウンロードする
もうすぐハロウィンなので、今回はGoogle画像検索の「スイーツ」の画像を例にしてみましょう。
サンプルURL: 【Google】スイーツ
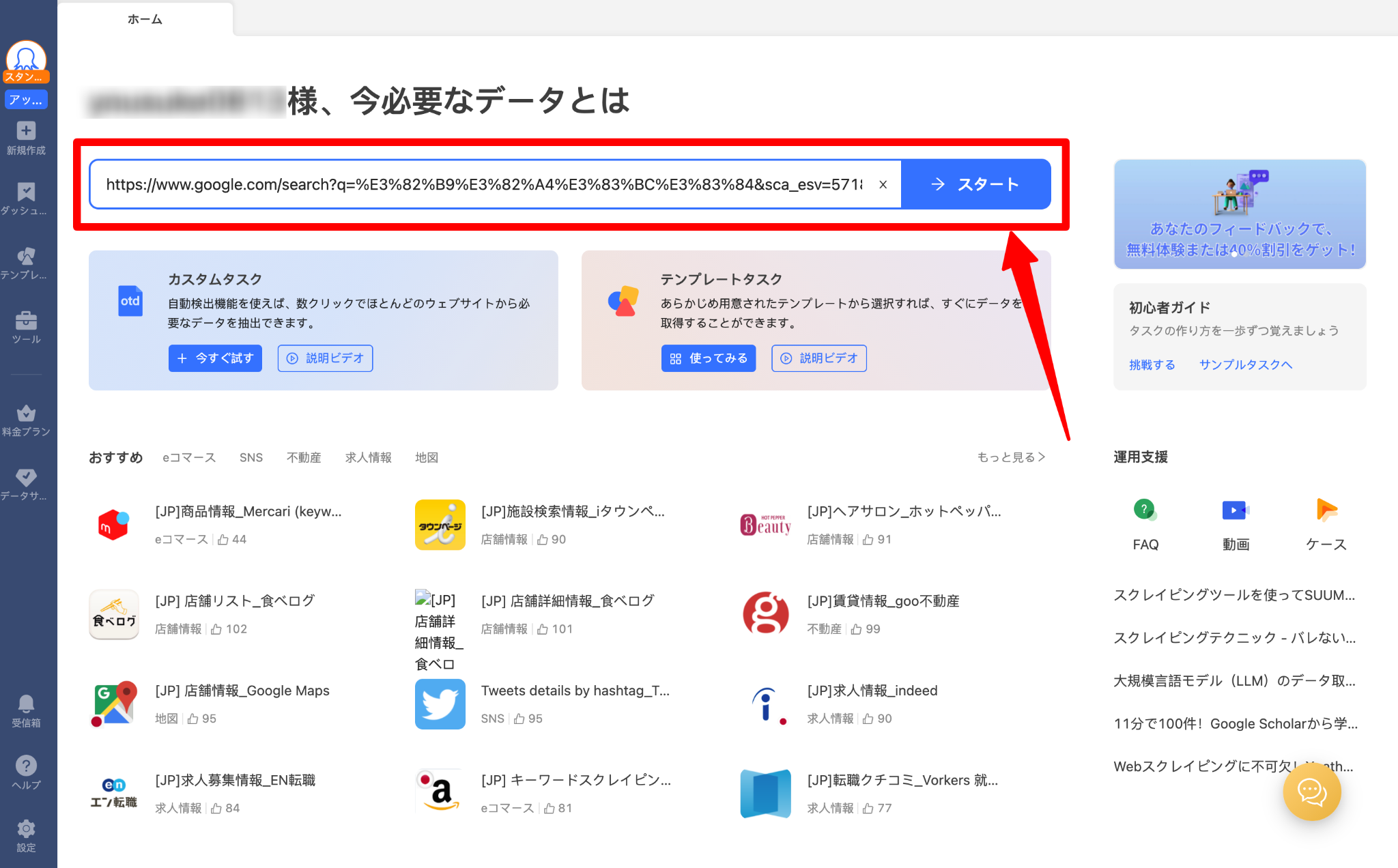
1.Octoparseを起動し、WebページのURLを入力します。次に「抽出開始」を クリックして進みます。
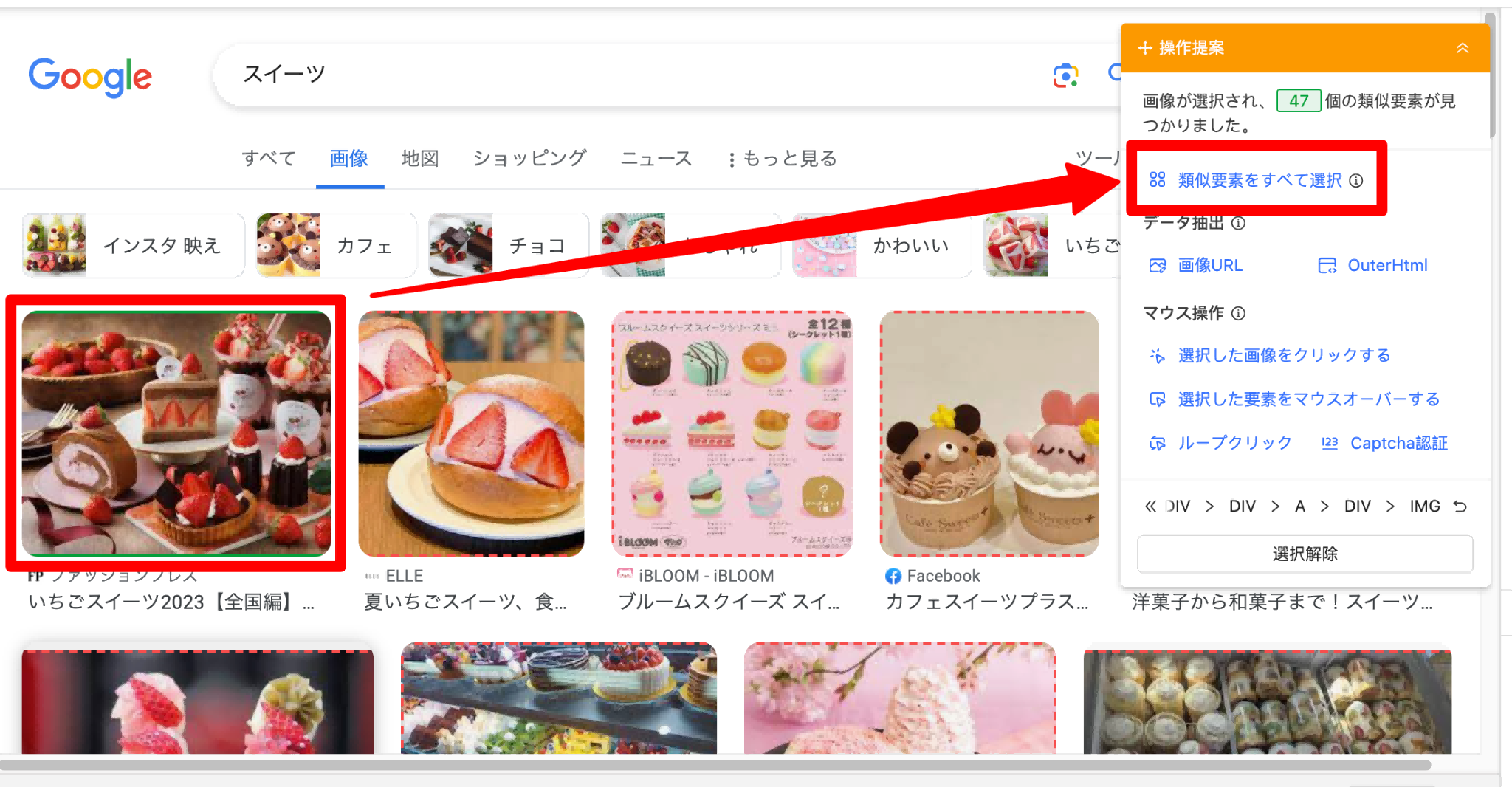
2.Webページ内で、任意の画像を1枚クリックします。続いて、操作提案ボックスから「類似要素をすべて選択」をクリックします。
3.データフィールドが表示されるので、同じく操作提案から「画像URL」をクリックします。
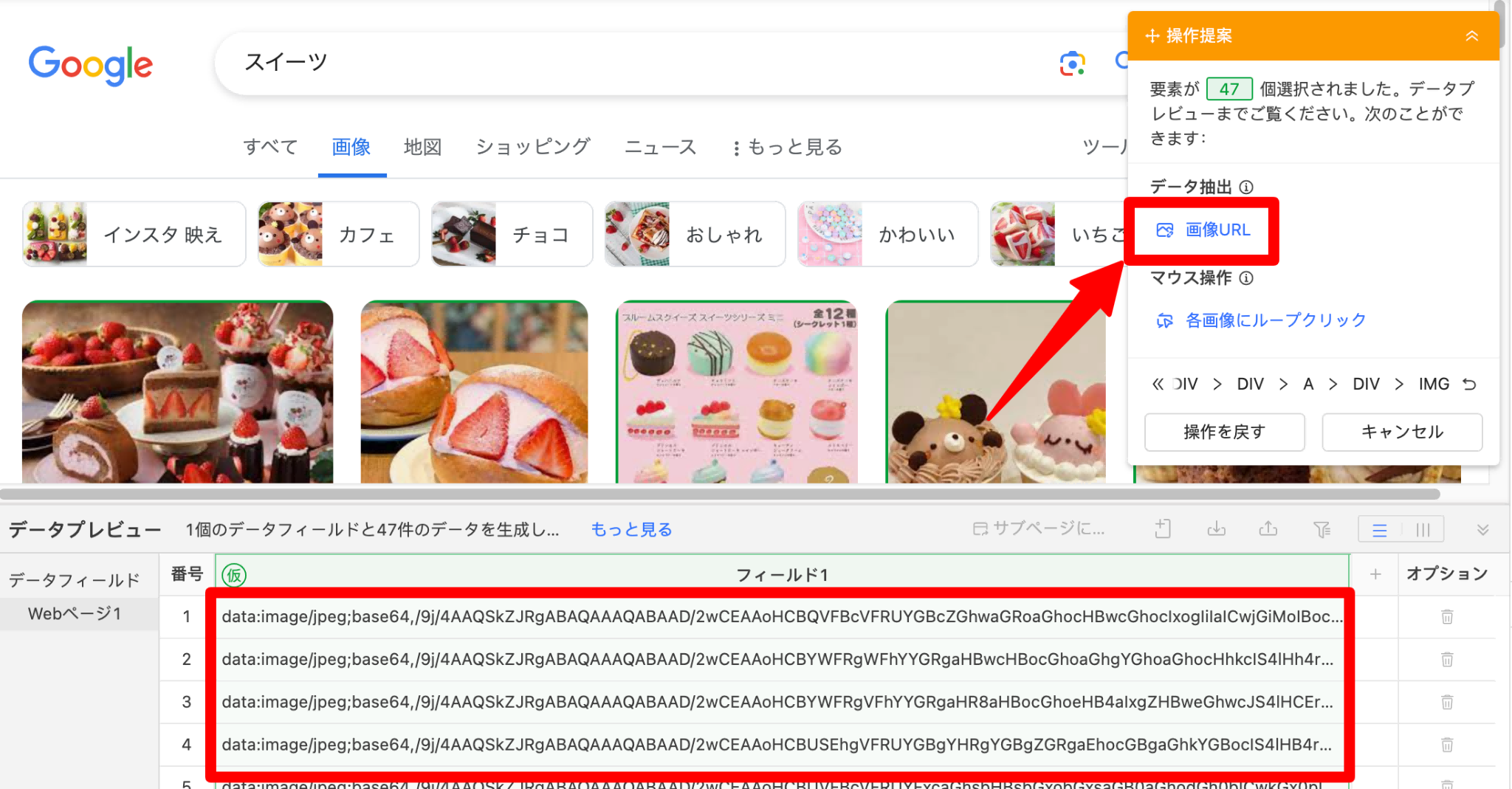
4.これでスクレイピングタスクが完成しました。実行をすれば、自動的に画像URLが取得できます。
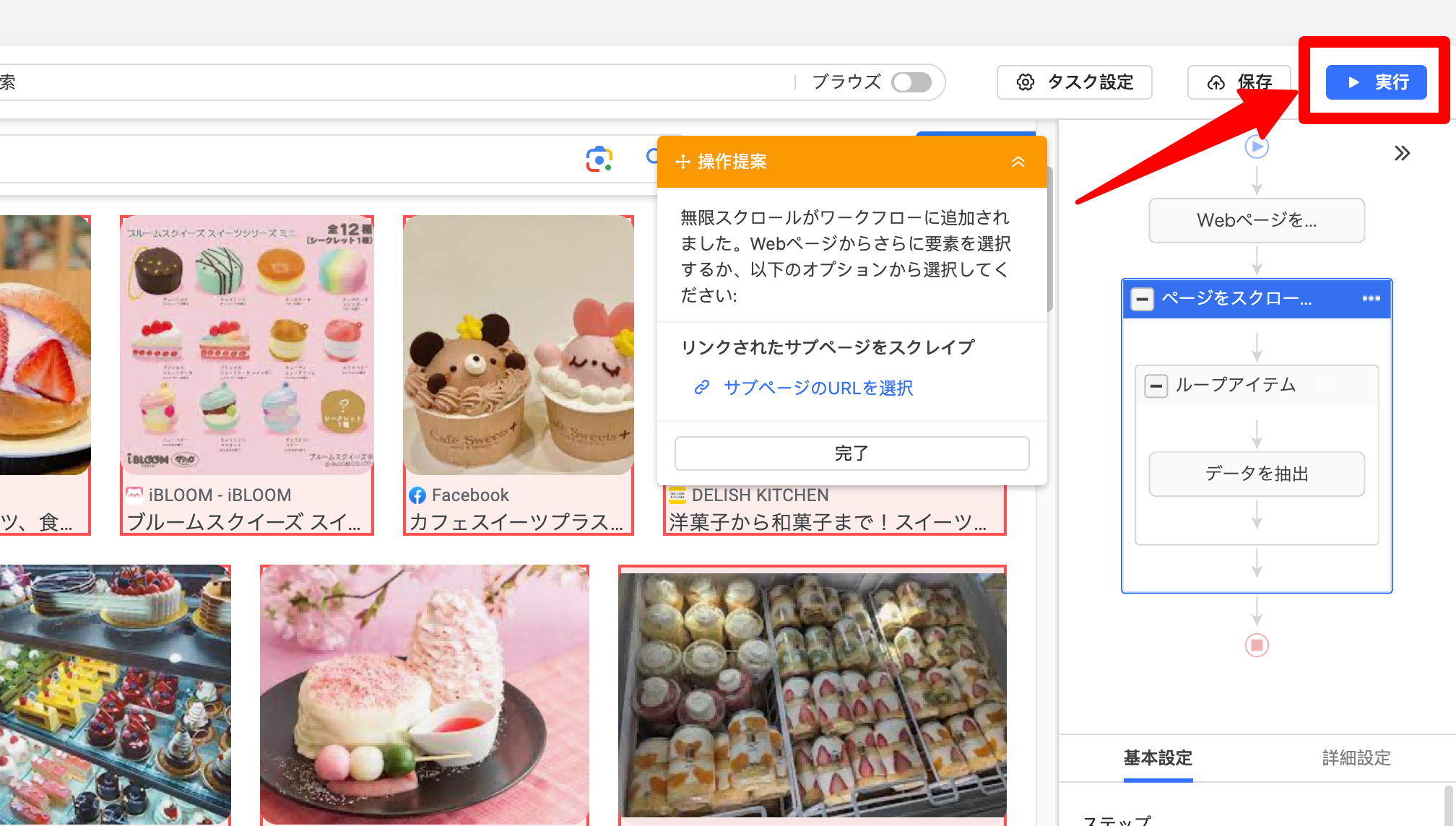
5.タスクを実行する
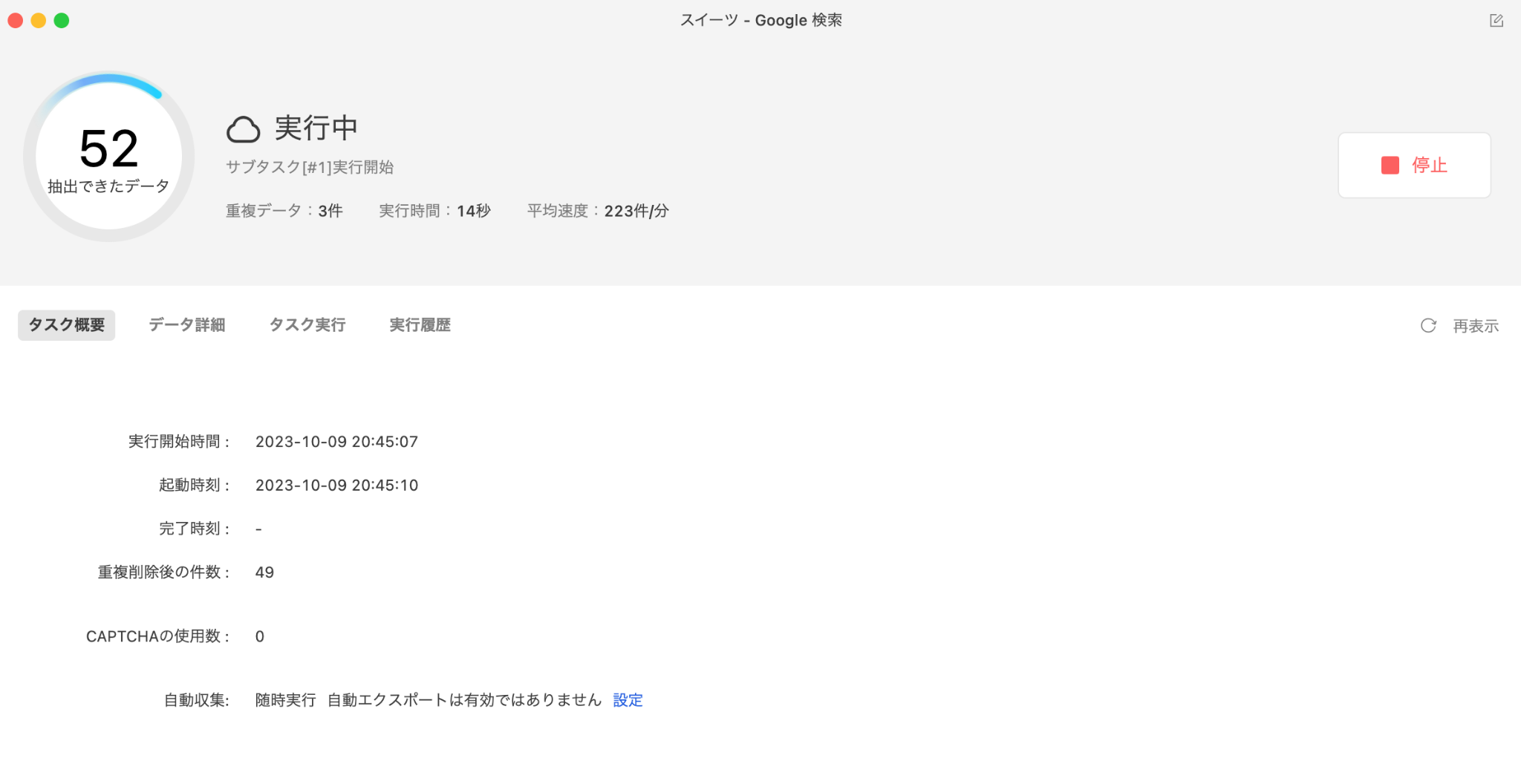
「実行」ボタンをクリックすると、スクレイピングタスクが開始されます。タスク実行中は以下のような画面が表示されますので、完了するまで暫く待ちましょう。たったこれだけの操作で、画像のデータを自動取得できるのは驚きですね!
6.画像のURLだけでなく、エクセルのimage関数 (この機能はMicrosoft 365とGoogle Spreadsheetでのみ利用可能) を使うか、Kutools for Excelをダウンロードしてインストールし、画像の実体を一括でダウンロードします。
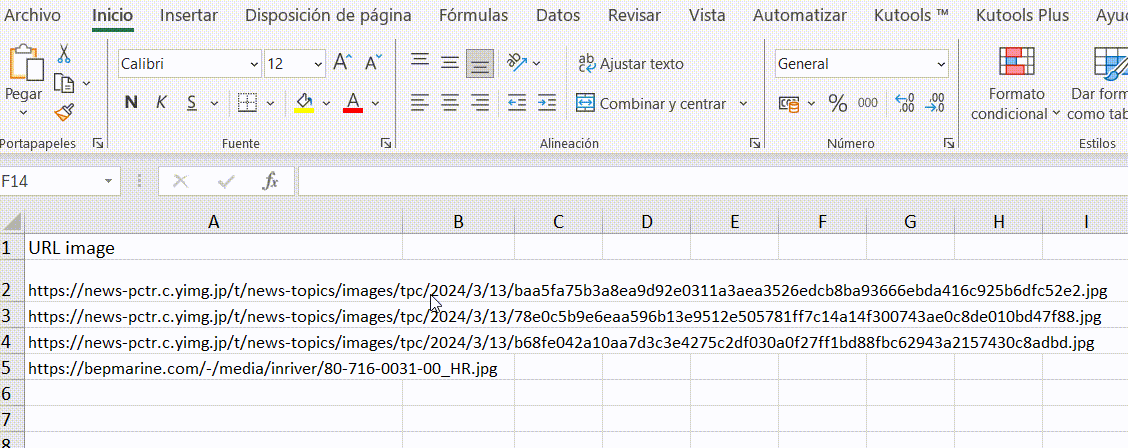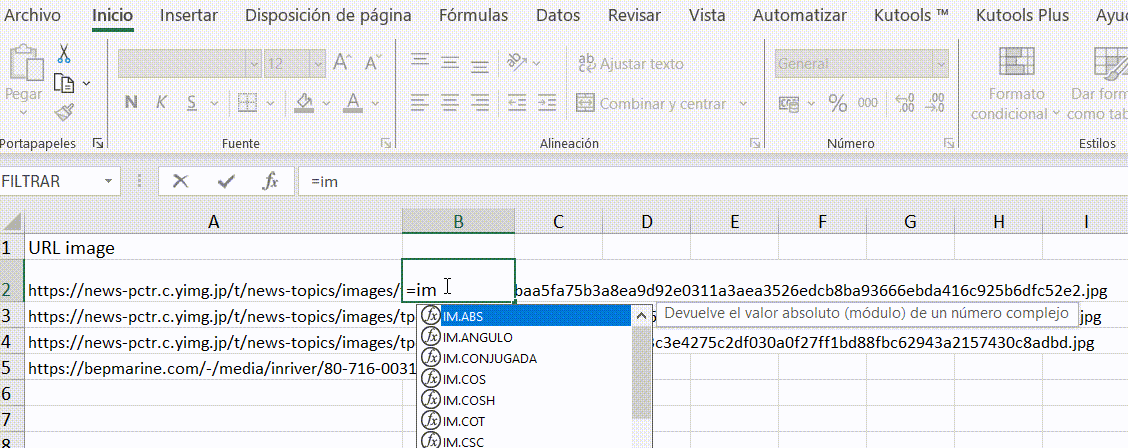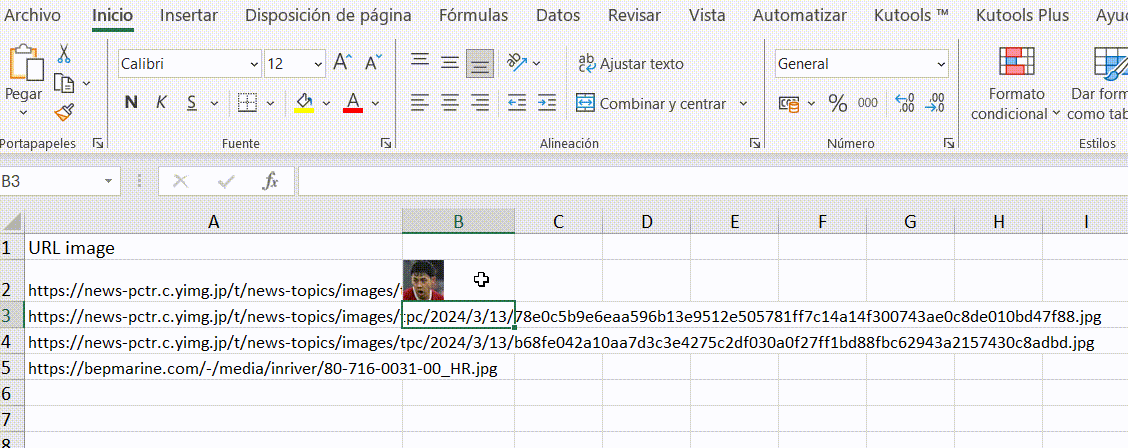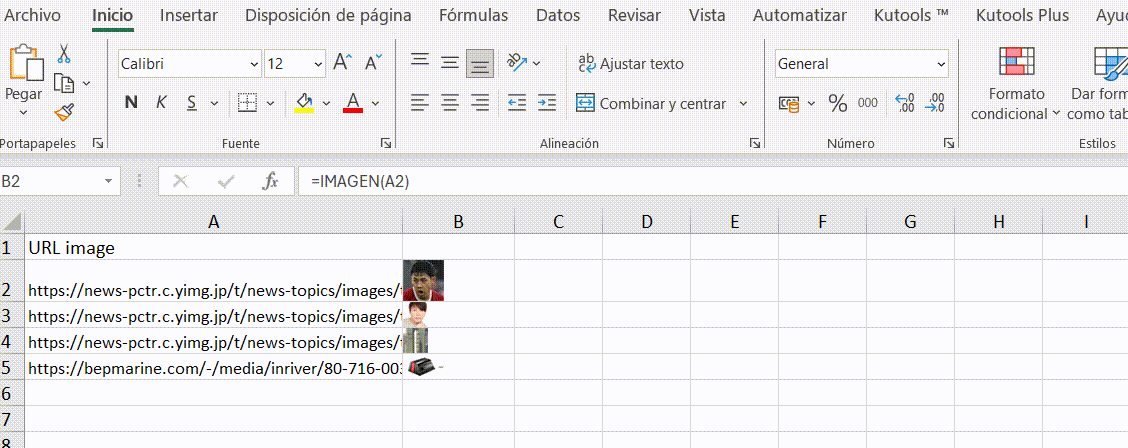
いかがでしょうか?一度Octoparseの操作に慣れてしまえば、これまでデータを取得するために無駄な時間を費やしていたことを後悔するに違いありません。
スクレイピングタスクに不具合が生じる場合の対処方法
ここまで紹介した例のように自動識別で生成したスクレイピングタスクは問題なく実行できますが、もしタスクに不具合が生じた場合は、どのように修正すればいいでしょうか。ここでは2つのケースを紹介します。
1. ページネーションが無効の場合
ページネーション(ページ送り)が無効の場合は、タスクからページネーションを確認し、必要に応じてXpathを修正します。ページネーションの詳しい説明はこちらの記事もご覧ください。
<修正方法>
ステップ「ページネーション」をクリックすると、ページネーションの設定画面が表示されます。その中に、自動識別で作成された「要素のXpath」があります。
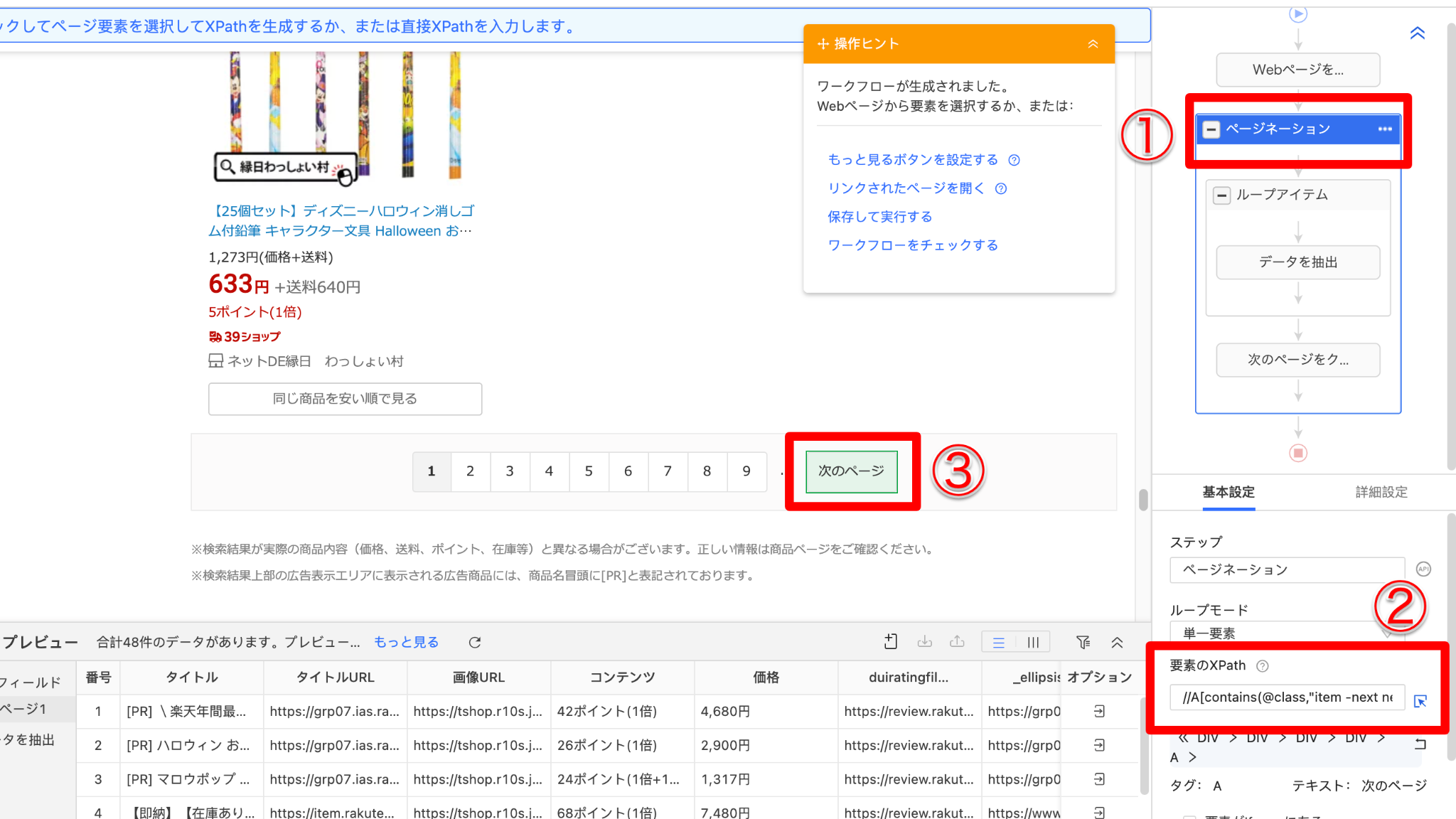
Xpathの右側にある小さな矢印(②)をクリックして、「次のページ」ボタン(③)をクリックします。この操作によってWebクローラーに「これが私がクリックしたいボタン」を指示しています。
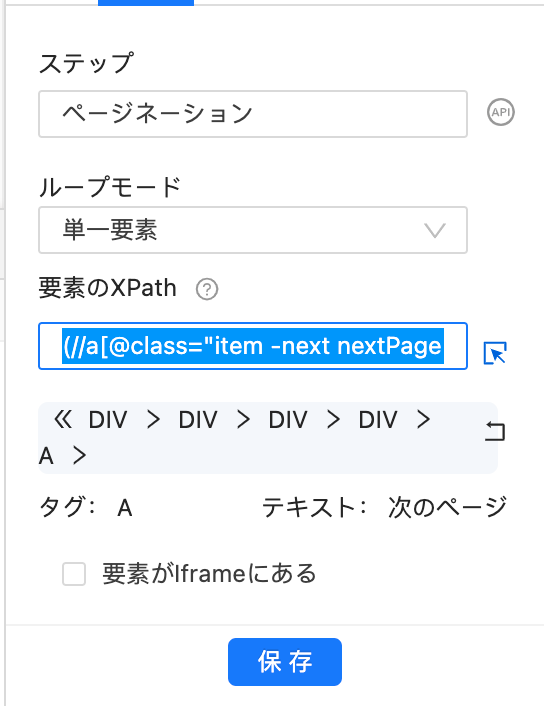
もし上記の方法を試しても不具合が解消しない場合は、下記のXpathを入力してください。
(//a[@class=”item -next nextPage”][contains(string(),”次のページ”)][not(@disabled)])[1]
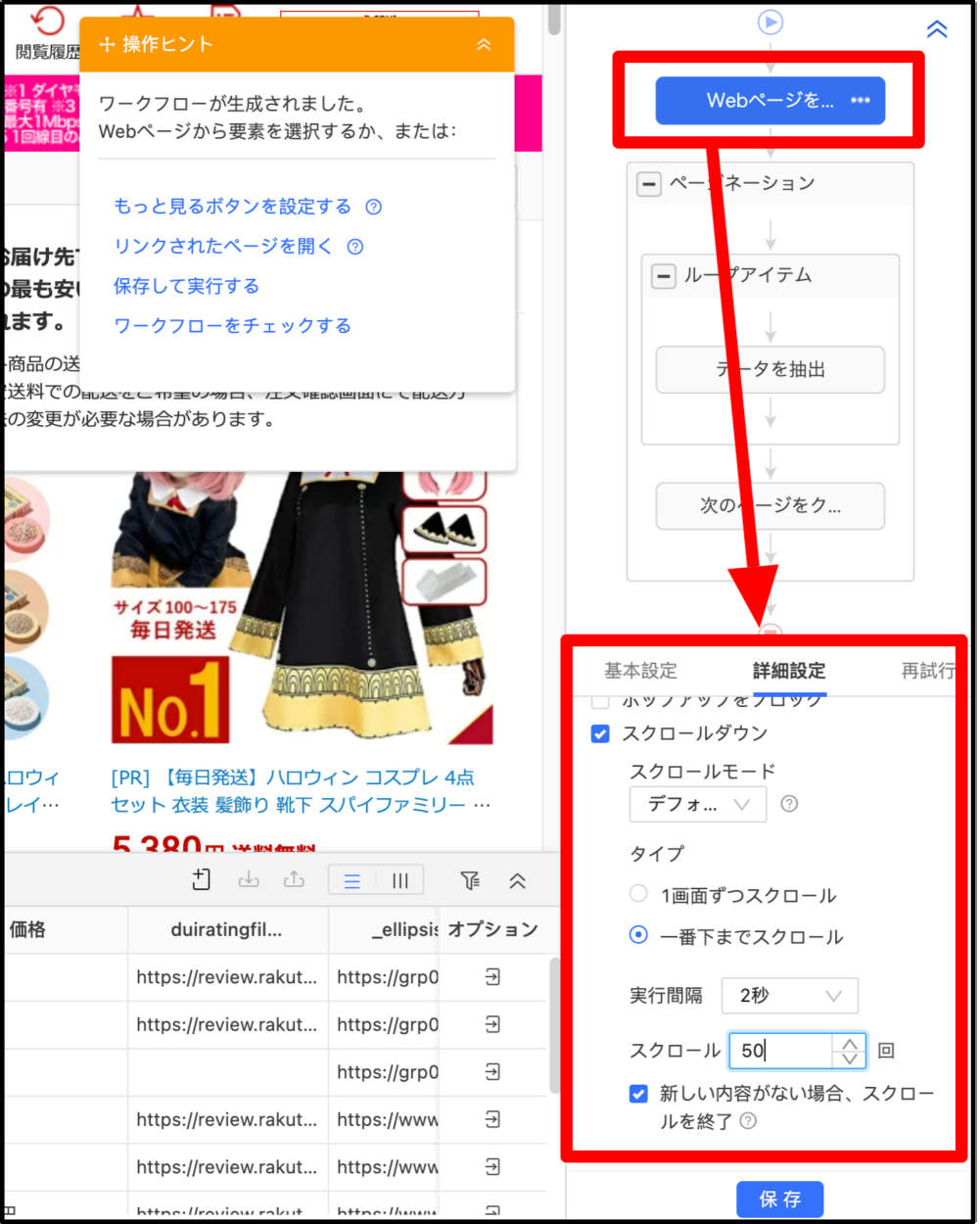
2. 画像が読み込まれない場合
ページ内が完全に読み込まれるための、スクロールダウン設定に不具合の可能性があります。Octoparseでは、数回のクリックだけでスクロールダウンを設定できます。
<修正方法>
ワークフローから「Webページを開く」をダブルクリックし、詳細設定を開きます。次に、「ほかのオプション」で「スクロールダウン」にチェックを入れます。2秒間隔でスクロール1回、回数50回を設定します。
まとめ
今回は、Google画像検索を例にWebページ内の画像URLを一括ダウンロードする方法を紹介しました。最後にポイントをまとめます。
1.Octoparseは、無料で使えるWebスクレイピングツールです。ノーコード技術を使うため、非エンジニアでもスクレイピングすることができます。Webスクレイピングプロジェクトをイチから始めるのに最適なツールです。
2.ウェブページからファイルをダウンロードする機能が充実しています。画像、音声、動画、ドキュメントを、わずか数秒でダウンロードが可能です。
画像以外にも様々な情報を収集することはもちろん、Octoparseの自動識別機能を利用すれば、Webサイトから簡単にデータを取得できます。さらにテンプレート機能を使えば、ワークフローやXpathの設定も不要です。本ブログでは、テンプレート機能の使い方も紹介していますので、ぜひ参考にしてください。




