インターネット上には、商品情報、口コミ、ニュース、求人、企業情報、価格データなど、ビジネスに活用できる膨大な情報があります。こうしたWebデータを手作業で集めるには時間がかかりますが、クローラーやWebクローラーを使えば、対象サイトを自動で巡回し、必要なデータを効率よく収集できます。
本記事では、「クローリングとは何か」「webクローラーとスクレイピングの違い」「サイト クローリングに適したツールの選び方」を整理したうえで、Webデータ収集に役立つWebクローラーツール・サービス9選を紹介します。ノーコードで使えるものから、SEO監査向け、開発者向けフレームワーク、代行サービスまで、用途別に比較できるようにまとめました。
この記事でわかること
- Webクローラー、ウェブクローラー、クローリングの意味
- WebクローラーとWebスクレイピングの違い
- web クローリングツールを選ぶときの比較ポイント
- 目的別におすすめのWebクローラーツール・サービス
- クローラー運用時の注意点と法的リスク
Webクローラーとは?クローリングの基本
Webクローラーとは、Webサイト上のページを自動で巡回し、リンクをたどりながら情報を収集するプログラムです。日本語では「ウェブクローラー」と表記されることもあります。検索エンジンのインデックス作成だけでなく、価格調査、競合分析、営業リスト作成、SEO監査、ニュース収集など、幅広い業務で利用されています。
クローラーがWebページを巡回する一連の処理をクローリングと呼びます。たとえばECサイトの商品一覧ページから詳細ページへ移動し、商品名、価格、在庫、レビュー数などを順番に確認する処理は、サイト クローリングの代表例です。
Webクローラーとスクレイピングの違い
WebクローラーとWebスクレイピングは混同されやすい言葉ですが、役割が少し異なります。クローリングは「ページを見つけて巡回すること」、スクレイピングは「ページ内から必要な情報を抽出すること」です。
| 項目 | クローリング | スクレイピング |
|---|---|---|
| 主な目的 | URLを巡回し、ページを発見・取得する | HTMLから必要なデータを抽出する |
| 例 | サイト内リンクをたどる | 価格、商品名、口コミを抜き出す |
| 使う場面 | サイト全体の調査、SEO監査、ページ発見 | データ分析、リスト作成、価格監視 |
| 関係性 | データ収集の入口 | 取得したページから値を取り出す処理 |
実務では、Webクローラーでページを巡回し、スクレイピングで必要な情報を抽出する流れが一般的です。そのため、この記事では「web クローラー」「web クローリングツール」という検索意図に合わせて、巡回機能とデータ抽出機能の両方を見ていきます。
Webクローラーの主な用途
- 市場調査:競合企業の商品、価格、キャンペーン情報を定期的に収集する
- EC価格監視:自社商品と競合商品の価格差、在庫、レビューを確認する
- 営業リスト作成:企業情報、店舗情報、問い合わせ先などを収集する
- SEO監査:サイト内リンク、404エラー、タイトル、メタ情報、robots.txtを確認する
- ニュース・SNS監視:特定キーワードに関する投稿や記事を継続的に追跡する
- AI・データ分析:分析用データセットや学習用データを構造化して準備する
Webクローラーの種類
集中型クローラー
特定のテーマやドメインに絞って巡回するクローラーです。ニュース、求人、EC、口コミなど、目的が明確なデータ収集に向いています。無関係なページまで広げにくいため、クローリング効率を高めやすい点が特徴です。
インクリメンタルクローラー
一度取得したページを定期的に再訪問し、変更があった情報だけを更新するクローラーです。価格監視、在庫チェック、ニュース更新、サイト更新検知など、データの鮮度が重要な用途に適しています。
パラレルクローラー
複数の処理を並行して実行し、大量ページを効率的に取得するクローラーです。大規模サイトの監査や大量データ収集では有効ですが、対象サイトへの負荷を高めすぎないようにクロール頻度や同時接続数の調整が必要です。
分散型クローラー
複数のサーバーや実行環境でクローリングを分担する仕組みです。広範囲のWebデータを継続的に集める場合に向いていますが、運用設計、ログ管理、アクセス制御、データ品質管理が重要になります。
Webクローラーツールの選び方
Webクローラーツールを選ぶ際は、「有名なツールかどうか」だけでなく、取得したいデータの種類、対象サイトの構造、運用担当者のスキル、コスト、法的リスクへの対応を総合的に確認しましょう。
| 選定ポイント | 確認すべきこと |
|---|---|
| 対象サイトの構造 | 静的HTMLか、JavaScriptで動的に表示されるページか |
| 操作のしやすさ | ノーコードで設定できるか、プログラミングが必要か |
| クローリング範囲 | 1ページ単位か、サイト全体・複数サイトを巡回できるか |
| 抽出データ | テキスト、画像、リンク、PDF、表データなどに対応しているか |
| 出力形式 | CSV、Excel、JSON、データベース、API連携に対応しているか |
| スケジュール実行 | 毎日・毎週など、定期的なクローリングが可能か |
| 運用リスク | robots.txt、利用規約、個人情報、アクセス負荷に配慮できるか |
| サポート体制 | 日本語対応、代行サービス、カスタマーサポートの有無 |
Webクローラーツール・サービス比較表
| ツール・サービス | 向いている用途 | 特徴 |
|---|---|---|
| Octoparse | ノーコードのデータ収集、EC価格調査、営業リスト作成 | クリック操作、テンプレート、クラウド実行、定期実行 |
| Screaming Frog SEO Spider | SEO監査、サイト クローリング、技術的SEO | 500 URLまで無料、JavaScriptレンダリング、XPath抽出 |
| Semrush Site Audit | SEO監査、競合調査、サイト改善 | 技術的SEO課題の検出、定期監査、レポート機能 |
| Web Scraper | Chrome上での簡易スクレイピング | ブラウザ拡張、Sitemap形式の設定、クラウド版あり |
| TOWA | Webサイト更新チェック、定点観測 | 更新検知やWebデータ収集を支援する国内サービス |
| Scrapy | 開発者向けの大規模クローリング | Python製オープンソース、拡張性が高い |
| Lumar | 大規模サイトのSEO・サイト品質管理 | サイト健全性、SEO、アクセシビリティなどを統合管理 |
| PigData | スクレイピング代行、データ収集支援 | 要件に応じたデータ収集・分析支援 |
| ShtockData | セルフサービス型または代行型のWebデータ収集 | 国内向けWebスクレイピング&Webクローリングサービス |
Webクローラーツール・サービスおすすめ9選
1. Octoparse
Octoparseは、ノーコードでWebデータを収集できるWebクローラーツールです。公式サイトでも、Webページを構造化データに変換するノーコードソリューションとして紹介されており、動的サイト、ページネーション、無限スクロール、ログイン操作などにも対応しやすい点が特徴です。
テンプレートを使えば、対象サイトや取得項目を一から設定しなくても、よく使われるデータ収集タスクを短時間で始められます。Webクローリングの経験がない担当者でも、クリック操作で抽出範囲を指定できるため、営業、マーケティング、リサーチ部門での利用に向いています。
- ノーコードでクローラー web作成を始めたい企業に向いている
- EC、求人、SNS、ニュースなどのテンプレートを活用できる
- クラウド実行やスケジュール実行により、定期的なクローリングが可能
- CSV、Excel、データベースなどへの出力に対応
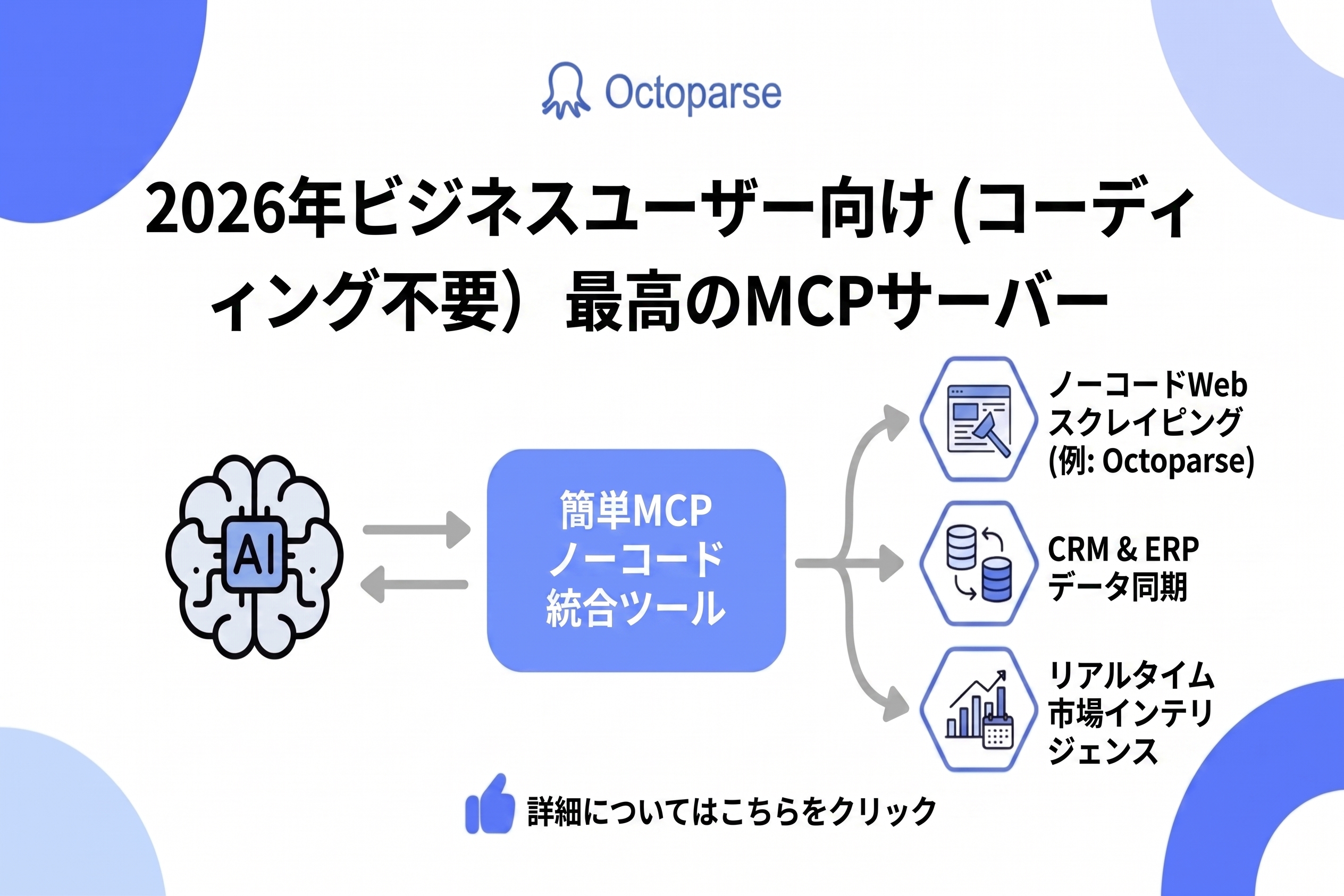
Octoparseで実現する「クローラー × AI大規模言語モデル」連携
近年は、Webクローラーで取得したデータをAI大規模言語モデル(LLM)に渡し、調査、要約、分類、営業リスト作成、価格変動の分析まで自動化するニーズが高まっています。LLMは文章の理解や推論が得意ですが、リアルタイムのWebデータを自分だけで安定的に取得することは得意ではありません。そこで、クローラーをAIの「外部データ取得手段」として接続する発想が重要になります。
Octoparseでは、従来のデスクトップ型Webクローラーに加えて、MCP Server、Open API、CLI、そしてそれらをまとめたAI Open Platformが用意されています。これにより、自然言語でWebデータを取得したり、AIエージェントやCIパイプラインにクローリング処理を組み込んだりできます。
| 連携方法 | 向いている使い方 | Octoparseでできること |
|---|---|---|
| MCP Server | ChatGPT、Claude、CursorなどのAIアシスタントからWebデータを取得したい場合 | 自然言語で必要なデータを指示し、テンプレートやタスクを通じて構造化データを取得 |
| Open API | 自社アプリ、SaaS、社内システムにWebデータ取得を組み込みたい場合 | REST形式でクローリングタスクや抽出結果を扱い、プロダクトやデータ基盤と連携 |
| CLI | ターミナル、cron、GitHub Actions、Docker、Airflowなどから実行したい場合 | octoparse runのようなコマンドで定期取得やCI連携を実行 |
| AI Open Platform | MCP、API、CLIを用途に応じて使い分けたい場合 | AIユーザー、開発者、データチームが同じWebデータ基盤を共有 |
例えば、営業チームなら「指定エリアの企業名、Webサイト、メールアドレスを収集し、業種ごとに分類して」とAIに依頼し、Octoparse MCP経由でWebデータを取得できます。データチームならCLIで毎朝の競合価格データ取得を自動化し、分析基盤へ連携できます。開発チームならOpen APIを使い、自社サービス内でユーザーが指定したWebデータを取得する機能を実装できます。
つまり、これからのweb クローリングは「データを集めるだけ」ではなく、AIが判断・分析・次のアクションを行うためのリアルタイムデータ基盤として使われます。クローラー webツールを選ぶ際は、ノーコード操作だけでなく、MCP、API、CLIのようなAI連携・自動化の入口があるかも確認するとよいでしょう。
2. Screaming Frog SEO Spider
Screaming Frog SEO Spiderは、SEO監査に特化したWebクローラーです。公式ページでは、Windows、macOS、Linuxに対応したサイトクローラーとして紹介されており、無料版では500 URLまでクロールできます。サイト内のリンク、リダイレクト、404エラー、メタ情報、重複コンテンツ、robots.txt、XMLサイトマップなどを確認できます。
SEO担当者がサイト クローリングを行い、技術的な問題を洗い出す用途に適しています。JavaScriptレンダリングやXPath・CSS Path・正規表現によるカスタム抽出にも対応しているため、SEO監査とデータ抽出を組み合わせたい場合にも便利です。
- SEO監査向けのWebクローラーとして使いやすい
- 無料版で小規模サイトの確認を始められる
- JavaScriptサイトのクローリングやカスタム抽出に対応
- Google Analytics、Search Console、PageSpeed Insightsとの連携が可能
3. Semrush Site Audit
Semrushは、SEO、競合調査、広告、コンテンツマーケティングなどを統合的に支援するマーケティングプラットフォームです。Site Audit機能では、Webサイトをクロールして技術的SEOの問題を検出し、優先度別に改善項目を確認できます。
単体のクローラーというより、SEO施策全体の中でクローリング結果を活用したい場合に向いています。サイトの健全性、クロール可能性、内部リンク、HTTPS、国際SEOなど、マーケティング視点で改善施策を管理したいチームに適しています。
- SEO施策とサイト クローリングをまとめて管理したい場合に便利
- 技術的SEOのエラー、警告、通知を優先度別に確認できる
- 定期的なサイト監査レポートに対応
- 競合調査やキーワード分析など、周辺機能も豊富
4. Web Scraper

引用:Web Scraper
Web Scraperは、Chromeブラウザ上で利用できるWebスクレイピングツールです。Sitemapという設定単位でページ遷移やデータ抽出ルールを定義し、ページ内のテキスト、リンク、表などを取得できます。Webクローリングを軽く試したい初心者にも扱いやすいツールです。
ブラウザ拡張だけで始められる一方、大規模なサイト クローリングや複雑なログイン処理、継続運用には工夫が必要です。小規模なデータ収集や検証用途から始めたい場合に向いています。
- Chrome上で使えるため導入しやすい
- ページ遷移と抽出項目をSitemapとして設定できる
- 小規模なWebデータ収集や検証に向いている
- クラウド版を使えばブラウザ外での実行も可能
5. TOWA

引用:TOWA
TOWAは、Webサイトの更新チェックやデータ収集を支援する国内サービスです。特定ページの変化を継続的に把握したい場合や、価格、在庫、ニュース、告知ページなどの更新を監視したい場合に活用できます。
一般的なWebクローラーのように大量ページを自由に巡回するというより、継続監視や更新検知の用途で検討しやすいサービスです。社内でクローラーを構築せず、運用負荷を抑えたい場合に候補になります。
- Webサイト更新チェックや定点観測に向いている
- 競合サイトや取引先ページの変更確認に活用できる
- 国内サービスとして相談しやすい
- 継続的なWebデータ監視に適している
6. Scrapy

引用:Scrapy
Scrapyは、Pythonで開発されたオープンソースのWebスクレイピング・クローリングフレームワークです。開発者が独自のクローラーを構築し、大量のページを効率的に巡回・抽出したい場合に適しています。
ノーコードツールでは対応しきれない複雑な条件、API連携、データ加工、独自のパイプライン処理などを実装できます。一方で、PythonやHTML、HTTP、データ保存に関する知識が必要です。
- 開発者向けの柔軟なWebクローリングに向いている
- Pythonで抽出ルールや処理フローを細かく実装できる
- 大規模データ収集や独自システム連携に対応しやすい
- 運用には開発・保守体制が必要
7. Lumar
引用:Lumar
Lumarは、Webサイトの健全性、SEO、AI検索、サイトスピード、アクセシビリティなどを統合的に管理するWebサイト最適化プラットフォームです。大規模サイトの技術的な課題を継続的に把握し、改善施策につなげたい企業に向いています。
一般的なデータ抽出ツールというより、サイト全体を継続的にクローリングし、品質管理やSEO改善に活用するツールです。大規模サイト、複数ブランド、グローバルサイトを運営するチームに適しています。
- 大規模サイトの技術的SEOとサイト品質管理に向いている
- 継続的なサイト監視とレポートに対応
- SEOだけでなくアクセシビリティやパフォーマンスも確認しやすい
- エンタープライズ向けのWebクローラー活用に適している
8. PigData(スクレイピング代行サービス)

PigDataのスクレイピング代行サービスは、Webデータ収集を外部に委託したい企業向けのサービスです。クローラーの設計、取得先サイトの確認、データ整形、継続運用などを自社で行うリソースが不足している場合に検討できます。
ツールを自社で運用する場合は、設定変更、エラー対応、サイト構造変更への追従が必要です。代行サービスを利用すれば、技術的な運用負荷を抑えつつ、必要なデータを継続的に取得しやすくなります。
- 自社でクローラーを作る人員が不足している場合に向いている
- 市場調査、競合調査、価格調査などに活用しやすい
- データ取得から整形まで相談できる
- 法的リスクや運用面も含めて確認しながら進めやすい
9. ShtockData

引用:ShtockData
ShtockDataは、キーウォーカーが提供するWebスクレイピング&Webクローリングサービスです。公式サイトでは、セルフサービス型のShtockDataと、代行型のShtockData Proという2つのソリューションが紹介されています。
自社で管理画面からデータ収集を設定したい場合と、設定から保守運用まで任せたい場合の両方に対応しやすい点が特徴です。国内向けのサポートを重視する企業や、大量のWebデータを定期的に取得したい企業に向いています。
- セルフサービス型と代行型を選びやすい
- 国内向けのWebクローリングサービスを探している企業に向いている
- CSV、XML、JSONなどの形式でデータを扱いやすい
- 定期収集や大規模データ収集の相談が可能
目的別:どのWebクローラーを選ぶべきか
| 目的 | おすすめ候補 | 理由 |
|---|---|---|
| ノーコードでデータ収集を始めたい | Octoparse、Web Scraper、ShtockData | 非エンジニアでも設定しやすい |
| AI大規模言語モデルと連携したい | Octoparse MCP、Open API、CLI | ChatGPT、Claude、Cursor、CI、社内アプリなどにWebデータ取得を組み込める |
| SEO目的でサイト全体を調査したい | Screaming Frog、Semrush、Lumar | サイト クローリングとSEO監査に強い |
| 開発者が自由にクローラーを作りたい | Scrapy、Octoparse Open API | PythonやREST APIで柔軟に実装できる |
| 社内運用せず外部に任せたい | PigData、ShtockData Pro | 設計・保守・納品まで相談しやすい |
| Webサイト更新を継続監視したい | TOWA、Octoparse、ShtockData | 定期実行や更新チェックに活用しやすい |
Webクローラー導入時の注意点
robots.txtと利用規約を確認する
Webクローラーを使う前に、対象サイトのrobots.txt、利用規約、API提供有無を確認しましょう。Google Search Centralでもrobots.txtはクローラーにアクセス可能なURLを伝える仕組みとして説明されています。robots.txtですべてが法的に決まるわけではありませんが、クローリング時の重要な確認項目です。
アクセス頻度を抑え、サーバー負荷に配慮する
短時間に大量アクセスを行うと、対象サイトに負荷をかけたり、アクセス制限を受けたりする可能性があります。クロール間隔、同時実行数、取得ページ数を調整し、必要以上にリクエストを送らない設計にしましょう。
個人情報や著作権に注意する
公開ページに掲載されている情報でも、個人情報、著作物、会員限定コンテンツ、商用利用が制限されているデータを扱う場合は慎重な確認が必要です。業務利用する場合は、法務担当者や専門家に確認してからクローリングを実施しましょう。
データ品質とメンテナンスを前提にする
WebサイトのHTML構造は変更されるため、一度作ったクローラーが永続的に動くとは限りません。取得失敗、項目ずれ、重複、文字化け、欠損値を検知できるようにし、定期的にメンテナンスする体制を作ることが重要です。
Webクローラーに関するよくある質問
webクローラーとウェブクローラーは同じ意味ですか?
はい。表記が違うだけで、基本的には同じ意味です。この記事では主に「Webクローラー」と表記していますが、「webクローラー」「ウェブクローラー」「web クローラー」と検索されることもあります。
クローラー webと検索した場合、どんなツールを選べばよいですか?
目的によって選ぶツールは変わります。データ抽出が目的ならOctoparseやWeb Scraper、SEO監査ならScreaming FrogやSemrush、大規模な独自開発ならScrapy、外部委託ならPigDataやShtockDataが候補になります。
web クローリングは違法ですか?
Webクローリング自体が常に違法というわけではありません。ただし、対象サイトの利用規約、robots.txt、著作権、個人情報、アクセス負荷、ログインが必要なページの扱いには注意が必要です。商用利用する場合は事前確認をおすすめします。
サイト クローリングとSEO監査の違いは何ですか?
サイト クローリングは、Webサイト内のページやリンクを巡回する処理です。SEO監査では、そのクローリング結果を使って、404エラー、リダイレクト、タイトル、メタディスクリプション、内部リンク、インデックス可否などを確認します。
プログラミング不要のWebクローラーはありますか?
あります。Octoparse、Web Scraper、ShtockDataなどは、ノーコードまたは管理画面ベースで使いやすい候補です。一方、より自由な処理や大規模な自動化が必要な場合は、Scrapyのような開発者向けフレームワークも検討するとよいでしょう。
WebクローラーはAI大規模言語モデルと連携できますか?
はい。MCP、Open API、CLIのような入口を使えば、Webクローラーで取得したリアルタイムデータをAIエージェントや社内システムに渡せます。Octoparseの場合、MCP ServerでChatGPTやClaudeなどから自然言語でWebデータを取得し、Open APIで自社プロダクトに組み込み、CLIでcronやCIパイプラインから定期実行する、といった使い分けが可能です。
まとめ
Webクローラーは、Webサイトを自動で巡回し、必要な情報を収集するための仕組みです。クローリングをうまく活用すれば、競合分析、価格調査、営業リスト作成、SEO監査、サイト更新チェックなど、多くの業務を効率化できます。
ノーコードで始めたい場合はOctoparseやWeb Scraper、SEO目的のサイト クローリングにはScreaming FrogやSemrush、大規模な独自開発にはScrapy、運用を任せたい場合はPigDataやShtockDataなど、目的に合わせて選ぶことが大切です。
ただし、クローラーは便利な反面、対象サイトへの負荷、利用規約、個人情報、データ品質管理にも注意が必要です。導入前に目的と運用ルールを明確にし、安全で継続しやすいWebクローリング体制を整えましょう。

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール