Redditとは、世界中のユーザーがあらゆるトピックについて議論できる、アメリカ発の大型掲示板型SNSです。月間アクティブユーザーは世界で数億人に上り、日本でも近年急速に認知が広がっています。
ビジネス・エンタメ・テクノロジーから日常の雑談まで、あらゆるジャンルの「サブレディット(スレッド掲示板)」が存在するため、マーケターやリサーチャーにとってもデータの宝庫といえます。
したがって、社会調査、インターネットマーケティング、またはその他の関連分野に携わっている場合、Redditのスクレイピングは、調査、分析、参照、その他の目的のためのデータを得るための優れた情報源となり得ます。
このブログで学べる内容
この記事では、この記事では、Redditの投稿、コメント、画像、ユーザーデータなどの公開情報を、コーディング不要で効率的にスクレイピングする方法を解説します。
IPブロックやCAPTCHAなどの一般的な落とし穴を回避しつつ、IPローテーションなどのスマートな技術を活用する手順も紹介します。
Redditとは何か?基本的な特徴と他SNSとの違い
Redditは2005年にアメリカで誕生した掲示板型ソーシャルメディアです。
「r/」で始まる無数のサブレディット(テーマ別掲示板)にユーザーが投稿し、他のユーザーが「アップボート(良い)」「ダウンボート(良くない)」で評価する仕組みが特徴です。
評価の高い投稿ほど上位に表示されるため、自然と質の高い議論が集まりやすい構造になっています。
日本では「アメリカ版2ちゃんねる」と例えられることもありますが、匿名性を保ちながらも深い議論が行われる点が他のSNSとは大きく異なります。
InstagramやX(旧Twitter)が拡散・バズを重視するのに対し、Redditは深掘りされた専門的な議論とコミュニティ形成を重視しています。
Reddit はスクレイピングを許可していますか?
Redditは公開されている投稿・コメントデータへのアクセスを基本的に許可しています。
ただし公式APIを通じたアクセスには以下の制限があります:ユーザー認証が必須、商用利用には別途許可が必要な場合がある、1回のリクエストで取得できるデータ量に上限がある。
こうした制限を考慮しながら、より効率的にデータを収集したい場合は、Octoparseのようなノーコードスクレイピングツールが有効です。
Redditスクレイピングで収集可能なデータ
Redditからスクレイピング可能なデータは多岐にわたります。具体的な例を以下に示します:
- 投稿タイトルと本文
- コメントと返信
- アップボート数とダウンボート数
- 投稿の作成日時
- 画像、動画、その他のメディアファイル
- サブレディットとトピック
- ユーザー名、プロフィール、カルマスコアなど
Redditのデータ活用で得られる利点
なぜRedditデータをスクレイピングしExcelファイルにエクスポートする必要があるのか疑問に思うかもしれません。以下に、Redditからデータをスクレイピングする理由、つまり利点をいくつか挙げます。
1. 市場調査・競合分析
特定のサブレディットから投稿やコメントをスクレイピングすることで、ターゲット層の本音やニーズ、競合製品に対する評価を把握できます。
2. コンテンツ作成
Redditはコンテンツ制作におけるアイデアやインスピレーションの豊富な情報源です。関連データをスクレイピングすることで、人気トピックやトレンド、議論を特定し、魅力的で関連性の高いコンテンツ作成に活用できます。
3. 感情分析
Redditは、人々が様々なトピックについて意見や感情を表現するプラットフォームです。関連するサブレディットからデータをスクレイピングすることで、感情分析を行い、自社ブランドや製品、サービスに対する人々の感情を理解できます。
コーディング不要で使える Redditスクレイピングツール
Reddit公式APIには認証・データ量・利用目的の制限があり、特にビジネス用途では思うようにデータが取得できないケースが多くあります。そこで、コーディング不要でRedditデータを自由にスクレイピングできるツールとして、Octoparseをご紹介します。
Octoparseは、WindowsとMacの両システムに対応したツールであり、Redditなどのウェブサイトからデータを自動的に抽出します。
データスクレイピングのプロセスはシンプルで、グループ名、タイトル、記事、投稿者などのデータを素早く取得できます。クラウド抽出にも対応しているため、IP制限を回避できます。
特定の時間を設定できるスケジュール型ウェブスクレイピングのオプションもあります。その後、RedditデータをExcelファイルにダウンロードしたり、データベースにエクスポートしたりできます。

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール
Octoparseを使ったRedditスクレイピング手順
本記事の手順は、以下の環境で実際に検証しています。
・使用ツール:Octoparse 8.9.0
・使用テンプレート:投稿&コメント用Redditスクレイパー
https://www.octoparse.jp/template/reddit-scraper
・対象サイト:Reddit(https://www.reddit.com/)
・取得対象データ:投稿タイトル、コメント、投稿者、アップボート数など
・作業時間の目安:約20分
ステップ1:Octoparseを起動してRedditのURLを入力する
- OctoparseをインストールしてPC上で起動します(所要:約2分)。
- スクレイピングしたいRedditページ(サブレディット、スレッド、ユーザーページなど)のURLをメイン画面に貼り付けます。(2分完了)
- Octoparseは自動的にページ構造を解析し、抽出可能なデータフィールドを検出します。(2分完了)
- ウェブスクレイピングプロセスをより細かく制御したい場合は、詳細モードに切り替えます。
ステップ2:ワークフローを作成しデータフィールドをカスタマイズ
- OctoparseはReddit投稿タイトル、コメント、投稿者、タイムスタンプ、投票数、メディアリンクなどの要素をマッピングするワークフローを構築します。(5分完了)
- ページ内の全投稿を読み込むにはスクロールダウン設定を調整します。(2分完了)
- 抽出が必要なデータフィールドのみを選択/非選択し、抽出対象を正確に指定します。(2分完了)
ステップ3: Redditからデータを抽出
- 「実行」ボタンをクリックしてスクレイピングを開始します。
- 投稿内容、コメントスレッド、ユーザー情報、エンゲージメント指標を含むデータがリアルタイムで収集されます。(収集するデータ量に応じて、所要時間は変動します。)
- 完了後、抽出されたRedditデータをExcel、CSV、またはJSON形式でエクスポートし、即時分析が可能です。(1分完了)
Redditデータスクレイピング用プリセットテンプレート
独自のワークフロー作成が面倒だと感じた場合、OctoparseではRedditやその他人気サイトからのデータスクレイピング用プリセットテンプレートも提供しています。
Redditから投稿画像、タイトル、投稿者などのデータを簡単に抽出できます。これらのプリセットデータスクレイピングテンプレートはOctoparseのテンプレートパネルから入手可能、または下記のオンラインRedditスクレイパーをお試しください。
https://www.octoparse.jp/template/reddit-scraper
https://www.octoparse.jp/template/reddit-post-scraper-by-keywords
テンプレートを使えば、やることはキーワードを入力するだけ。
上記のように20分もかかりません。まずは無料トライアルで、必要なReddit情報をすぐに取得してみてください。
競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール
PythonでRedditのフォロワーをスクレイピングする
コーディングに習熟しているなら、Redditからデータをスクレイピングする別の方法として、高度なプログラミング言語であるPythonを使用してスクレイパーを開発する方法があります。スクレイパーやウェブクローラーの作成を支援するサードパーティ製ライブラリやフレームワークも利用できます。
PythonでRedditデータをスクレイピングするには、PRAW(Python Reddit API Wrapper)モジュールが使用されます。これはPythonスクリプトでRedditのAPIを利用することを容易にします。
PythonでRedditをスクレイピングする4つのステップ(所要時間:65分)
ステップ1. まず、PRAWをインストールする必要があります。コマンドプロンプトでコマンドライン「pip install praw」を実行してください。(所要時間:5分)
ステップ2. 次に、データ抽出のためにRedditアプリを作成します。開発者としてアプリを作成するオプションを選択してください。(所要時間:10分)
ステップ3. アプリ作成後、2種類のPrawnインスタンスを作成する必要があります。読み取り専用インスタンスと認証済みインスタンスです。(所要時間:20分)
ステップ4. 抽出するデータの種類に応じてコマンドを実行します。コマンド処理中にデータ抽出が行われます。(所要時間:30分)
詳細はこちらのページをご参照ください:https://www.geeksforgeeks.org/scraping-reddit-using-python/
2026年版:Redditスクレイピングを成功させるためのコツ
1. Redditの利用規約とAPIガイドラインを常に確認し、スクレイピングが準拠していることを保証してください。
2. Octoparseのように、プロキシローテーションとCAPTCHA処理を内蔵した信頼性が高くスケーラブルなツールを使用してください。
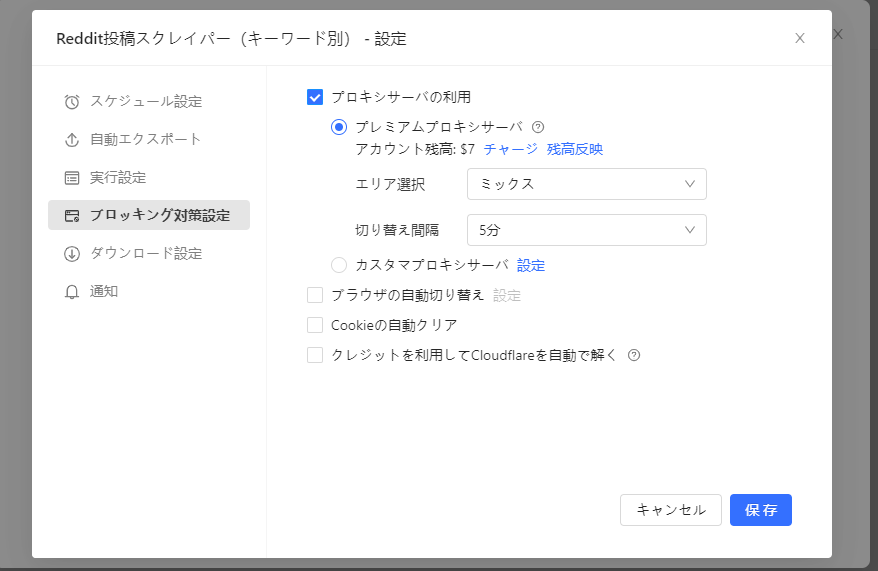
3. スクレイピングの実行間隔やリクエストパターンを設定し、短時間に集中するアクセスを防ぎましょう。
4. 抽出したRedditデータは、ExcelやCSVなど構造化された形式で保存することで、その後の分析やレポート作成がスムーズになります。
FAQ(よくある質問)
Q1. RedditはAPIなしでもスクレイピングできますか?
はい、可能です。Redditの多くの投稿やコメントは公開データのため、Webスクレイピングツールを使って取得できます。ただし、データ収集を行う際はRedditの利用規約やアクセス制限を確認し、適切な方法で実施することが重要です。
Q2. Redditからどのようなデータを取得できますか?
Redditでは、投稿タイトルや本文、コメント、アップボート数、投稿日時、画像・動画リンク、サブレディット名、ユーザー名などの公開情報を取得できます。これらのデータは市場調査、トレンド分析、ユーザーの意見分析などに活用できます。
Q3. Redditのデータは商用利用できますか?
公開データへのアクセス自体は可能ですが、利用方法はRedditの利用規約やAPIポリシーに従う必要があります。特に大規模なデータ取得や商用目的で利用する場合は、最新のガイドラインを確認したうえで適切に利用することが推奨されます。
Q4. Redditスクレイピングにおすすめの方法は何ですか?
手軽にデータを収集したい場合は、OctoparseのようなノーコードWebスクレイピングツールの利用がおすすめです。URLを入力して抽出するデータ項目を設定するだけで、Redditの投稿やコメントデータを自動的に収集し、ExcelやCSV形式でエクスポートできます。
まとめ
Redditとは、マーケティング調査や感情分析、コンテンツ企画において非常に価値あるデータの宝庫です。本記事で紹介したOctoparseを使えば、コーディングなしで投稿・コメント・ユーザー情報を素早く・安全に収集できます。
Redditのデータ収集を始める際は、利用規約を遵守しつつ、目的に合ったツール選択と適切なデータ保存形式の設定を忘れずに行いましょう。
まずは無料トライアルでその使いやすさを実感してみてください。
競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール