現代のマーケティングにおいて、SNSからのデータ収集は欠かせないものとなっています。特にX(旧Twitter)は、多くの企業や個人がリアルタイムで情報を発信するプラットフォームとして重要です。しかし、Xから効率的にデータを取得するためには、適切なツールやスキルが必要です。
本記事では、プログラミング不要のスクレイピングツールであるOctoparseと、プログラミングが必須となるPythonを用いたXスクレイピングについて、両者を徹底比較します。それぞれの方法の特徴やメリット、そして具体的な使い方を解説しますので、どちらを使えばよいか迷っている方はぜひ参考にしてください。
スクレイピングとは
Webスクレイピングとは、Webサイトからデータを自動的に収集する技術です。通常、スクレイピングは特定の目的のためにWebページの内容を解析し、その情報を取得、保存、処理するプロセスを指します。この技術は、マーケティングリサーチ、価格モニタリング、データ分析など、多岐にわたる分野で利用されています。
X(Twitter)スクレイピングの課題
X(旧Twitter)スクレイピングにはいくつかの課題があります。ここでは、主な課題について詳しく説明します。
APIの制限
Xは公式APIを提供しており、多くのデータ収集はこのAPIを通じて行われます。しかし、APIには使用制限やアクセス制限があり、一定のリクエスト数を超えると追加料金が発生する場合があります。
また、無料で使用できるAPIには取得できるデータの範囲や頻度に制約があるため、大量のデータを短期間で収集するのは難しいことが多いです。
スクレイピングの倫理と法的考慮事項
スクレイピングを行う際には、倫理的および法的な考慮が必要です。例えば、Xの利用規約に違反する方法でデータを収集することは、アカウントの停止や法的措置を招く可能性があります。
また、他人の投稿を無断で収集・使用することは、プライバシーの侵害や著作権侵害につながるリスクがあります。スクレイピングを行う前には、必ず対象サイトの利用規約を確認し、法的な問題がないかを検討する必要があります。
X(Twitter)でスクレイピングのポイントと注意点について
Octoprase:コード不要のスクレイピングツール
Octoparseは、プログラミング知識がない人でも簡単にWebスクレイピングを行うことができる強力なツールです。以下では、Octoparseの特徴、データ収集の基本ステップ、そしてメリットとデメリットについて詳しく解説します。
Octoparseの特徴
Octoparseは、その使いやすさと機能の豊富さから、多くのユーザーに支持されています。ここでは、Octoparseの主要な特徴を紹介します。
ユーザーフレンドリーなインターフェース
Octoparseは直感的なドラッグ&ドロップ操作を採用しており、プログラミングの知識がなくても簡単にスクレイピングタスクを設定できます。このインターフェースにより、初心者でも短時間で効果的なスクレイピングが可能です。
テンプレートの利用
Octoparseには、事前に用意された多種多様なテンプレートが揃っています。これらのテンプレートを使用することで、ユーザーは複雑な設定を行うことなく、すぐにスクレイピングを開始できます。テンプレートは特定のWebサイトや用途に合わせて最適化されており、非常に便利です。
https://www.octoparse.jp/template/twitter-scraper-by-keywords
クラウドベースのデータ処理
Octoparseはクラウド上でデータの収集と処理を行います。このため、ローカル環境の制約を受けずに、大量のデータを効率的に収集できます。また、クラウドベースの処理により、作業の進行中でも他のタスクにリソースを割り当てることが可能です。
スケジューリング機能
Octoparseにはスクレイピングの実行時間をスケジュール設定できる機能があります。これにより、定期的なデータ収集を自動化し、最新のデータを継続的に取得することができます。この機能は、マーケティングリサーチや競合分析などで非常に有用です。
データ収集の基本ステップ
Octoparseを使用してデータを収集する手順は簡単で、以下のステップで行います。
- テンプレートの選択:まず、Octoparseのホーム画面から目的に合ったテンプレートを選択します。テンプレートは、特定のWebサイトや一般的なスクレイピングタスクに対応したものが用意されています。
- パラメーターの設定:選択したテンプレートに対して、スクレイピング対象のWebページのURLや検索キーワードなどのパラメーターを設定します。この設定により、スクレイピングの対象範囲や条件を細かく指定できます。
- タスクの実行:設定が完了したら、タスクを実行します。Octoparseは指定された条件に基づいてWebページを巡回し、データの抽出を開始します。進行状況はリアルタイムで確認することができます。
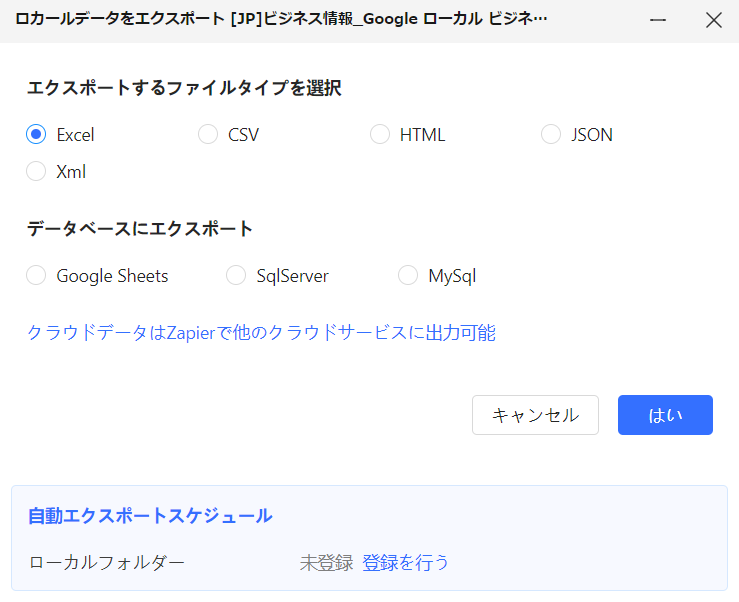
- データのエクスポート:収集が完了したデータは、ExcelやCSVなどの形式でエクスポートできます。これにより、収集したデータを簡単に分析やレポート作成に利用できます。
メリットとデメリット
Octoparseは機能性・利便性の高いスクレイピングツールですが、必ずしも万能ではありません。ここでは、Octoparseのメリットとデメリットをそれぞれ紹介します。
メリット
- プログラミング知識が不要:Octoparseは、誰でも簡単にスクレイピングを開始できるツールです。プログラミングの知識が不要で、直感的な操作が可能です。
- 迅速なデータ収集:テンプレートを利用することで、迅速にデータ収集を行うことができます。設定が簡単で、短時間でスクレイピングを開始できます。
- クラウドベースの処理:クラウド上でデータを処理するため、ローカル環境の制約を受けません。大量のデータを効率的に収集でき、他の作業に影響を与えません。
デメリット
- 柔軟性の欠如:複雑なカスタマイズが必要な場合、Octoparseは柔軟性に欠けることがあります。特定の要件に対応するためには、プログラミングが必要となる場合があります。
- コストの問題:無料プランでは利用制限があるため、大量データの収集や高度な機能を利用するには有料プランが必要になります。これにより、コストが発生することがあります。
Python:プログラミングによるスクレイピング
Pythonは、ウェブスクレイピングにおいて非常に強力かつ柔軟なツールです。特に、カスタマイズ性や大規模データの処理において優れており、多くの開発者に利用されています。以下では、Pythonの特徴、必要なライブラリ、基本的なスクレイピングのコード例、そしてそのメリットとデメリットについて詳しく解説します。
Pythonの特徴
Pythonは、その柔軟性と拡張性から、さまざまな用途に対応できるプログラミング言語です。以下に、Pythonを使用する主な特徴を紹介します。
柔軟性
Pythonはオープンソースであり、多種多様なライブラリが提供されています。これにより、特定のウェブサイトや用途に応じて柔軟に対応することができます。
カスタマイズ性
ユーザーは自身のニーズに合わせてスクレイピングスクリプトを細かくカスタマイズできます。例えば、特定のデータフィールドのみを抽出したり、データの前処理をスクリプト内で行ったりすることが可能です。
大規模データ処理
Pythonにはpandasやnumpyなどの強力なデータ処理ライブラリがあり、大量のデータを効率的に処理・分析することができます。これにより、収集したデータの詳細な解析や機械学習モデルの構築が容易になります。
コミュニティサポート
Pythonは広範なコミュニティが存在し、問題解決のためのリソースが豊富にあります。オンラインフォーラムやドキュメント、チュートリアルなどが充実しており、学習やトラブルシューティングがしやすいです。
必要なライブラリ(BeautifulSoup, Selenium等)
Pythonでウェブスクレイピングを行う際はライブラリを利用します。代表的なライブラリは次のとおりです。
- BeautifulSoup:HTMLやXMLからデータを抽出するためのライブラリです。ウェブページのパースが簡単で、特定のタグや属性からデータを取得するのに便利です。
- Selenium:ウェブブラウザの自動操作を行うためのライブラリです。JavaScriptで動的に生成されるコンテンツのスクレイピングに特に有用です。
- Requests:ウェブページにHTTPリクエストを送信し、その内容を取得するためのライブラリです。シンプルなAPIで、GETやPOSTリクエストを簡単に行えます。
- pandas:データの操作と解析を行うためのライブラリです。データフレーム形式でデータを扱うことができ、読み込み、書き込み、変換などの操作が容易です。
メリットとデメリット
Pythonはプログラミングスキルがある方にとって、最も柔軟にデータ収集が可能です。スクレイピングツールと比較したメリットとデメリットをそれぞれ紹介します。
メリット
- 高度なカスタマイズが可能:特定のニーズに応じたスクレイピングができ、必要なデータのみを効率的に取得できます。
- 大規模なデータ処理や解析が可能:pandasやnumpyなどのライブラリを使用することで、大量のデータを効果的に処理・分析できます。
- オープンソースツールが豊富:無料で利用できるオープンソースのライブラリが多く、さまざまな用途に対応できます。
デメリット
- プログラミング知識が必要:Pythonでのスクレイピングにはプログラミングの知識が必要であり、初心者には学習コストが高いです。
- 設定やメンテナンスに時間がかかる:スクレイピングスクリプトの設定やメンテナンスには時間がかかることがあり、特にウェブサイトの構造が変更された場合にはスクリプトの修正が必要です。
X(Twitter)スクレイピングの基本的なコード例
以下に、指定されたキーワードでXを検索し、指定された数のポスト(ツイート)を取得してデータフレームに保存する基本的なコード例と、Tweepyを使用した手順を示します。
スクレイピングの基本的なコード例
このコードは、指定されたキーワードでXを検索し、指定された数のポスト(ツイート)を取得してデータフレームに保存します。requestsライブラリを使用してXの検索ページにアクセスし、BeautifulSoupを使ってポストのテキストを抽出します。抽出したポストは、pandasデータフレームに保存されます。
使用方法
requests、BeautifulSoup、および pandas ライブラリがインストールされていることを確認します。
上記のコードを実行します。get_twitter_data 関数は、指定されたキーワードでツイートを検索し、指定された数のツイートを取得してデータフレームに保存します。
注意:X(Twitter)のHTML構造が変わった場合や、アクセスが制限された場合に動作しない可能性があります。その場合、Twitter APIを使用することをお勧めします。
Tweepyを使用したTwitterデータの取得手順
以下の手順に従って、Twitter APIを使用してデータを取得する方法を示します。
使用手順
1.Tweepyのインストール:以下のコマンドを実行してTweepyをインストールします。
2.Twitter APIキーの取得:Twitter開発者アカウントを作成し、APIキーとアクセス・トークンを取得します。
3.コードの修正:上記のコードの【 YOUR_API_KEY】 などの部分を実際のAPIキーとアクセス・トークンで置き換えます。
この方法は公式にサポートされており、安定かつ信頼性が高いです。
OctoparseとPythonの比較
OctoparseとPythonのどちらを選択するかは、ユーザーのスキルレベル、プロジェクトの要件、そして具体的なニーズによります。
ここでは、処理速度とパフォーマンス、使いやすさ、コスト、大規模データ収集、カスタマイズ性といった観点から、OctoparseとPythonを比較します。それぞれの特徴を理解し、最適なツールを選択するための参考にしてください。
処理速度とパフォーマンス
Octoparseはクラウドベースで動作するため、大量のデータを短時間で収集できます。クラウドサーバーのリソースを活用することで、個々のコンピュータの性能に依存せずに効率的なデータ収集が可能です。
一方、Pythonでのスクレイピングはローカル環境で実行されるため、処理速度は使用するハードウェアに依存します。ただし、Pythonは高度なカスタマイズが可能で、特定の要件に最適化することで高いパフォーマンスを発揮することができます。
初心者の取り掛かりやすさ
Octoparseはプログラミング知識が不要で、直感的なインターフェースを備えているため、初心者でも簡単に利用できます。テンプレートを利用することで、設定も短時間で完了します。
対して、Pythonはプログラミングの知識が必要で、スクレイピングの実装には一定の学習が必要です。そのため、プログラミング初心者には敷居が高いですが、学習することでより柔軟なデータ収集が可能になります。
コスト(時間と費用)
Octoparseの無料プランでは利用に制限がありますが、手軽に始められます。大量のデータを収集する場合や高度な機能を利用する場合には、有料プランが必要になることがあります。
一方、Pythonはオープンソースのライブラリを利用するため、ソフトウェアのライセンス費用はかかりませんが、設定やスクリプトの作成に時間がかかる場合があります。
大規模データ収集
Octoparseはクラウドベースで大規模なデータ収集を効率的に行うことができます。スケジューリング機能や並列処理により、大量のデータを迅速に収集できます。
Pythonも大規模なデータ収集に対応できますが、処理速度やメモリ使用量の管理が重要となります。適切なライブラリや手法を用いることで、Pythonでも大規模データを効果的に収集・処理できます。
カスタマイズ性重視
Pythonは高いカスタマイズ性を持ち、特定の要件に合わせて柔軟にスクレイピングスクリプトを作成できます。必要に応じて新しいライブラリを追加し、機能を拡張することができます。
一方、Octoparseはテンプレートベースで簡便に利用できる反面、複雑なカスタマイズには限界があります。特定のニーズに合わせた高度な設定が必要な場合には、Pythonが適しています。
https://www.octoparse.jp/template/tweets-comments-scraper-by-search-result-url
まとめ
本記事では、X(旧Twitter)のポストをスクレイピングする際に役立つOctoparseとPythonについて、両者の特徴やメリット・デメリットを解説しました。それぞれの方法は異なる利便性や課題があるため、目的やスキルレベルに応じた適切な選択が重要です。
Octoparseは初心者や迅速なデータ収集を求める場合に適しており、Pythonは柔軟性や高度なカスタマイズが必要な場合に最適です。ご自身の状況に合わせて最適なツールを選び、効率的なデータ収集を実現しましょう。




