あらゆるビジネスでインターネットやオンラインデータを活用する機会が増えた現在、「Webクローラー(英語:Web Crawler)」や「Webクローリング(英語:Web Crawling)」という言葉を一度は耳にしたことがあるのではないでしょうか。しかし、これらが具体的にどのような技術なのか、十分に理解できていない方も多いと思います。
Webクローラーは、GoogleやYahoo!が検索結果を生成する際に使う根幹技術です。特にマーケティング・営業・データ分析に携わる方が仕組みを正しく理解すると、競合情報収集の自動化やリード獲得の効率化、そしてAI活用のためのデータ取得まで、ビジネスを前進させる武器になります。
本記事では、IT知識が少ない方でも理解できるように、Webクローラーの基礎知識からその利点、具体的な活用方法まで詳しく解説します。Webクローラーを効果的に活用して、ビジネスパフォーマンスを最大化しましょう。
Webクローラーとは?
Webクローラー(crawler)とは、インターネット上のWebページを自動的に巡回し、情報を収集・整理するプログラムを意味します。 クローリング(crawling)とは、そのクローラーがページからページへとリンクをたどりながら自動巡回する行為そのものを意味します。「クローラー」という名称は、リンクを這い回ること(crawl=這う)に由来します。
私たちがGoogleやBingなどで検索するとき、その検索結果は、クローラーが事前に収集・整理した情報から提供されています。クローラーによるクローリングは、現代のインターネット検索を支える縁の下の力持ちです。クローラーは「ボット(bot)」「スパイダー(spider)」「ロボット(robot)」と呼ばれることもあります。
クローリング・スクレイピング・インデックス — 3つの違い
この3つの用語は混同されやすいですが、それぞれ異なる役割を持っています。
| 用語 | 目的 | 主な使用例 |
| Webクローリング | クローラーがインターネット全体を広範囲に巡回し、URLリストを生成する | 検索エンジン(Google、Bingなど)がインデックスを構築する |
| Webスクレイピング | 特定のページから必要なデータを抽出する | 価格比較サイト、マーケットリサーチ、営業リスト作成など |
| インデックス登録 | 収集した情報を検索可能な形でデータベースに登録する | 検索結果への表示(クローリングされてもインデックス登録されるとは限らない) |
重要:「クローリングされた ≠ 検索結果に表示される」です。インデックス登録はクローリングの後に別プロセスとして行われ、低品質なページや重複コンテンツはインデックスされない場合があります。
Webクローラーの仕組み
クローラーの基本的な動作プロセスは以下の通りです。
- 初期URLからスタート:「シードURL」と呼ばれる既知のWebページからクローリングを開始
- ページの解析:クローラーがアクセスしたページから情報を抽出し、含まれるリンクを識別
- リンクの追跡:見つけたリンクを順次訪問し、新しいページを発見
- 情報の収集・保存:ページの内容を取得し、データベースに保存
- ルール遵守:クローラーは「robots.txt」ファイルを確認し、クローリング可否を判断
- 繰り返し実行:上記プロセスを定期的に繰り返し、情報の最新性を維持
クローラーはインターネットという巨大な図書館を自動的に巡回し、検索エンジンという総合カタログを作り続けている司書ロボットと言えます。
関連記事:Webクローラーを自分で構築する方法
Webクローラーの種類と機能
- 検索エンジン用クローラー(Googlebot、Bingbot など)
検索エンジンがインデックスを構築するために常時稼働しているクローラーです。2026年現在の日本では、Yahoo! JAPANもGoogleのシステムを採用しているため、Googlebotへの対応がSEO対策の実質的な標準です。他にもBingbot、DuckDuckBot、YandexBotなどがあります。
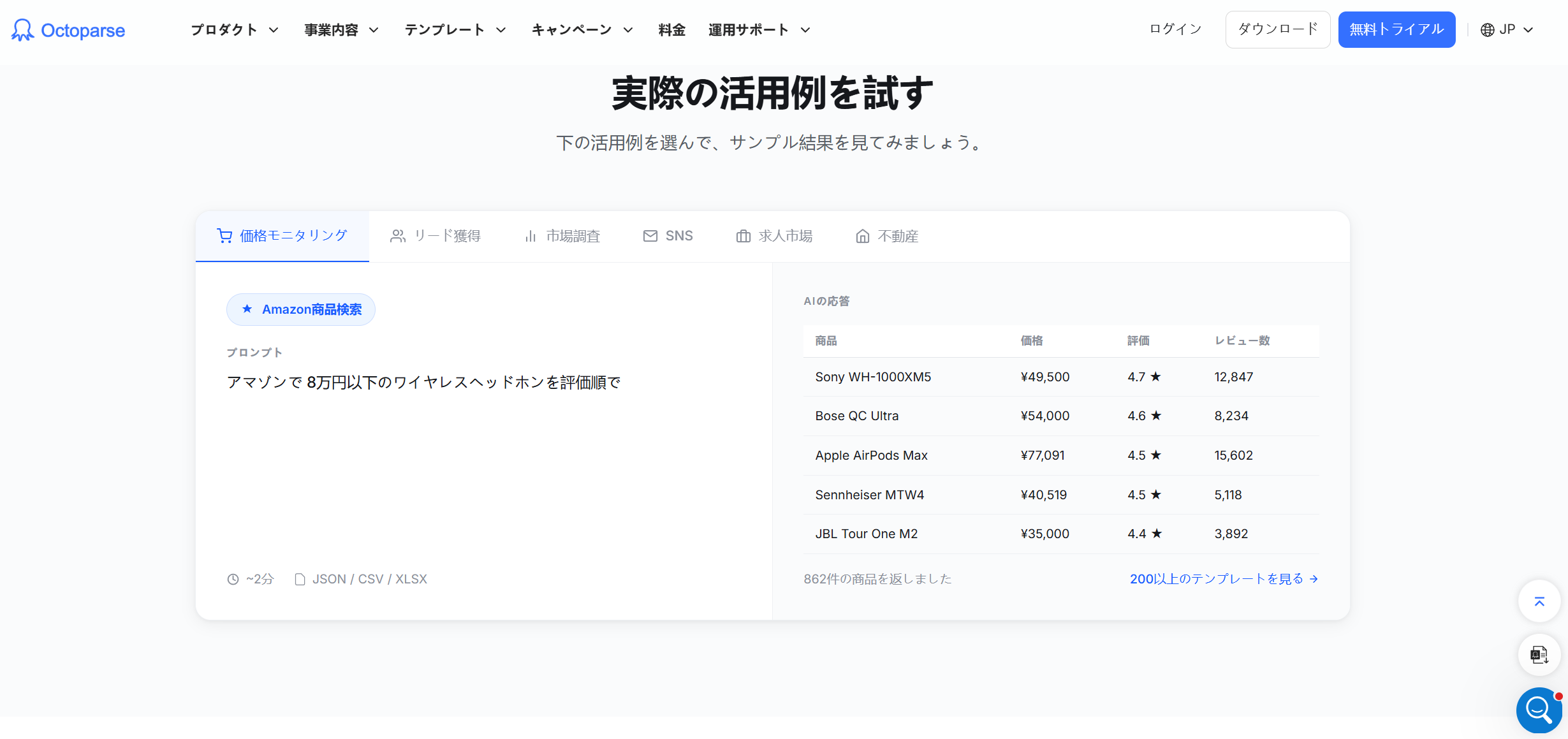
- ビジネス向けノーコードWebクローラーツール(Octoparseなど)
プログラミング知識不要でWebクローリングを自動化できるツールです。Octoparse(オクトパース/オクトパス)は世界600万人以上が利用し、数百種類のテンプレートを備えています。
たとえばAmazonの商品情報収集では【商品名・価格・評価・レビュー数・ASIN・在庫状況】、Googleマップでは【店舗名・住所・電話番号・評価・営業時間】といった各種データを、クリック操作だけで手軽に取得できます。
スケジュール設定による定期自動クローリングとクラウド抽出にも対応しており、PCの電源を切った状態でも収集を継続。これまで2時間かかっていたデータ収集作業がわずか2分で完了します。
- SEO診断・サイトクローラー(Google Search Consoleなど)
自分のWebサイトが検索エンジンにどのように認識されているかを確認・最適化するためのクローラーです。Google Search Consoleを使うと、クローラーがサイトのどのページを訪れているかを把握でき、SEO戦略の改善に活用できます。

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力。
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出。
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始。
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握。
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫。
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール。
Webクローラーを活用するメリット
検索エンジンの基盤:クローラーが事前に収集・整理した情報があるからこそ、検索クエリに対して関連性の高い結果を瞬時に提供できます。
情報の最新性と正確性:クローラーは定期的にクローリングを繰り返し、最新情報を収集してインデックスを更新し続けます。
ビジネスインテリジェンス:競合他社の価格収集・マーケットトレンド分析など、戦略的意思決定に大きく貢献します。
効率化と自動化:人間が手動で行うと数週間かかる1万件の情報収集も、クローリングなら数時間で完了。人件費とヒューマンエラーを同時に削減できます。
AI・機械学習との連携:2026年現在、Webクローリングは AI活用の最前線に位置しています。AI学習用データの収集をはじめ、生成AIと組み合わせた自動分析など、先端技術との連携がいま急速に広がっています。
OctoparseはMCP(Model Context Protocol)に対応しており、ChatGPTやClaudeなどのAIエージェントと連携して、収集データをそのままAIの分析・処理に渡すことができます。「クローリング→AI分析→レポート自動生成」の一気通貫ワークフローが、コードなしで実現可能です。
クローリングのデメリットと注意点
法的リスク(著作権・利用規約違反)
クローリング自体は違法ではありません。ただし、クローリングを禁止しているWebサイトのデータを収集した場合は利用規約違反となりえます。また、クローリングで収集したデータを複製して第三者に無断で譲渡・公開した場合は著作権法違反のリスクがあります。
関連記事:Webスクレイピングの法的な誤解を正す
サーバー負荷と岡崎市中央図書館事件
クローラーはWebサーバーへのアクセスを自動・連続的に繰り返すため、対象サーバーに負荷をかけます。2010年の「岡崎市中央図書館事件」では、クローラーによるサーバーへの過負荷が問題となり逮捕者が出た事例(後に不起訴)として知られています。クローラーのアクセス間隔は適切に設定しましょう。
robots.txtの遵守
robots.txtとは、Webサイトの運営者がクローラーに対してアクセス可能な範囲を示すファイルです。法的拘束力はないものの、robots.txtを無視したクローリングは不正アクセスとみなされるリスクがあります。クローリング実施前には必ず確認しましょう。
ウェブクローラーのマーケティング活用法
Octoparseのテンプレートを活用することで、マーケティング業務にWebクローリングをすぐ導入できます。各活用場面と取得できるデータ例を紹介します。
- 競合調査:価格やキャンペーン情報を自動収集
取得データ例:商品名 / 商品リンク / 価格 / 評価(星評価)/ レビュー数 / ASIN
https://www.octoparse.jp/template/amazon-japan-product-scraper
- リード獲得:企業リストや連絡先を効率取得
取得データ例:店舗名 / 住所 / 電話番号 / 評価 / 営業時間 / Webサイト(URL)
https://www.octoparse.jp/template/google-maps-scraper-store-details-by-keyword
- 市場リサーチ:トレンド・口コミ・レビューを分析
取得データ例:検索結果タイトル / URL / 詳細 / ソース
https://www.octoparse.jp/template/google-search-scraper
- SNSモニタリング:ブランド評価や顧客の声を収集
取得データ例:コメント本文 / ユーザー名 / いいね数 / リポスト数 / 返信数 / 投稿日時
https://www.octoparse.jp/template/tweets-comments-scraper-by-search-result-url
テンプレートだけでは足りない場合でも、カスタマイズタスクで必要な機能を実現できます。
Webクローラーがボット管理に与える影響
Webクローラー(良性ボット)は企業のデータ収集に有益ですが、同じWebには悪性ボット(スパムボット・不正スクレイピングボット)も存在します。サイト運営者として適切に管理することが求められます。
- 良性ボット:Webクローラー(検索エンジン用)、SEOツールボット
- 悪性ボット:スパムボット、不正スクレイピングボット
自社サイトをクローラーフレンドリーにするための3ステップ:
① robots.txtでクローリング許可範囲を明示する
② XMLサイトマップをGoogle Search Consoleに送信し、重要ページを優先巡回させる
③ サーバーレスポンスタイムを2秒以内に保ち、クロールバジェットを節約する
Webクローラーの管理
良性ボットであるWebクローラーの管理は、サイトのSEOとユーザーエクスペリエンスに直接影響します。Webクローラーが適切に機能するためには、以下のポイントを考慮する必要があります。
- robots.txtファイルの設置:クローラーの動作を制御するファイルをサイトのルートに設置
- クロール頻度の制御:クロールの頻度を制御することで、サーバーの負荷を軽減し、サイトのパフォーマンスを保つことができます。
悪性ボットによる被害を防ぐためには、ボット管理が必要です。これは、良性ボットと悪性ボットを識別し、悪性ボットをブロックするための措置を講じることを意味します。
- ボット管理ツール:使用することで、サイトにアクセスするボットを監視し、悪意のあるボットを特定してブロックすることができます。
- セキュリティ対策:CAPTCHAの導入やアクセス制限などのセキュリティ対策を講じることで、悪性ボットのアクセスを防ぐことができます。
よくある質問(FAQ)
Q1. クローリングとスクレイピングの違いは何ですか?
A. クローリングはWebページを広範囲に巡回してURLリストやインデックスを生成する技術です。スクレイピングは特定のページから価格・テキスト・画像などのデータを抽出する技術です。両者は目的と対象範囲が異なりますが、ツールによっては両機能を兼ね備えているものもあります。
Q2. クローリングは違法ですか?
A. クローリング自体は違法ではありません。ただし、対象サイトの利用規約でクローリングを禁止している場合や、収集したデータを無断で二次配布・複製する行為は法的リスクが生じます。robots.txtの指示に従い、サーバーへの過大な負荷を避けることが重要です。
Q3. プログラミングの知識がなくてもWebクローリングできますか?
A. はい、できます。OctoparseのようなノーコードWebクローラーツールを使えば、クリック操作だけでクローリングを自動化できます。数百種類のテンプレートが用意されており、ワンクリックで人気サイトのデータ取得を始められます。
Q4. Webクローリングを毎日自動で実行することはできますか?
A. はい、Octoparseのスケジュール機能を使えば、毎日・毎週・毎時間など任意のタイミングで自動クローリングを実行できます。クラウドで24時間365日稼働するため、夜間・休日も停止することなくデータを収集し続けます。
Q5. AIとWebクローラーを組み合わせると何ができますか?
A. OctoparseはMCP(Model Context Protocol)に対応しており、ChatGPTやClaudeなどのAIエージェントと連携できます。「クローリングで収集したデータをAIに渡して自動分析・レポート生成」という一気通貫ワークフローが実現でき、従来は人手が必要だった分析作業も自動化できます。
Q6. WebクローラーとAPIの違いは何ですか?
A. APIはデータ提供者が正式に公開している接続口で、許可を得てデータを取得します。WebクローラーはAPIが存在しないWebページからもデータを収集できる点が違いです。APIがある場合はAPIを優先的に使うべきですが、APIが存在しない・コストが高い・欲しいデータに対応していない場合にWebクローラーが有効な選択肢になります。
まとめ
本記事では、クローラーとクローリングの基本的な意味から仕組み、メリット・デメリット、そして具体的な活用方法まで幅広く解説しました。
クローラーは、検索エンジンがインターネット上の情報を収集し、最適な検索結果を提供するための重要な技術です。SEO対策として自サイトのクローリングを促進することはもちろん、クローリングとスクレイピング・インデックスの違いを正しく理解し、場面に応じて使い分けることが重要です。また、著作権・利用規約・サーバー負荷といった法的・倫理的な注意点も、クローリングを活用する上で欠かせない知識です。
将来的には、AIや機械学習との連携によってクローリングはさらに高度化・自動化が進むと予想されます。Octoparseのようなノーコードツールを活用すれば、専門知識がなくてもクローリングをビジネスに取り入れることができます。Webクローラーを効果的に活用することで、データ主導の意思決定が可能になり、デジタルマーケティングの成果向上とビジネスの成長につながるでしょう。
競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力。
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出。
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始。
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握。
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫。
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール。



