Pythonでクローラーを作りたい、あるいはクローリングやスクレイピングを始めたいと考えたとき、よく名前が挙がるのが Scrapy(スクレイピー)です。Scrapyは、PythonでWebサイトを巡回し、必要なデータを効率よく抽出するための代表的なフレームワークです。
一方で、Webデータ収集の方法はコードを書くやり方だけではありません。たとえば、コードを書かずに取得フローを試したい場合には、Octoparseのようなノーコードツールを活用する方法もあります。
本記事では、Pythonで柔軟にクローラーを作りたい方向けに、Pythonクローラーの基本から、クローリング・スクレイピングとの違い、Scrapyの仕組み、特徴、インストール方法、簡単な実装例までを初心者向けにわかりやすく解説します。これから Python でクローラーを作ってみたい方は、まず全体像をつかむところから始めてみましょう。
Pythonクローラーとは
Pythonクローラーとは、Pythonで作成されたプログラムがWeb上のリンクをたどりながらページを巡回し、必要な情報を集める仕組みのことです。一般的に「クローリング」はページをたどって集める工程、「スクレイピング」はページ内から必要なデータを抽出する工程を指します。
たとえばブログ一覧ページから各記事ページへ移動し、タイトルや著者名、公開日を集める処理は、クローリングとスクレイピングを組み合わせた典型例です。Pythonはライブラリやフレームワークが豊富なため、こうしたクローラーの開発に向いています。
クローリング・スクレイピング・Scrapyの違い
この3つは混同されやすい言葉ですが、役割は少しずつ異なります。
- クローリング:リンクをたどってページを巡回し、対象URLを収集すること
- スクレイピング:HTMLなどから必要な情報だけを抽出すること
- Scrapy:クローリングとスクレイピングの両方を効率よく行うための Python フレームワーク
つまり、Pythonクローラーを作りたい人にとって Scrapy は、巡回・抽出・保存までを一貫して扱いやすい選択肢の一つです。
なお、Webデータ収集の方法はScrapyのようなPythonフレームワークだけではありません。たとえば、GUIベースで設定しながら取得したい場合は Octoparse のようなノーコードツール、より細かく処理を制御したい場合は Scrapy のようなコードベースのフレームワークが向いています。「まずは手早く試したいか」「実装を細かく作り込みたいか」で選ぶとわかりやすいでしょう。
Scrapyとは
Scrapyは、Pythonで開発されたWebスクレイピング用のフレームワークです。フレームワークとは、アプリケーション開発でよく使う機能や構造をあらかじめ備えた土台のことを指します。Scrapyを使えば、必要最小限のコードでスパイダーを定義し、Webページの巡回とデータ抽出を進められます。
また、Scrapyはオープンソースで無料で利用でき、高速処理や拡張性にも優れています。単純な情報取得だけでなく、ページ遷移を伴うクローリングや、抽出したデータの加工・保存まで、実務で必要になりやすい処理をまとめて扱える点が大きな魅力です。
Pythonでクローラーを作る流れ
初心者が Python でクローラーを作るときは、いきなりコードを書くよりも、次の順番で考えると進めやすくなります。
- 対象サイトのリンク構造を確認する
- 一覧ページと詳細ページの役割を整理する
- どの項目を抽出するか決める
- HTML 構造やセレクタを確認する
- スパイダーを実装する
- 必要に応じて次ページや詳細ページをたどる
- 抽出データを JSON・CSV・データベースなどへ保存する
この流れを理解しておくと、Scrapyの内部構造や実践例もつながりやすくなります。
なお、対象ページの構造確認や抽出項目の整理の段階では、ブラウザの開発者ツールに加えて、Octoparse のような可視的に設定できるツールで取得可否を先に検証してから、必要に応じて Python / Scrapy に進む方法もあります。ノーコードで試作し、より細かな制御が必要になった段階でコード実装へ移る流れは、実務でも現実的です。
Scrapyの内部構造と機能詳細
Scrapyのアーキテクチャは、複数のコンポーネントとその間のデータフローで構成されています。ここでは、それぞれのコンポーネントと8つの主要なフローを詳しく見ていきましょう。
コンポーネント
コンポーネントとは、ソフトウェアやシステムを構成する個々の部品や要素のことを指します。Scrapyにおけるコンポーネントは、特定の機能や役割を持ち、システム全体の動作や機能を支えるために相互に連携して動作します。
- Scrapy Engine(エンジン): システムの中心で、各コンポーネント間の通信を担当します。
- Scheduler(スケジューラ): リクエストを受け取り、順序を決めてキューに入れ、エンジンが要求するときに提供します。
- Downloader(ダウンローダー): エンジンからのリクエストに基づき、ウェブページをダウンロードし、レスポンスをエンジンに返します。
- Spider(スパイダー): ダウンロードされたページからデータを抽出し、アイテムを生成または新しいリクエストをエンジンに送り返します。
- Item Pipeline(アイテムパイプライン): スパイダーから受け取ったアイテムを処理し、例えばデータベースに保存します。
- Downloader Middlewares(ダウンローダーミドルウェア): リクエストとレスポンスの処理をカスタマイズします。
- Spider Middlewares(スパイダーミドルウェア): スパイダーの入出力をカスタマイズします。
データフロー
Scrapyの全体の流れは以下の画像のとおりです。「⑥Engine」は、全体を制御するシステムのコアです。Scrapyにおいては、Engineを中心にデータ制御が行われます。
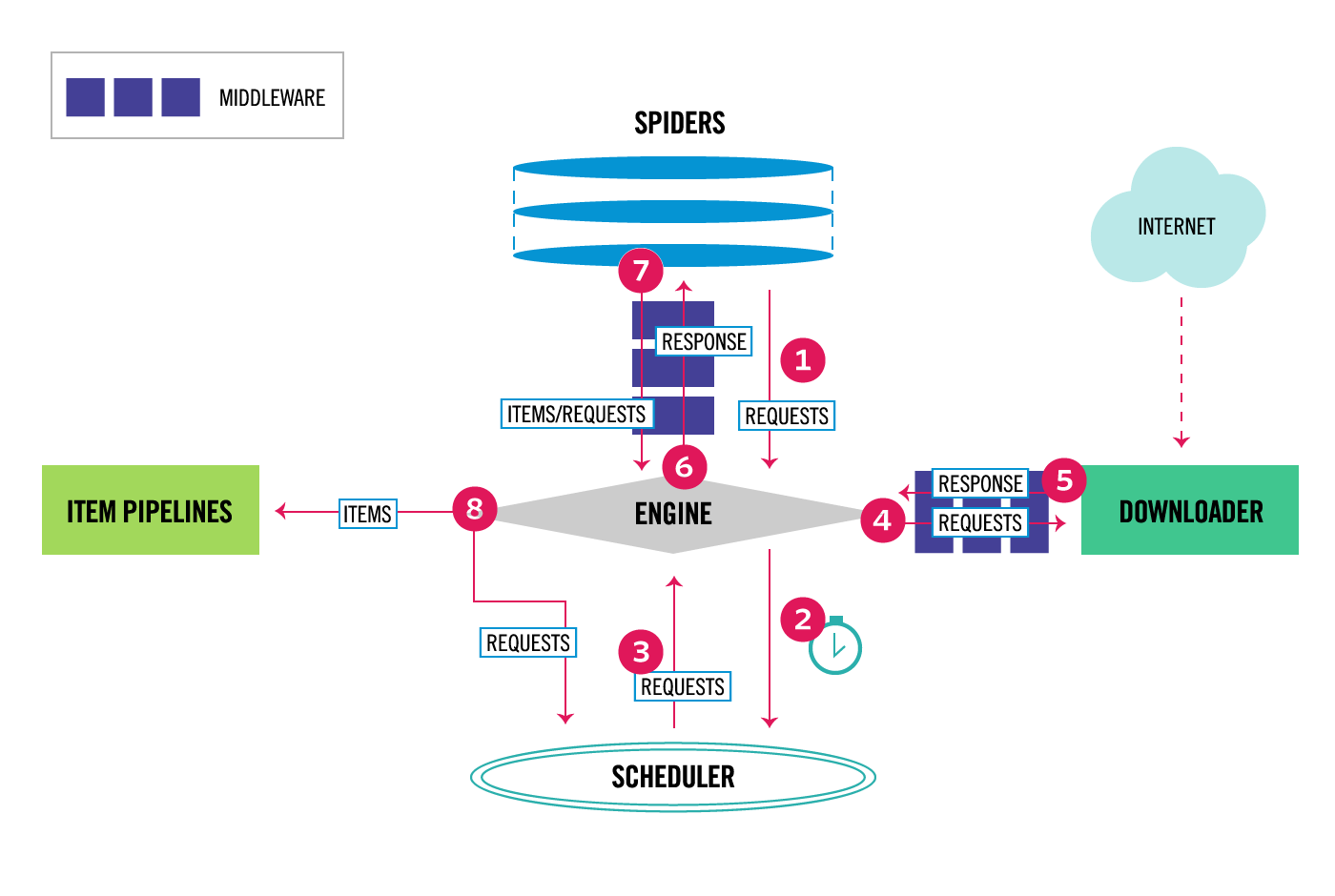
Scrapyでは、まずスパイダーが最初のリクエストをエンジンに渡します。エンジンはそのリクエストをスケジューラへ送り、順番待ちのキューに登録します。
次に、エンジンはスケジューラからリクエストを受け取り、ダウンローダーへ送信します。ダウンローダーが取得したレスポンスは再びエンジンを通ってスパイダーへ渡され、スパイダーはHTMLを解析してアイテムを抽出したり、次のページへのリクエストを返したりします。
抽出されたアイテムはアイテムパイプラインへ送られ、整形・重複処理・保存などが行われます。この流れが、キューにリクエストがなくなるまで繰り返されます。
Scrapyの特徴とは
Scrapyは、Pythonが開発したオープンソースのウェブスクレイピングフレームワークであり、その設計と機能には特徴があります。これらの特徴を理解することで、Scrapyがいかにウェブスクレイピングやデータ抽出のためのツールとして優れているかが理解いただけるでしょう。
非同期処理
ミドルウェア、拡張機能、パイプラインなどを組み合わせることで、認証、リトライ、データ保存、ログ管理などをプロジェクトの要件に合わせて追加しやすくなっています。小さな試作から実務向けの運用まで広げやすい点は、Scrapyの大きな強みです。
拡張可能なアーキテクチャ
Scrapyのアーキテクチャは非常に柔軟で、ユーザーが独自の機能を追加しやすいように設計されています。ミドルウェア、拡張機能、パイプラインなど、必要に応じてカスタマイズや拡張が可能です。これにより、特定のプロジェクト要件に合わせてScrapyを調整することができます。
ログとデバッグ
Scrapyは実行状況をログとして確認できるため、どのURLで失敗したのか、どの項目が取得できていないのかを追いやすい設計です。Scrapy Shell を使えば、セレクタの挙動や抽出ロジックを手元で試しながら調整することもできます。
アクセス負荷を抑える設定と robots.txt 対応
クローラーを運用するときは、速さだけでなく、対象サイトへの配慮も重要です。Scrapyではダウンロード間隔の調整やユーザーエージェント設定などを通じて、過度な負荷をかけにくい運用ができます。
また、robots.txt の扱いを確認しながらクロール方針を設計することも大切です。公開記事としては、「制限をどう回避するか」よりも、「対象サイトの条件を確認し、無理のない頻度で取得する」ことを重視した説明のほうが適切です。
Scrapyを活用する際の注意点
Scrapyを使用してウェブスクレイピングを行う際は、効率的にデータを収集するために、いくつかのポイントを押さえる必要があります。ここでは、Scrapyを使ってスクレイピングを成功させるための注意点をいくつか紹介します。
適切なクローラの設計
ウェブサイトごとに異なる構造を持っているため、スパイダーの設計はプロジェクトの成功に直結します。まず、対象となるウェブサイトのHTML構造を分析し、必要なデータがどのように配置されているかを理解することが重要です。
この情報をもとに、効率的にデータを抽出できるスパイダーを設計します。また、サイトがJavaScriptで動的にコンテンツを生成している場合は、ScrapyとSeleniumなどのブラウザ自動化ツールを組み合わせることも検討しましょう。
頻繁なデータバックアップ
スクレイピング中には予期せぬエラーが発生することがあります。例えば、ウェブサイトの構造が変更されたり、一時的にアクセスできなくなることがあります。
これらの問題によりデータが失われるリスクを避けるために、定期的にデータのバックアップを取ることが重要です。バックアップは、データの安全性を確保し、何か問題が発生した場合に迅速に対応できるようにするための基本的なステップです。
フェアプレイとエシカルスクレイピング
フェアプレイとエシカルスクレイピングは、ウェブサイトの利用規約を尊重し、サーバーに過度な負荷をかけないように配慮しながらデータを収集することを意味します。具体的には、robots.txtのルールを遵守し、アクセス頻度や速度を調整してサーバーへの負荷を最小限に抑えることが含まれます。
また、収集したデータを責任を持って扱い、プライバシーを尊重することも大切です。エシカルなスクレイピングを行うことで、ウェブコミュニティの健全な発展に貢献し、法的な問題を避けることができます。
セキュリティの確保
スクレイピングプロジェクトでは、収集したデータのセキュリティを確保することが非常に重要です。データの暗号化、安全な認証方法の使用、セキュリティパッチの適用など、適切なセキュリティ対策を講じることで、悪意のある攻撃からデータを守ります。
また、スクレイピングによって収集したデータが個人情報を含む場合は、データ保護法規に準拠して適切に管理することが求められます。
Scrapyのインストール手順
Scrapyを導入する際は、まず Python の仮想環境を作成し、その中にインストールする方法がわかりやすく安全です。環境を分けることで、他のプロジェクトとの依存関係の衝突を避けやすくなります。
1. 仮想環境を作成する
仮想環境を作成したら、OSに応じて有効化します。
2.Windowsでインストールする
Windowsでは、仮想環境を有効化したうえで pip を更新し、Scrapy をインストールします。
3.Ubuntuでインストールする
Ubuntu 系では、事前に依存関係を入れておくとスムーズです。Python 3 系のパッケージを使う形にそろえておくと管理しやすくなります。
4.macOSでインストールする
macOSでは、Xcode Command Line Tools を入れてから仮想環境を作成し、pip で Scrapy をインストールする流れが一般的です。
Scrapyスパイダーの実践例
ここからは、Scrapyを使用してウェブスクレイピングを行う際の基本的な手順を解説します。今回は例として、「Octoparseブログ」から記事のタイトル、著者、投稿日、記事URLを抽出するスパイダーの作成方法をステップバイステップで見ていきましょう。
1. 新しいプロジェクトを作成する
このコマンドでプロジェクトの基本構成が作成されます。
2. Item を定義する
まずは、抽出したいデータの形を items.py に定義します。続いて、Octoparseブログの記事タイトル、著者、投稿日、記事URLを抽出するためのItemを以下のように定義します。
3. Spiderを作成する
次に、spidersディレクトリにスパイダーファイルを作成します。以下は、Octoparseのブログ一覧ページ(https://www.octoparse.jp/blog)を想定したサンプルで、HTML構造に合わせてCSSセレクタを調整しています。
4. スパイダーを実行する
抽出結果を JSON として保存したい場合は、次のように実行できます。
これらの手順に従うことで、Scrapyを使用してOctoparseブログから記事のタイトル、著者、投稿日を抽出するスパイダーを作成し、実行することができます。
この例では、一覧ページの各記事カードから情報を取得し、さらに「次へ」のリンクがあれば次ページもたどります。これにより、スクレイピングだけでなく、クローリングの基本動作も確認できます。
なお、同じWebデータ収集でも、コードを書きながら動きを細かく制御したい場合はScrapy、画面操作ベースで取得フローを確認したい場合はOctoparseのようなツール、と考えるとイメージしやすいでしょう。目的に応じて使い分けることで、学習段階でも実務段階でも進めやすくなります。
まとめ
Pythonクローラーを作るうえで重要なのは、クローリングとスクレイピングの違いを理解し、どのページをどうたどり、どの項目をどう抽出するかを整理することです。Scrapyは、その一連の流れを効率よく実装しやすいフレームワークです。
本記事では、Scrapyの基本概念、内部構造、特徴、注意点、インストール方法、そして実践例までをひと通り紹介しました。これから Python でクローラーを学びたい方は、まず小さな対象サイトで構造を観察しながら、シンプルなスパイダーを作るところから始めてみてください。
一方で、コードを書かずに素早く取得フローを試したい場合は、Octoparse(オクトパス)のようなノーコードツールを活用する方法もあります。目的や運用体制に応じて、ノーコードツールとPythonフレームワークを使い分けることが、実務では現実的な選択肢になります。




