この記事はこんな方に向けて書いています:
- XのデータをPythonで取得したいが、何のライブラリを使えばいいか分からない
- Tweepyを使ったXスクレイピングの具体的なコードが欲しい
- X APIが有料化されたが、無料・低コストで収集を続ける方法を知りたい
- プログラミングが苦手だが、Xデータをビジネスやマーケティングにすぐ活用したい
この記事を読むと分かること:
- Xスクレイピングに使うPythonライブラリ(Tweepy・BeautifulSoup)の使い方とコード例
- ノーコードツール(Octoparse)とPythonの違いと選び方
- 収集後のデータ分析・可視化の基本フロー
執筆者について:Webスクレイピング実務経験5年以上、本記事のコードはPython 3.11環境で動作確認済み。
X(旧Twitter)は月間アクティブユーザー数が6億人超(出典:Statista, 2024)を誇る、ビジネスインサイトの宝庫です。ブランドモニタリング、競合分析、トレンド調査など、マーケターやデータサイエンティストがXデータをビジネスに活用する場面は急増しています。
「X スクレイピング Python でやるべきか、それともノーコードツールで十分か?」――本記事ではその問いに、実際の操作検証をもとに答えます。スキルや目的に応じた最適な方法を選べるよう、具体的な比較と手順を解説します。
スクレイピングとは
Webスクレイピングとは、プログラムがWebページのHTMLを解析し、必要な情報を自動的に抽出・保存する技術です。
X(Twitter)スクレイピングの主な活用例:
• ブランドモニタリング:自社製品への言及を自動収集・監視
• 競合分析:競合アカウントの投稿傾向をデータ化
• トレンド調査:ハッシュタグや流行語を定量分析
• 感情分析(センチメント分析):ポジ/ネガ反応を機械的に分類Pythonによるスクレイピングの入門手順は「PythonでWebスクレイピングする入門ガイド」でも解説しています。
スクレイピングの仕組みとビジネス活用事例についてはWebスクレイピングで何ができるか・活用事例まとめでも詳しく解説しています。
X(Twitter)スクレイピングの課題
X(旧Twitter)スクレイピングにはいくつかの課題があります。ここでは、主な課題について詳しく説明します。
APIの制限
X(旧Twitter)のデータをPythonで取得する場合、まず確認すべきなのがX APIの料金体系と利用制限です。2026年時点のX APIは、従来の月額プラン中心の説明ではなく、Pay-per-use(従量課金)モデルを前提に理解する必要があります。
X APIでは、開発者コンソールでクレジットを購入し、APIリクエストや取得したリソース数に応じてクレジットが消費されます。投稿データ、ユーザー情報、DMイベント、フォロワー情報など、取得するリソースの種類によって単価が異なります。また、既存ユーザーがBasicやProなどのレガシー契約を継続している場合もありますが、新しく利用する場合は、必ずX Developer Platform上で最新の料金と利用条件を確認してください。
特に注意すべき点は、X APIには料金だけでなく、エンドポイントごとのレート制限もあることです。短時間に大量のリクエストを送ると、429 Too Many Requests が返される場合があります。そのため、Pythonで実装する場合は、レスポンスヘッダーの x-rate-limit-remaining や x-rate-limit-reset を確認し、指数バックオフやキャッシュを組み合わせることが重要です。
スクレイピングの倫理と法的考慮事項
X(Twitter)でのスクレイピングには法的・倫理的な確認が不可欠です。X利用規約ではAPIを使用しない自動データ収集を原則禁止しており、違反した場合はアカウント停止や法的措置のリスクがあります。
安全にデータ収集するための3原則:
① 公式APIまたは規約が許可する範囲でのみ実施
② 個人情報を含むデータは個人情報保護法・GDPRに準拠して管理
③ 収集データの二次利用・商用利用は事前に利用規約を確認X(Twitter)でのスクレイピングの法的ポイントの詳細は「X(Twitter)でスクレイピングは禁止?」もご参照ください。
また、他人の投稿を無断で収集・使用することは、プライバシーの侵害や著作権侵害につながるリスクがあります。スクレイピングを行う前には、必ず対象サイトの利用規約を確認し、法的な問題がないかを検討する必要があります。
XでのAPIポリシーと合法的な収集範囲の詳細についてはXのAPIポリシーと合法的なデータ収集の注意点をご確認ください。
Python:プログラミングによるスクレイピング
Pythonは、ウェブスクレイピングにおいて非常に強力かつ柔軟なツールです。特に、カスタマイズ性や大規模データの処理において優れており、多くの開発者に利用されています。以下では、Pythonの特徴、必要なライブラリ、基本的なスクレイピングのコード例、そしてそのメリットとデメリットについて詳しく解説します。
Pythonの特徴
Pythonは、その柔軟性と拡張性から、さまざまな用途に対応できるプログラミング言語です。以下に、Pythonを使用する主な特徴を紹介します。
柔軟性
Pythonはオープンソースであり、多種多様なライブラリが提供されています。これにより、特定のウェブサイトや用途に応じて柔軟に対応することができます。
カスタマイズ性
ユーザーは自身のニーズに合わせてスクレイピングスクリプトを細かくカスタマイズできます。例えば、特定のデータフィールドのみを抽出したり、データの前処理をスクリプト内で行ったりすることが可能です。
大規模データ処理
Pythonにはpandasやnumpyなどの強力なデータ処理ライブラリがあり、大量のデータを効率的に処理・分析することができます。これにより、収集したデータの詳細な解析や機械学習モデルの構築が容易になります。
コミュニティサポート
Pythonは広範なコミュニティが存在し、問題解決のためのリソースが豊富にあります。オンラインフォーラムやドキュメント、チュートリアルなどが充実しており、学習やトラブルシューティングがしやすいです。
PythonでX(Twitter)データを取得する方法
PythonでXデータを取得する場合は、公式APIを前提にする方法と、一般的なWebスクレイピング用ライブラリを使う方法があります。ただし、Xの場合は非APIのスクレイピングやブラウザ自動化に関する制限があるため、実運用では公式APIを優先するべきです。
| ライブラリ | 位置づけ | 向いている用途 |
| xdk | X公式Python SDK | 新規実装、公式仕様に沿ったAPI連携、型ヒントや非同期処理を活用したい場合 |
| Tweepy | コミュニティライブラリ | 既存情報が多い。X API v2をPythonから扱いたい場合 |
| pandas | データ整理・分析ライブラリ | 取得した投稿データのCSV出力、集計、前処理 |
| matplotlib / seaborn | 可視化ライブラリ | 投稿数推移、反応数、キーワード傾向などの可視化 |
| Requests / BeautifulSoup | 一般的なHTML取得・解析ライブラリ | 通常の静的Webページ向け。Xの非API取得には慎重な判断が必要 |
| Selenium / Playwright | ブラウザ自動化ツール | 動的ページの検証には使えるが、Xに対する非API自動化は規約面の確認が必要 |
各ライブラリの詳細はXスクレイピングに使えるPythonライブラリの選び方と比較をご参照ください。
公式Python SDK「xdk」を使う場合
これから新規でX API連携を実装する場合は、まず公式ドキュメントで紹介されているPython SDK「xdk」を確認するとよいでしょう。以下は、Bearer Tokenを環境変数で管理し、検索APIから投稿を取得してCSVに保存する例です。
なお、以下のコードを実行するには、事前に公式Python SDK「xdk」と、データ整理用の「pandas」をインストールしておく必要があります。コマンドプロンプトまたはターミナルで、以下のコマンドを実行してください。
(X公式ドキュメントでも、Python XDKは pip install xdk でインストールできると案内されています。)
コード:
Tweepyを使う場合
Tweepyは公式SDKではありませんが、PythonでX APIを扱うコミュニティライブラリとして広く使われています。既存のサンプルや学習情報が多いため、既存コードの改修や学習用途では選択肢になります。
Tweepyを使う場合も、事前に「tweepy」と「pandas」をインストールしておく必要があります。まだインストールしていない場合は、コマンドプロンプトまたはターミナルで、以下のコマンドを実行してください。
(import はライブラリを読み込むための命令ですが、ライブラリ自体がPCに入っていない場合はエラーになるため、最初にインストールが必要です。)
コード:
| セキュリティ上の注意 Bearer Token、API Key、Access Tokenなどの認証情報は、コード内に直接書かないでください。GitHubなどに誤って公開されると、不正利用やアカウント停止のリスクがあります。環境変数、シークレット管理ツール、クラウドのSecret Managerなどで管理するのが基本です。 |
さらに詳しいデータ分析・感情分析(センチメント分析)への応用については、Xのデータ取得と活用方法の詳細解説もあわせてご参照ください。
Requests / BeautifulSoupでXを直接取得する方法は推奨しない
RequestsやBeautifulSoupは、通常のHTMLページを取得・解析するには便利です。しかし、Xの投稿検索ページを直接取得して解析する方法は、安定性と規約面の両方でリスクがあります。Xのページ構造は頻繁に変わり、JavaScriptによる動的表示やログイン状態の影響も受けます。
また、X公式のDeveloper Guidelinesでは、X上のデータ取得や自動化を行う場合、公式APIを使用することが求められており、スクレイピングやブラウザ自動化など、公式API以外の方法は認められていないと説明されています。そのため、Xデータを業務利用・研究利用・継続的な分析に使う場合は、まず公式APIの利用可否を確認する説明に変更するのが安全です。
よくあるエラーと対処法
XスクレイピングをPythonで実装する際に遭遇しやすいエラーをまとめました。

● 401 Unauthorized
原因:Bearer Token が無効または期限切れ。
対処:X Developer Portal でトークンを再発行し、コードの `BEARER_TOKEN` を更新してください。
● 429 Too Many Requests
原因:レート制限に到達(無料プランは月1,500件読み取りまで)。
対処:`time.sleep(60)` で待機するか、収集件数を減らします。大量収集が必要な場合はOctoparseのクラウド収集への移行を検討してください(Octoparseの無料プランを試す)。
● 453 Access Forbidden
原因:ご利用のプランに含まれないAPIエンドポイントへのアクセス。
対処:X Developer PortalでAPIプランを確認してください。無料プランではユーザー情報取得APIは利用できません。
● 空のDataFrameが返される
原因:検索クエリに一致するポストが0件、またはクエリ記法が誤っている。対処:X検索(x.com/search)で同じクエリを手動確認。`”lang:ja”` や `”-is:retweet”` の組み合わせを見直してください。
Octoparse:コード不要のX(Twitter)スクレイピングツール
Octoparseは、プログラミング不要でWebデータ収集タスクを作成できるノーコード型スクレイピングツールです。X(Twitter)関連テンプレートを利用すれば、キーワードや検索結果URLなどを入力して、公開ページ上の投稿情報を収集できます。
Pythonと比べると、Octoparseは初期設定が簡単で、テンプレート・クラウド実行・スケジュール実行を利用しやすい点が強みです。一方で、対象サイトの構造変更、ログイン状態、アクセス制限、規約上の制限が関係する場合は、テンプレートであっても必ず安定するとは限りません。
以下では、Octoparseの特徴、データ収集の基本ステップ、そしてメリットとデメリットについて詳しく解説します。
Octoparseの特徴
Octoparseは、その使いやすさと機能の豊富さから、多くのユーザーに支持されています。
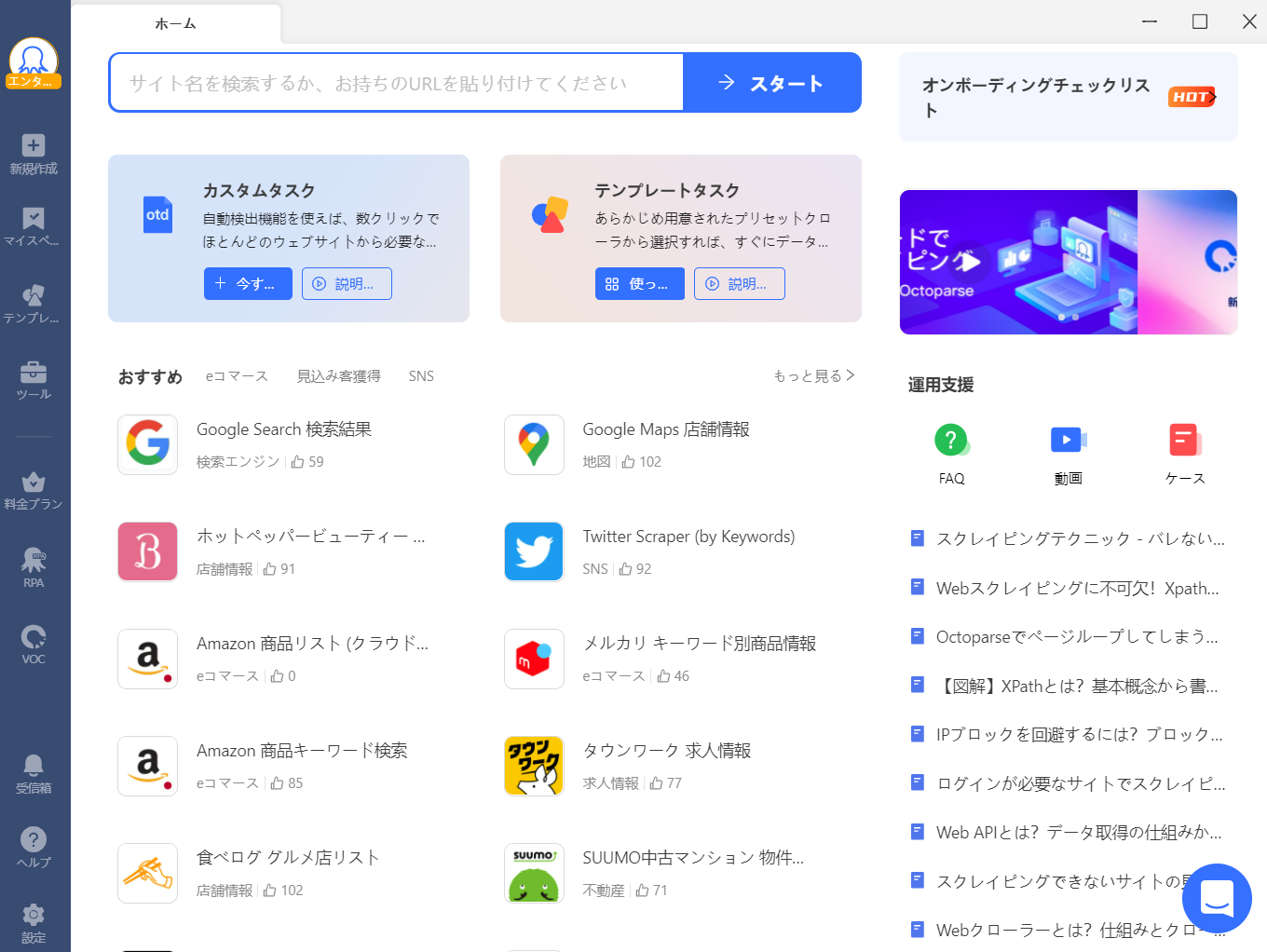
ユーザーフレンドリーなインターフェース
Octoparseは直感的なドラッグ&ドロップ操作を採用しており、プログラミングの知識がなくても簡単にスクレイピングタスクを設定できます。このインターフェースにより、初心者でも短時間で効果的なスクレイピングが可能です。
テンプレートの利用
Octoparseには、事前に用意された多種多様なテンプレートが揃っています。これらのテンプレートを使用することで、ユーザーは複雑な設定を行うことなく、すぐにスクレイピングを開始できます。テンプレートは特定のWebサイトや用途に合わせて最適化されており、非常に便利です。
https://www.octoparse.jp/template/twitter-scraper-by-keywords
https://www.octoparse.jp/template/twitter-scraper-by-account-url
クラウドベースのデータ処理
Octoparseはクラウド上でデータの収集と処理を行います。このため、ローカル環境の制約を受けずに、大量のデータを効率的に収集できます。また、クラウドベースの処理により、作業の進行中でも他のタスクにリソースを割り当てることが可能です。
スケジューリング機能
Octoparseにはスクレイピングの実行時間をスケジュール設定できる機能があります。これにより、定期的なデータ収集を自動化し、最新のデータを継続的に取得することができます。この機能は、マーケティングリサーチや競合分析などで非常に有用です。
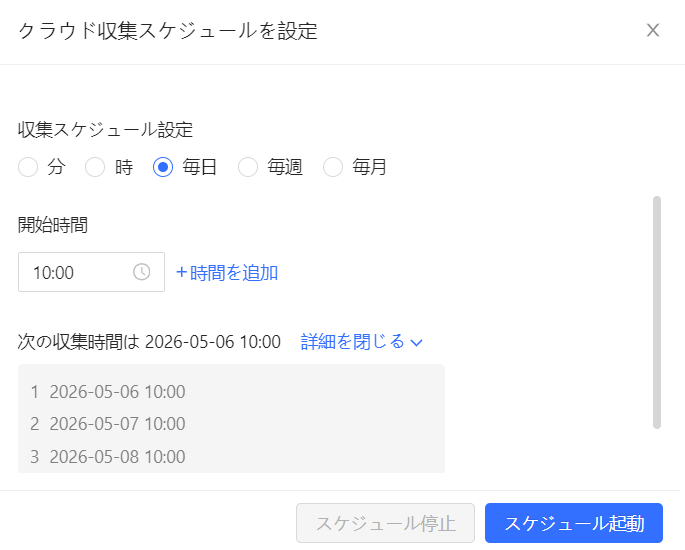
データ収集の基本ステップ
OctoparseでXのポストデータを収集する手順:
① Octoparseをダウンロード・ログイン後、テンプレート画面を開く
② 「SNS」カテゴリから「Twitter Scraper(by Keywords)」を選択
③ 収集したいキーワード(例:「Pythonスクレイピング」)を入力し保存
④ 「実行」ボタンを押す。クラウド上でデータ収集が自動開始
⑤ 完了後、CSV・Excel形式でダウンロード
テンプレートの詳細・設定方法は以下のページをご参照ください。
http://octoparse.jp/template/twitter-scraper-by-keywords
※ Xのページ構造が変更された場合でもOctoparseのテンプレートは自動更新されるため、Pythonスクリプトのような手動メンテナンスが不要です。
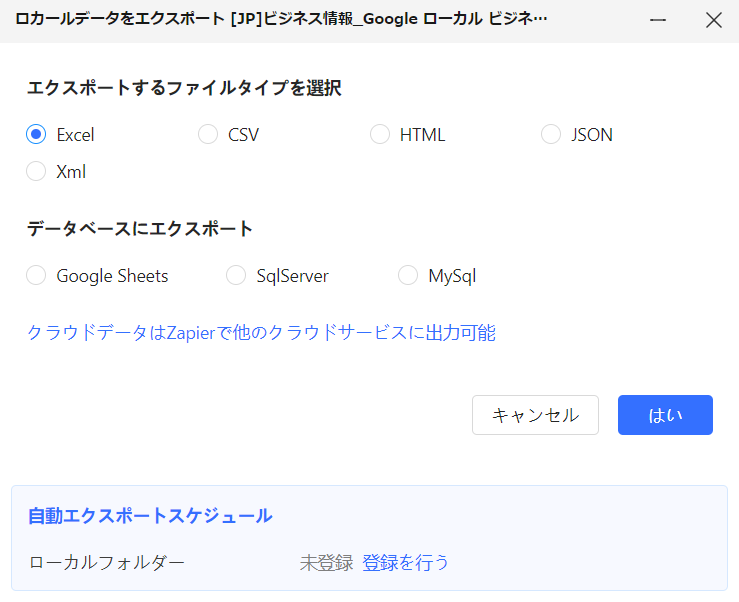
メリットとデメリット
Octoparseは機能性・利便性の高いスクレイピングツールですが、必ずしも万能ではありません。ここでは、Octoparseのメリットとデメリットをそれぞれ紹介します。
メリット
- プログラミング知識が不要:Octoparseは、誰でも簡単にスクレイピングを開始できるツールです。プログラミングの知識が不要で、直感的な操作が可能です。
- 迅速なデータ収集:テンプレートを利用することで、迅速にデータ収集を行うことができます。設定が簡単で、短時間でスクレイピングを開始できます。
- クラウドベースの処理:クラウド上でデータを処理するため、ローカル環境の制約を受けません。大量のデータを効率的に収集でき、他の作業に影響を与えません。
デメリット
- 柔軟性の欠如:複雑なカスタマイズが必要な場合、Octoparseは柔軟性に欠けることがあります。特定の要件に対応するためには、プログラミングが必要となる場合があります。
- コストの問題:無料プランでは利用制限があるため、大量データの収集や高度な機能を利用するには有料プランが必要になります。これにより、コストが発生することがあります。
OctoparseとPythonの比較
OctoparseとPythonのどちらを選択するかは、ユーザーのスキルレベル、プロジェクトの要件、そして具体的なニーズによります。
ここでは、処理速度とパフォーマンス、使いやすさ、コスト、大規模データ収集、カスタマイズ性といった観点から、OctoparseとPythonを比較します。それぞれの特徴を理解し、最適なツールを選択するための参考にしてください。
| 比較項目 | Octoparse | Python(Tweepy・公式API) | Python(非公式手法) |
| 学習コスト | 低い(不要) | 中程度(APIキー設定必要) | 中程度(Python基礎必要) |
| 初期設定時間 | 5〜10分 | 30分〜数時間 | 30分〜1時間 |
| X APIキー | 不要 | 必要(有料プランあり) | 不要 |
| データ収集量 | 大量OK(クラウド処理) | プランによる制限あり | 制限なし(ただし不安定) |
| カスタマイズ性 | 中程度 | 高い | 高い |
| 費用 | 無料プランあり | APIは有料プランが必要 | 無料(ライブラリのみ) |
| 法的リスク | 低(規約準拠) | 低(公式API使用) | 高(X利用規約違反リスク) |
| おすすめ対象 | ノンコーダー・マーケター | エンジニア・研究者 | 上級者・自己責任 |
処理速度とパフォーマンス
Octoparseはクラウドベースで動作するため、大量のデータを短時間で収集できます。クラウドサーバーのリソースを活用することで、個々のコンピュータの性能に依存せずに効率的なデータ収集が可能です。
一方、Pythonでのスクレイピングはローカル環境で実行されるため、処理速度は使用するハードウェアに依存します。ただし、Pythonは高度なカスタマイズが可能で、特定の要件に最適化することで高いパフォーマンスを発揮することができます。
初心者の取り掛かりやすさ
Octoparseはプログラミング知識が不要で、直感的なインターフェースを備えているため、初心者でも簡単に利用できます。テンプレートを利用することで、設定も短時間で完了します。
対して、Pythonはプログラミングの知識が必要で、スクレイピングの実装には一定の学習が必要です。そのため、プログラミング初心者には敷居が高いですが、学習することでより柔軟なデータ収集が可能になります。
コスト(時間と費用)
Octoparseの無料プランでは利用に制限がありますが、手軽に始められます。大量のデータを収集する場合や高度な機能を利用する場合には、有料プランが必要になることがあります。
一方、Pythonはオープンソースのライブラリを利用するため、ソフトウェアのライセンス費用はかかりませんが、設定やスクリプトの作成に時間がかかる場合があります。
大規模データ収集
Octoparseはクラウドベースで大規模なデータ収集を効率的に行うことができます。スケジューリング機能や並列処理により、大量のデータを迅速に収集できます。
Pythonも大規模なデータ収集に対応できますが、処理速度やメモリ使用量の管理が重要となります。適切なライブラリや手法を用いることで、Pythonでも大規模データを効果的に収集・処理できます。
カスタマイズ性重視
Pythonは高いカスタマイズ性を持ち、特定の要件に合わせて柔軟にスクレイピングスクリプトを作成できます。必要に応じて新しいライブラリを追加し、機能を拡張することができます。
一方、Octoparseはテンプレートベースで簡便に利用できる反面、複雑なカスタマイズには限界があります。特定のニーズに合わせた高度な設定が必要な場合には、Pythonが適しています。
https://www.octoparse.jp/template/tweets-comments-scraper-by-search-result-url
収集後のデータ活用フロー
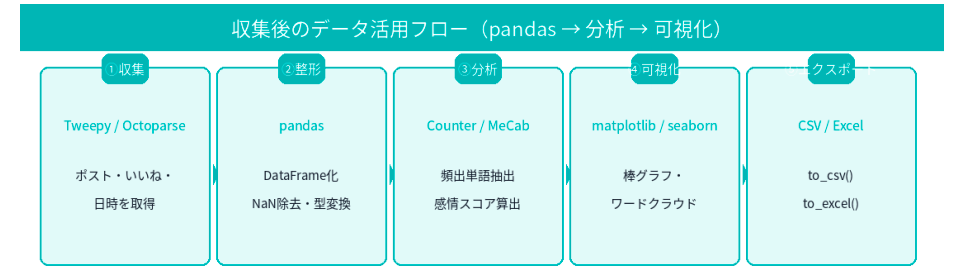
よくある質問(FAQ)
Q1. XのデータをPythonで取得するのは2025年現在も有効ですか?
はい。Tweepy + X APIの組み合わせが公式推奨ですが、無料プランでは月1,500件の読み取りに制限されています。大量収集にはBasicプラン($100/月)以上、またはOctoparseとの費用比較を推奨します。
Q2. X APIを使わずPythonでスクレイピングできますか?
技術的には可能ですが、XのHTMLは頻繁に変更されるためスクリプトの維持コストが高くなります。安定性と規約遵守の観点から、公式APIの使用またはOctoparseを推奨します。
Q3. OctoparseはX APIなしでデータを取得できますか?
はい。Octoparseはブラウザ操作を自動化してデータを収集するためAPIキーは不要です。ただし過度なアクセスはX利用規約に抵触する可能性があるため、収集頻度への配慮が必要です。
Q4. PythonとOctoparse、どちらが大量データ収集に向いていますか?
設定の手軽さと安定性ではOctoparseが優位です(クラウド並列処理・スケジュール機能)。Pythonはasyncioで高速化できますが、実装・維持コストが高いため、エンジニアリングリソースがある場合に限って推奨します。
Q5. XのデータをPythonで分析する際のおすすめライブラリは?
収集にTweepy、整形・分析にpandas、可視化にmatplotlib/seabornの組み合わせが標準的です。感情分析には transformers(HuggingFace)との連携も一般的です。各ライブラリの詳細はXスクレイピングに使えるPythonライブラリの選び方と比較もご参照ください。
まとめ
本記事では、X(旧Twitter)のデータをPythonでスクレイピングする方法と、ノーコードツールOctoparseの使い方を徹底比較しました。
選択の目安:
• プログラミングが苦手・今すぐデータが欲しい → Octoparseのテンプレートが最速
• Pythonが使える・公式APIを活用したい → TweepyによるX API連携がベスト
• 大規模な自動収集・カスタム分析が必要 → Pythonカスタムスクリプトが最適
X以外のSNSデータ収集に興味のある方は、「Webスクレイピングにオススメツール10選」もご覧ください。
また、ハッシュタグを軸にXデータを分析したい方は、「Xのハッシュタグデータを自動収集・分析する方法」もあわせてチェックしてみてください。
さらに、SNS分析ツール全般を比較したい方は、「SNS分析ツール11選と横断活用のすすめ

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール