競合サイトのページ構成を丸ごと把握したい、自社サイトのリンク切れをすべて洗い出したい——そんな場面で威力を発揮するのがサイトURL抽出(ページ一覧取得)ツールです。URLを一括で収集できれば、内部リンク最適化・競合分析・サイトマップ作成といった作業が一気に効率化されます。
本記事では、WebページからURLを一括取得できるURL抽出ツールを5つ厳選して比較します。ツールの選び方・具体的な活用法・Pythonによる実装方法まで、SEOやマーケティング担当者が現場で使える情報をまとめました。コードは書きたくないという方向けのノーコード手順も解説しています。
WebページからURL抽出した後の活用方法
URLを抽出するだけで終わらせてはもったいない——取得したデータの使い方次第で、SEOやマーケティングの成果は大きく変わります。実務でよく使われる4つの活用パターンを解説します。
内部リンクの最適化
Webページから取得したURLデータは、内部リンク構造の見直しに活用できます。内部リンクはユーザーの回遊性を高めると同時に、検索エンジンにページの重要度を伝えるシグナルとしても機能します。まずWebサイト内の全URLを一括取得してリスト化し、孤立しているページや過剰にリンクが集中しているページを可視化することが改善の第一歩です。
競合サイト分析
競合サイトのURL構造を抽出・分類することで、コンテンツ戦略の全体像が見えてきます。カテゴリー別のページ数・更新頻度・内部リンクの集中具合などから、競合が注力している領域を特定できます。大量のリンクが集まっているページはトラフィックの稼ぎ頭である可能性が高く、自社の優先コンテンツ施策の参考になります。
コンテンツ管理と更新
自社WebサイトのURLリストを定期的に取得しておくと、リンク切れ・古いコンテンツ・URLの命名ルール違反などを一括チェックできます。サイトマップの作成・更新にも役立ち、検索エンジンへのインデックス促進につながります。特に大規模サイトでは手動確認が現実的でないため、URL一括取得ツールによる自動化が不可欠です。
外部リンクのチェックと精査
外部リンクの一覧を取得して定期的に検証することで、リンク先の閉鎖・低品質サイトへの誘導・不自然なリンクパターンなどを早期発見できます。Googleはリンクの質を評価基準の一つとしているため、不適切な外部リンクを放置すると検索順位に影響することがあります。定期的なURL抽出でリンクの健全性を維持する習慣を持ちましょう。
URL取得ツールの選び方
ひと口にURL抽出ツールといっても、Chrome拡張のような軽量ツールからクラウドスクレイパーまで幅広い選択肢があります。目的・規模・技術レベルに合わせて選ぶために、押さえておくべき5つのポイントを解説します。
一括URL取得機能(クロール対応)
サイト全体のページ一覧取得を目的とする場合、ページをまたいでリンクを辿るクロール機能が必要です。単ページのみ抽出できる拡張機能とは根本的に異なり、数百〜数千ページ規模のサイトにも対応できるツールを選ぶことが重要です。
データ出力形式
取得したURLをどのように活用するかによって、最適な出力形式が変わります。スプレッドシートで整理するならCSV・Excel、他システムと連携するならJSONやAPI出力に対応したツールが適しています。用途に合わせて柔軟に出力形式を選べるか確認しておきましょう。
処理速度と安定性
数百ページ以上のサイトを対象にする場合、処理速度と長時間稼働の安定性が業務効率に直結します。エラーで中断するツールや処理が著しく遅いツールは大規模案件には向きません。クラウド実行に対応したツールであれば、PCをオフにしても処理が継続されるため、大規模サイトの一括取得に特に有効です。
カスタマイズ性
特定のURLパターンのみ抽出したい、特定のディレクトリ配下に絞りたい——こうしたニーズに応えるには、フィルター・正規表現・クロール深度の設定など細かな制御が可能なツールが必要です。用途が複雑になるほど、カスタマイズ性の高さが差別化ポイントになります。
価格と費用対効果
無料ツールでも基本的なURL抽出は可能ですが、大規模・継続的な運用には有料プランの機能が必要になる場合がほとんどです。まずは無料プランで試してから、業務規模に合わせてアップグレードできるツールを選ぶと初期リスクを抑えられます。
ツール比較一覧(早見表)
紹介する5ツールを主要な観点で比較しました。用途に合ったツール選びの参考にしてください。
| ツール名 | タイプ | 無料プラン | クロール対応 | 出力形式 | おすすめ対象 |
|---|---|---|---|---|---|
| Octoparse | デスクトップ/クラウド | ✅ あり | ✅ 対応 | CSV / Excel / API | 初心者〜上級者・業務利用 |
| URL Profiler | デスクトップ | ✅ 試用あり | ✅ 対応 | CSV / Excel | SEOプロ・大規模分析 |
| Link Extractor | Chrome拡張 | ✅ 無料 | ❌ 単ページのみ | テキスト | 初心者・単ページ確認 |
| LinkGopher | Chrome拡張 | ✅ 無料 | ❌ 単ページのみ | テキスト | 初心者・内外リンク整理 |
| URLクリッパー | Chrome拡張 | ✅ 無料 | ❌ 単ページのみ | テキスト | 初心者・簡易コピー |
おすすめURL抽出ツール5選
① Octoparse ── ノーコードで本格的なWebサイトURL抽出ができる
Octoparseは、プログラミング不要でWebデータを収集できるノーコード型スクレイピングツールです。URL抽出において他のツールと最も差別化される点は、サイト全体を自動クロールしてページ一覧を一括取得できること。Chrome拡張とは異なり、数百〜数千ページ規模のサイトにも対応しています。
また、URLの収集だけでなく、ページ内の画像や商品情報、口コミデータなどさまざまなデータの抽出にも対応しており、画像を一括で保存したい場合は、「ページ内の画像を一括保存する方法」もあわせて参考にしてください。
Octoparseで取得できるURLデータの例:
- ページURL(絶対パス / 相対パス)
- アンカーテキスト(リンクの表示テキスト)
- リンクタイプ(内部リンク / 外部リンク)
- リンク元ページURL
- ページタイトル・メタ情報(設定により取得可能)
主な特徴:
- クラウド実行対応:PCをオフにしても処理が継続。大規模サイトの一括URLクロールも安定して実行できます
- 豊富な出力形式:CSV・Excel・JSON・APIに対応。他ツールやBIシステムとの連携もスムーズ
- テンプレート機能:設定不要で使えるスクレイピングテンプレートが600種類以上。URL抽出用のテンプレートもあり、初めての方でもすぐに使い始められます
- 無料プランあり:月10,000件まで無料で収集できるため、小規模サイトの検証にも最適
大量のURLをクロールする際、一部のサイトではボット検知によるアクセス制限が発生することがあります。その場合の対策については、スクレイピングのブロック回避方法の解説記事も参考にしてください。
💡 Octoparseをさらに使いこなしたい方へ:
OctoparseはMCP(Model Context Protocol)に対応しており、ChatGPTやClaudeなどのAIアシスタントから直接Web上のURL・データを取得することも可能です。「競合サイトのページ一覧をAIに分析させたい」「URL抽出を自分のワークフローに自動組み込みしたい」という方は、Octoparse MCP Serverもあわせてご確認ください(設定ガイドはこちら)。
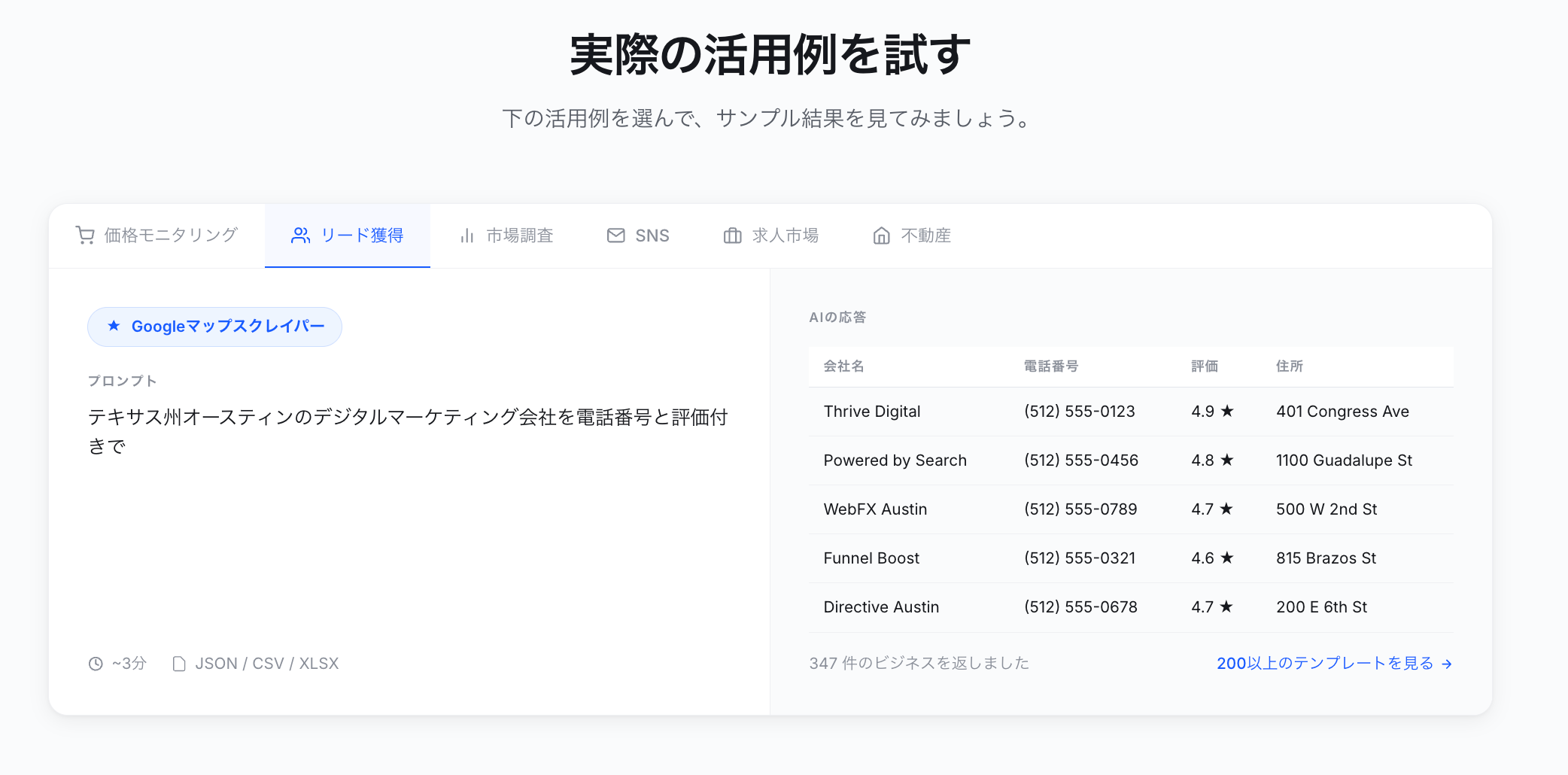

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール
② URL Profiler ── SEO専門家向けの高機能URL分析ツール
URL Profilerは、SEOやコンテンツマーケティングに特化したデスクトップ型のURL分析ツールです。URLの抽出だけでなく、取得したリストに対してSEOメトリクス・コンテンツ情報・SNSシグナルを一括で付与できるのが最大の強みです。
- Majestic・Moz・Ahrefsなど外部SEOツールとのAPI連携が可能
- リンクデータに加え、コンテンツ品質・HTTPステータス・ページ速度なども同時取得
- 大量URLの高速一括処理に強く、数万件のURLも短時間で分析可能
③ Link Extractor ── 単ページ確認に便利なChrome拡張
Link Extractorは、Google ChromeブラウザにインストールするだけでURLを即座に抽出できる軽量拡張機能です。閲覧中のページ上のすべてのリンクをワンクリックで一覧化できます。
- インストール後すぐに使えるシンプル設計。技術知識不要
- 現在開いているページ内の全リンクを瞬時に抽出・表示
- 完全無料。個別ページの簡易確認に最適
⚠️ サイト全体のページ一覧取得やマルチページのURL一括収集には対応していません。
④ LinkGopher ── 内部・外部リンクを分類して表示するChrome拡張
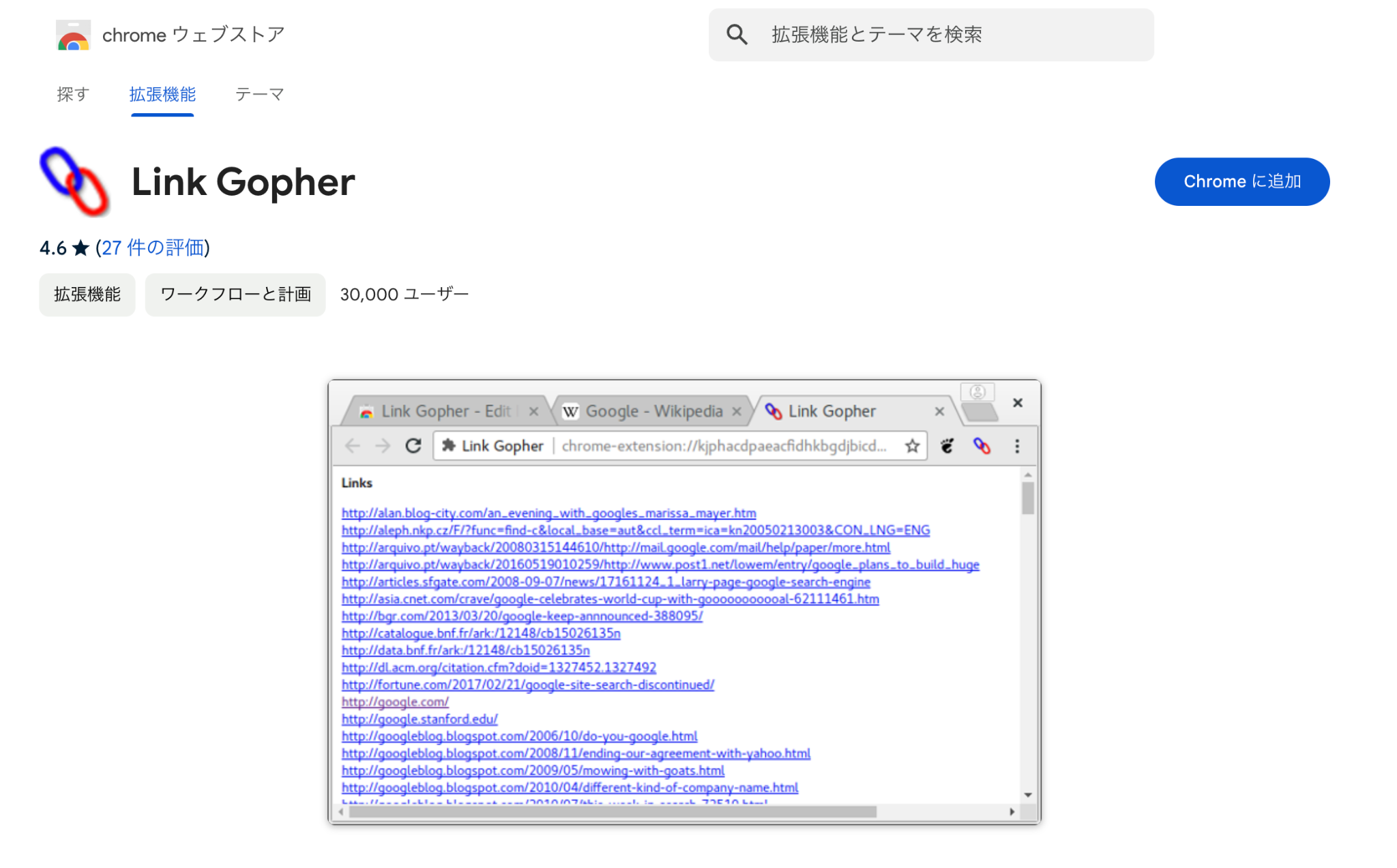
LinkGopherは、ページ内のリンクを内部リンクと外部リンクに自動分類して表示してくれるChrome拡張機能です。内部リンク構造の確認や外部リンクの棚卸しをさっと行いたいときに便利です。
- 内部リンク・外部リンクを自動で分類して一覧表示
- テキスト形式でのエクスポートに対応。スプレッドシートへの貼り付けが簡単
- 軽量・無料。ブラウザに追加するだけで即使える
⑤ URLクリッパー ── ワンクリックでURLをまとめてコピー
URLクリッパーは、ページ内のURLをワンクリックで一括コピーできるシンプルなChrome拡張機能です。重複URLを自動除外する機能を持ち、すっきりしたリストをすぐに取得できます。
- ワンクリックでページ内全URLを一括コピー。作業が数秒で完了
- 重複URLを自動除外し、クリーンなリストを出力
- 完全無料。インストールのみで即使用可能
関連記事
無料で簡単!Firefoxで画像を一括ダウンロードする方法を解説
Pythonでサイトのリンク一覧を取得する方法【URL取得コード例付き】
ツールを使わずに実装したい場合は、PythonのBeautifulSoupとRequestsライブラリを使うことで、特定サイトからのリンク一覧取得をカスタマイズできます。PythonでHTMLからURLを抽出する詳細な手順はこちらの記事で解説していますが、基本的なコードは以下の通りです。
コードのポイント:
requestsライブラリで指定URLにHTTPリクエストを送り、HTMLデータを取得BeautifulSoupでHTMLを解析し、構造化されたオブジェクトとして操作可能にするsoup.find_all('a')で全<a>タグを取得し、href属性のURLを出力
このコードは単一ページのみを対象としています。サイト全体のページ一覧取得(再帰的クロール)を実装するには、訪問済みURLの管理・相対パスの正規化・ページネーション対応などが追加で必要です。スクレイピングに使えるPythonライブラリの比較も参考にしてください。
「コードは書かずにサイト全体のURLを収集したい」という方には、前述のOctoparseがノーコードで同等の処理を実現できます。ノーコードでWebデータを収集する方法の入門ガイドもあわせてご参照ください。
よくある質問(FAQ)
Q1. Webサイト内のすべてのページURLを一覧取得するにはどうすればいい?
単ページのみ対応したChrome拡張ではなく、クロール機能を持つツールを使う必要があります。Octoparseはサイト全体を自動でクロールし、ページ一覧を一括取得できます。Pythonで実装する場合は再帰的なリンク収集ロジックが必要です。まずはOctoparseの無料プランで試してみることをおすすめします。
Q2. 無料でWebサイトURLを一括抽出できますか?
Chrome拡張(Link Extractor・LinkGopher・URLクリッパー)は単ページに限り完全無料で使えます。サイト全体の一括取得が必要な場合、Octoparseには月10,000件まで無料の無料プランがあります。小〜中規模のサイトであれば無料枠内で十分対応できます。
Q3. URL抽出とWebスクレイピングは何が違う?
URL抽出はWebスクレイピングの一種で、Webページ内のリンク(href属性)を対象としたデータ収集を指します。広義のWebスクレイピングは文章・価格・画像など任意のデータを対象にしますが、URL抽出はページ構造の把握やリンクマップの作成に特化した手法です。
Q4. JavaScriptで動的に生成されたURLも取得できますか?
静的HTMLのみを処理するBeautifulSoupや一部のChrome拡張では、JavaScriptで動的に生成されたリンクを取得できない場合があります。OctoparseはJavascriptレンダリング後のDOMに対してデータ抽出を行えるため、SPAやAjaxベースのサイトにも対応しています。
Q5. 取得したURLをSEO分析にどう活用すればいい?
取得したURLリストをCSVに出力し、スプレッドシートやSEOツール(Search Console・Screaming Frogなど)に読み込ませることで、インデックス状況・内部リンク本数・クロールエラーなどと照合できます。定期的にURL一覧を取得して差分を確認することで、新規ページの追加状況や削除されたページを把握することも可能です。
まとめ
サイトのページ一覧取得・URL一括抽出は、SEO対策・競合分析・コンテンツ管理において土台となる作業です。
- 単ページのチェックが目的なら → Link Extractor・LinkGopher・URLクリッパー(無料・即使える)
- サイト全体のURL一括取得が目的なら → Octoparse(ノーコード・クラウド対応・無料プランあり)
- SEOデータと組み合わせた高度な分析が目的なら → URL Profiler
- 自社システムに組み込みたいなら → OctoparseのAPI連携 または Octoparse MCP
Octoparseはノーコードで使い始められる無料プランを提供しており、最短数分でURL抽出を開始できます。まずは無料でお試しください。
競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール



