Webサイトの情報をスプレッドシートにまとめたいけど、毎回コピー&ペーストするのは正直しんどい——そんな経験はありませんか?
実は、GoogleスプレッドシートにはWebページからデータを自動で取得できる関数が最初から備わっています。さらに、GAS(Google Apps Script)やノーコードのスクレイピングツールを組み合わせれば、プログラミング未経験者でもWebデータの自動収集が可能です。
本記事では、スプレッドシートでスクレイピングする3つの方法を、初心者にもわかりやすくステップ形式で解説します。それぞれのメリット・デメリット、そして「結局どの方法を選べばいいの?」という疑問にも正直にお答えします。
スプレッドシートでスクレイピングはできる?
結論から言うと、Googleスプレッドシートだけでも基本的なWebスクレイピングは可能です。
Googleスプレッドシートには、IMPORTXML関数やIMPORTHTML関数といったWeb上のデータを直接セルに取り込める組み込み関数が用意されています。これらの関数を使えば、プログラミングの知識がなくても、URLとちょっとした指定を入力するだけでWebページの情報をスプレッドシートに自動で表示できます。
ただし、スプレッドシートの関数だけでは対応しきれないケースもあります。
スプレッドシート関数で取得できるデータ
スプレッドシートのスクレイピング関数が得意とするのは、HTMLで静的に記述されたデータです。具体的には以下のようなケースです。
- Webページ上のテーブル(表形式)データ
- ニュースサイトやブログのタイトル・見出し一覧
- 商品ページの価格や在庫状況(静的に表示されるもの)
- XMLサイトマップやRSSフィードの情報
- meta情報(description、OGPタグなど)
スプレッドシート関数だけでは取得しにくいデータ
以下のようなケースでは、スプレッドシートの関数だけでは対応できず、GASやノーコードツールの活用が必要になります。
- JavaScriptで動的に生成されるコンテンツ(SPAサイト、無限スクロールなど)
- ログインが必要なページの情報
- 画像ファイルそのものやPDF内のテキスト
- ページネーション(複数ページ)にまたがるデータの一括取得
- APIで配信されるJSONデータ
こうした制限を理解したうえで、まずは関数から始めて、必要に応じてGASやノーコードツールにステップアップするのがおすすめです。
Webスクレイピングとは?初心者向けにやさしく解説
Webスクレイピングとは、Webサイトから必要な情報を自動的に抽出する技術のことです。
たとえば、ECサイトで100商品の価格を調べたいとき、ひとつずつ手作業でコピー&ペーストしていたら何時間もかかります。スクレイピングを使えば、この作業を数分〜数十分に短縮できます。
Webスクレイピングの方法は大きく分けて3つあります。
①プログラミング(Python・Ruby等) — 最も柔軟だが、コーディングスキルが必要。BeautifulSoupやSeleniumなどのライブラリを使用。
②スプレッドシートの関数 — プログラミング不要で最も手軽。ただし、取得できるデータの範囲に制限がある。
③ノーコードのスクレイピングツール — プログラミング不要で、関数より高機能。Octoparseのようなツールを使えば、動的サイトやページネーションにも対応可能。
本記事では、②と③を中心に、スプレッドシートを活用したスクレイピングの実践的な方法を紹介していきます。
【方法①】IMPORTXML関数でWebデータを自動取得する
スプレッドシートでスクレイピングする際に、最も汎用性が高いのがIMPORTXML関数です。XPathという「住所」のような指定方法を使い、Webページ内の好きな要素をピンポイントで抽出できます。
IMPORTXML関数の基本構文
IMPORTXML関数の書き方はシンプルです。
- URL — データを取得したいWebページのアドレス
- XPathクエリ — ページ内のどの要素を取得するかを指定するパス
たとえば、あるWebページのすべてのh2見出しを取得したい場合:
XPathの取得方法(3ステップ)
「XPathなんて書けない…」と不安に思う方もいるかもしれませんが、心配いりません。ブラウザの機能を使えば、コピー&ペーストだけでXPathを取得できます。
ステップ1: Chromeブラウザでスクレイピングしたいページを開き、取得したい要素を右クリック → 「検証」を選択。
ステップ2: デベロッパーツールが開いたら、対象の要素がハイライトされます。ハイライトされた部分を右クリック → 「Copy」 → 「Copy XPath」を選択。
ステップ3: コピーしたXPathをスプレッドシートのIMPORTXML関数に貼り付けて完了。
実践例:ブログ記事のタイトルを取得
たとえば、Octoparseブログのトップページからすべてのブログタイトルを取得する場合:
ステップ1: A1セルに対象のURLを入力する。
ステップ2: B1セルにIMPORTXML関数を入力する。
関数が正常に動作すれば、ページ内のh2テキストがB列に自動展開されます。
IMPORTXML関数でよくあるエラーと対処法
スプレッドシートでIMPORTXML関数を使ったスクレイピングでは、以下のエラーに遭遇することがあります。
「リソースを読み込めません」エラー 対象サイトがスクレイピングをブロックしている可能性があります。robots.txtでアクセスが制限されていないか確認しましょう。
「インポートしたコンテンツは空です」エラー XPathの指定が正しくないか、JavaScriptで動的に生成されるコンテンツを指定している可能性があります。XPathを再確認するか、別の要素を試してみてください。
XPath内のダブルクォーテーション問題 XPathに"が含まれる場合、スプレッドシートの関数内では""のように二重にする必要があります。
データが更新されないIMPORTXML関数は約1時間ごとに自動更新されます。手動で更新したい場合は、URLの末尾にランダムなパラメータを追加する方法が有効です。
【方法②】IMPORTHTML関数でテーブルやリストを丸ごと取得する
Webページにテーブル(表)やリスト形式のデータがある場合、IMPORTHTML関数を使えば、構造を維持したままスプレッドシートに取り込めます。
IMPORTHTML関数の基本構文
- URL — データ取得対象のWebページ
- table / list — テーブルを取得するか、リストを取得するか
- インデックス番号 — ページ内で何番目のテーブル(またはリスト)を取得するか
実践例:Webページの表データを取得
たとえば、Wikipediaの表データを取り込みたい場合:
この1行で、ページ内の最初のテーブルがスプレッドシートに丸ごと展開されます。列の並びもそのまま維持されるため、取得後の整形作業がほとんど不要です。
IMPORTXMLとIMPORTHTMLの使い分け
「どっちを使えばいいの?」と迷ったら、以下の基準で判断してください。
IMPORTHTML関数が向いているケース:
- Webページ上にテーブルやリストとして表示されているデータ
- 列構造をそのまま保持したい場合
- XPathの知識がなくても使いたい場合
IMPORTXML関数が向いているケース:
- テーブル以外の任意の要素(見出し、リンク、画像URLなど)を取得したい
- 特定のclass名やIDを持つ要素だけを抽出したい
- より細かい制御が必要な場合
スプレッドシート関数スクレイピングの制限事項
IMPORTXML関数・IMPORTHTML関数を使ったスクレイピングには、いくつかの制限があります。
同時利用の上限: 1つのスプレッドシート内で使用できるIMPORT系関数は、おおよそ50個までです。これを超えるとエラーが発生しやすくなります。
更新頻度の制限: データは約1時間ごとに自動更新されます。リアルタイムなデータ取得には向いていません。
動的コンテンツ非対応: JavaScriptで後から読み込まれるデータは、関数では取得できません。
認証ページ非対応: ログインが必要なページのデータは取得できません。
これらの制限に引っかかった場合は、次に紹介するGASやノーコードツールの活用を検討しましょう。
【方法③】GAS(Google Apps Script)で柔軟にスクレイピングする
IMPORTXML関数では対応しきれない場面で活躍するのが、GAS(Google Apps Script)です。GASはGoogleが提供するスクリプト環境で、スプレッドシートと直接連携しながら、より柔軟なWebスクレイピングが実現できます。
GASスクレイピングのメリット
- 無料で利用可能(Googleアカウントがあれば OK)
- スプレッドシートに直接データを書き込み可能
- トリガー機能で定期実行(毎時、毎日など)を自動化
- 正規表現やHTMLパーサーで柔軟なデータ抽出
- 関数よりエラーハンドリングがしやすい
GASエディタの開き方
ステップ1: Googleスプレッドシートを開く。
ステップ2: メニューバーの「拡張機能」→「Apps Script」をクリック。
ステップ3: GASエディタが新しいタブで開きます。デフォルトのmyFunction()を削除して、コードを記述しましょう。
基本的なスクレイピングコード
以下は、指定したWebページのタイトルを取得してスプレッドシートに書き込む基本的なGASコードです。

このコードを「実行」ボタンで実行すると、A1セルにページタイトルが入力されます。
定期実行(トリガー)の設定方法
GASの大きな強みは、トリガー機能で自動実行をスケジュールできる点です。
ステップ1: GASエディタ左側のメニューから「トリガー」(時計アイコン)をクリック。
ステップ2: 「トリガーを追加」ボタンをクリック。
ステップ3: 以下を設定して保存:
- 実行する関数を選択 →
scrapeTitle - イベントのソース → 「時間主導型」
- 時間ベースのトリガータイプ → 「日付ベースのタイマー」
- 時刻を選択 → お好みの時間帯
これで、毎日自動的にWebデータがスプレッドシートに取得されるようになります。
GASスクレイピングの注意点
GASには1回の実行時間が6分までという制限があります。大量のページをスクレイピングする場合は、処理を分割するか、次に紹介するノーコードツールの利用を検討してください。
また、GASの無料版では1日あたりの実行時間が合計90分に制限されています。頻繁な定期実行を設定する場合は、この制限を意識する必要があります。
【方法④】ノーコードツールで手軽にスクレイピングする
「関数だとデータが取れない」「GASのコードを書くのはハードルが高い」——そんな方におすすめなのが、ノーコードのスクレイピングツールです。
ここでは、ノーコードスクレイピングツールのOctoparseを使って、Webデータをスプレッドシート形式で取得する方法を紹介します。
Octoparseとは
Octoparseは、プログラミング不要でWebスクレイピングができるデスクトップアプリケーションです。ポイント&クリック操作でスクレイピングのルールを設定でき、取得したデータはExcelやCSV形式でエクスポートできるため、スプレッドシートとの連携も簡単です。
Octoparseでスクレイピングする手順(4ステップ)
ステップ1:URLを入力してページを開く
Octoparseを起動し、スクレイピングしたいWebページのURLを検索バーに貼り付けます。URLが検出されたら「抽出開始」ボタンをクリックします。
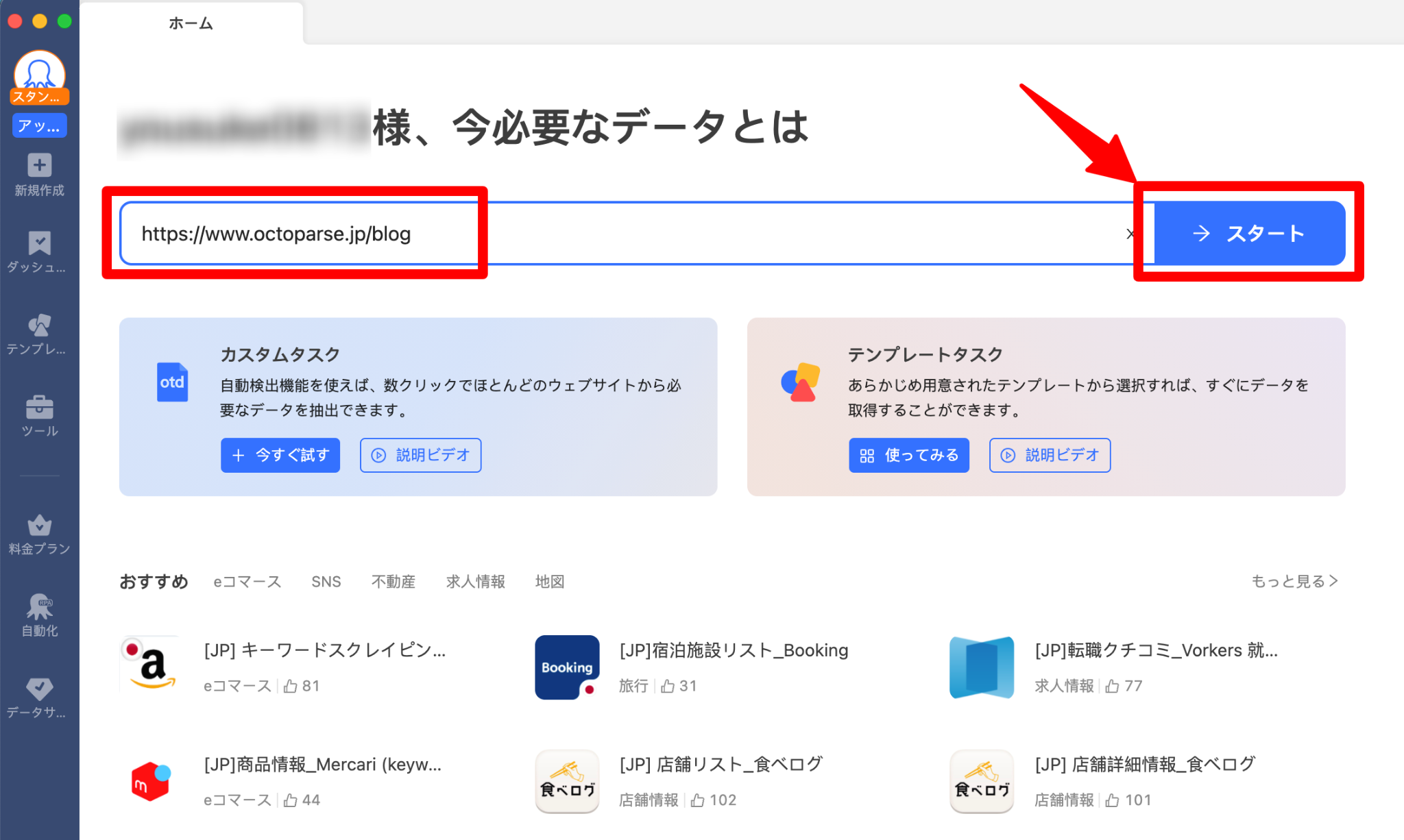
ステップ2: Webページを自動識別する
画面が切り替わったら、操作ヒントパネルから「Webページを自動識別する」をクリックします。Octoparseが自動的にページ構造を解析し、取得すべきデータを検出します。
この自動識別機能が、スプレッドシートの関数やGASとの大きな違いです。XPathやCSSセレクタの知識がなくても、ツールが自動的に最適な抽出ルールを提案してくれます。
自動識別とは、自動的にページ上の必要なデータを検出して識別するという役立つ機能です。ポイント&クリックをする必要はなく、Octoparseは自動的に処理します。
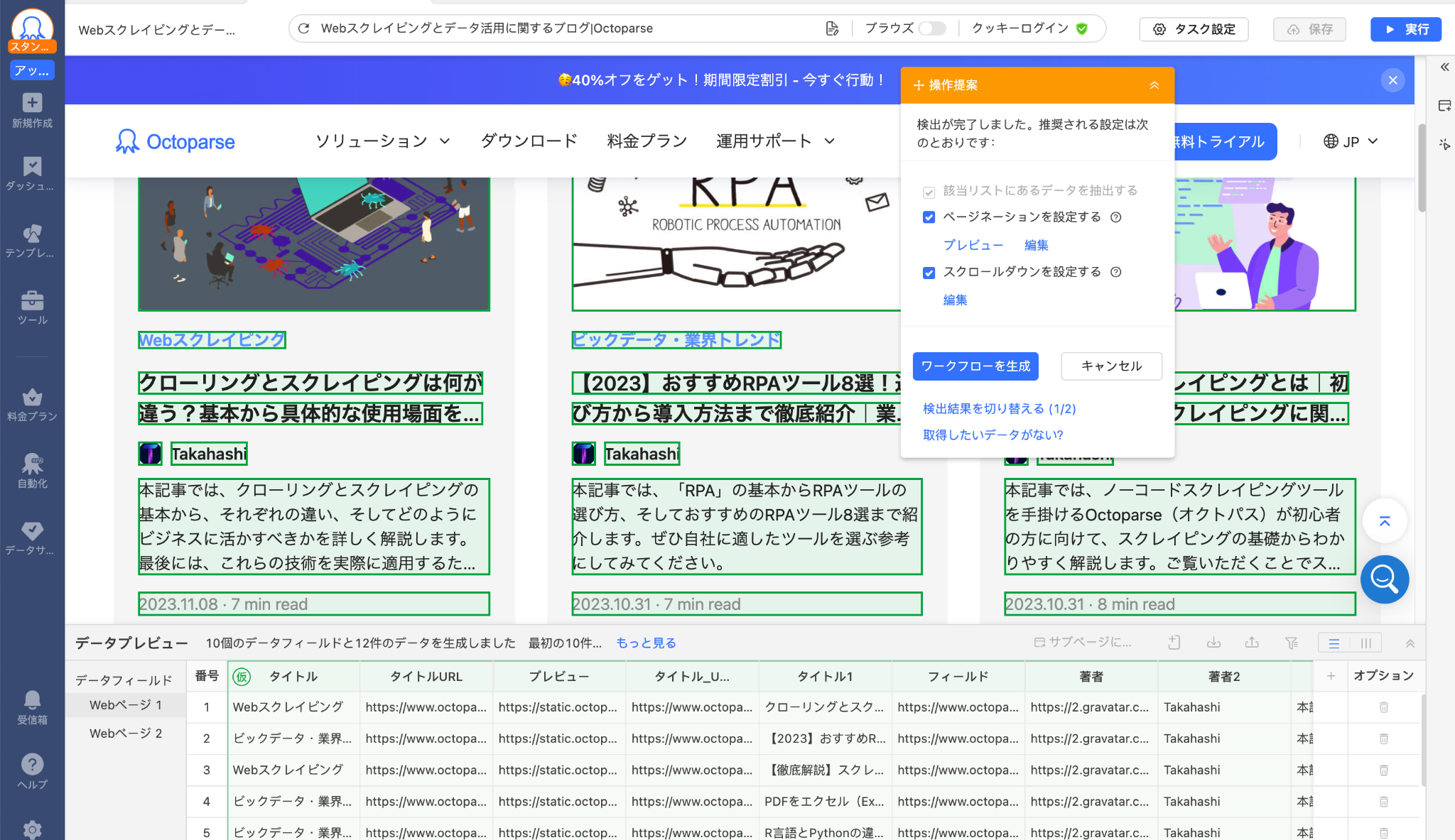
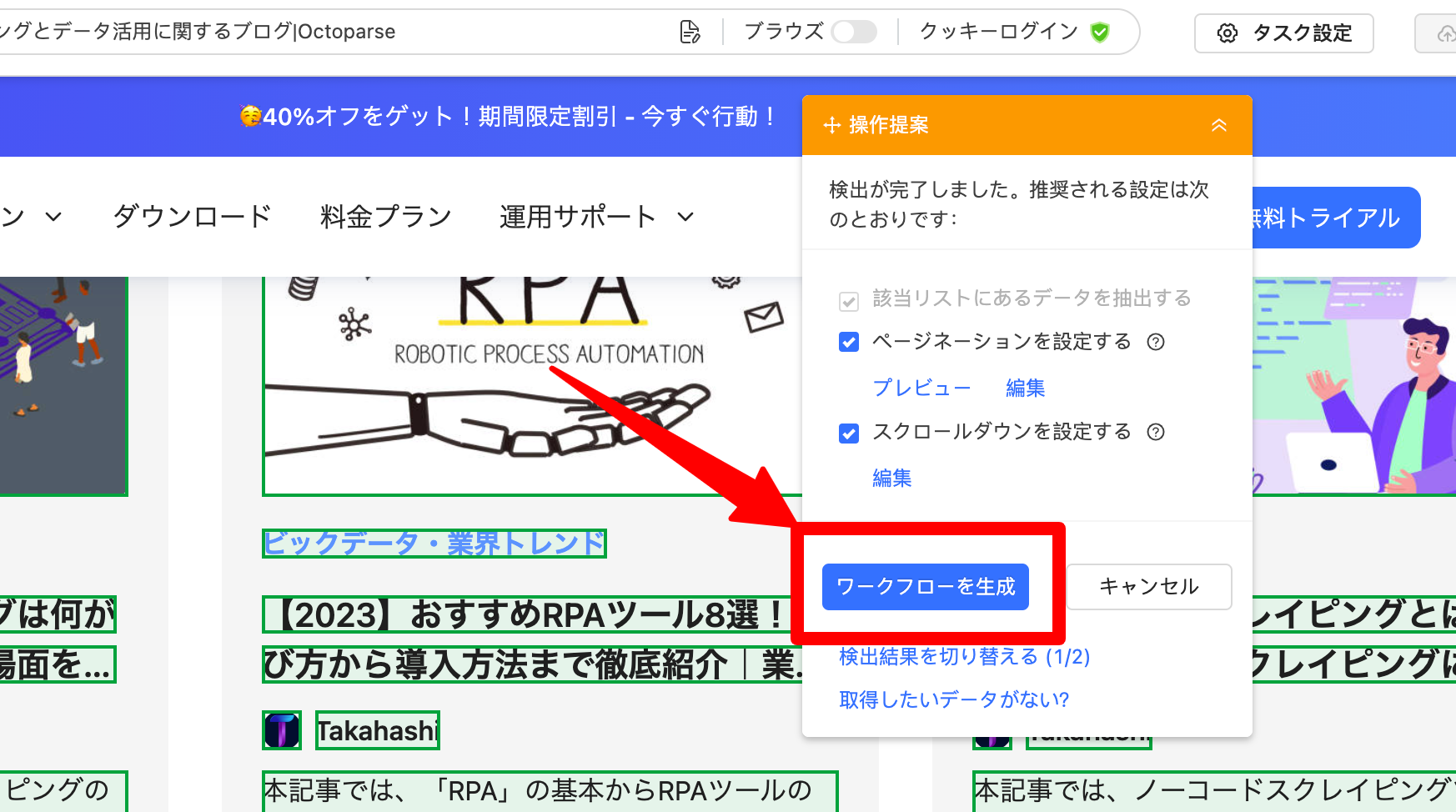
ステップ3:ワークフローを確認して生成
自動識別が完了すると、データプレビューが表示されます。取得されるデータの内容を確認し、問題なければ「ワークフローを生成」をクリックしてタスクを作成します。
ステップ4:タスクを実行してデータをエクスポート
「実行」ボタンをクリックし、「ローカル抽出」または「クラウド抽出」を選択してスクレイピングを実行します。完了後、データをCSVやExcel形式でエクスポートすれば、そのままスプレッドシートに取り込めます。
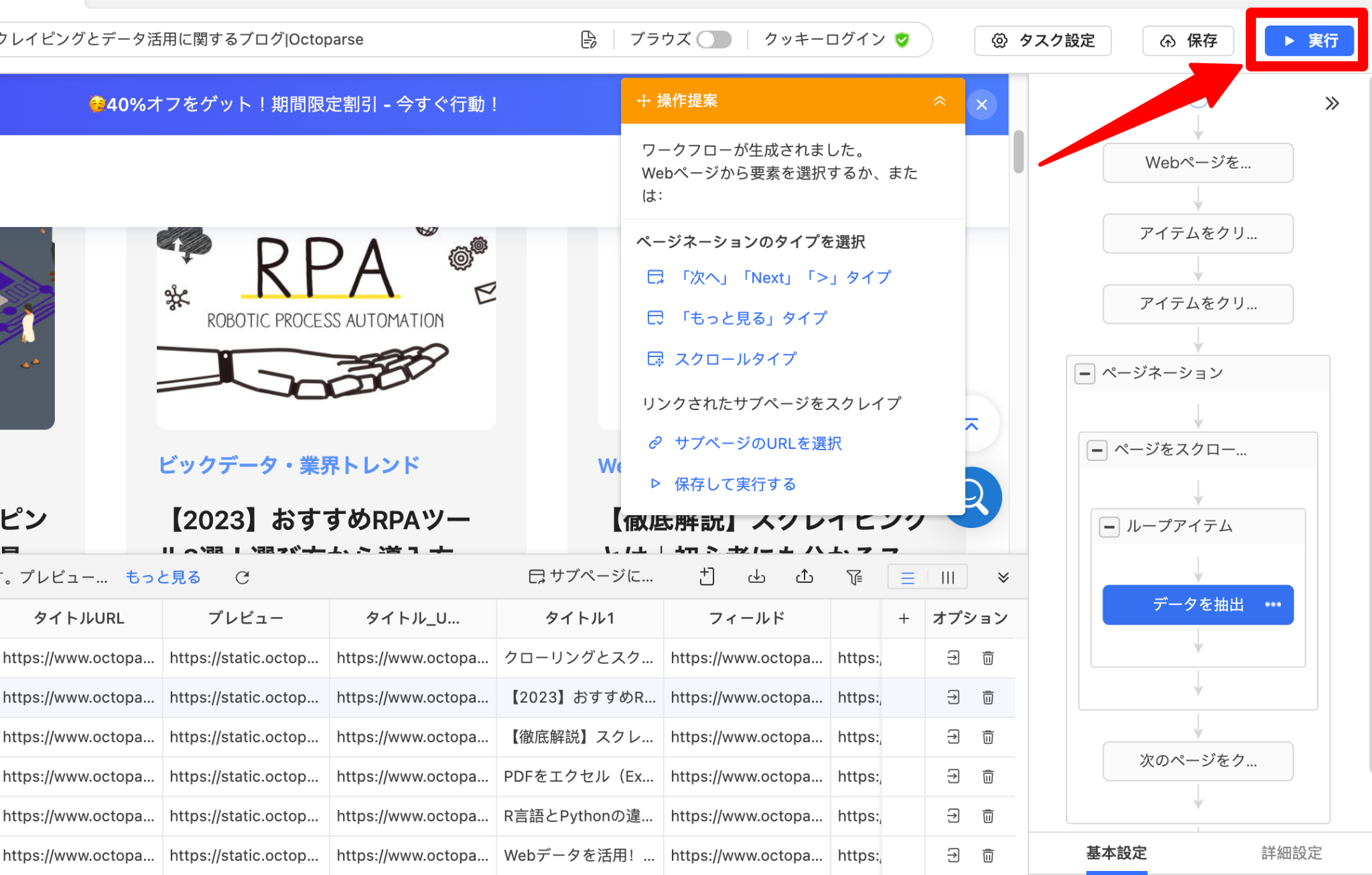
次にタスク実行方法の選択画面が表示されるので、「ローカル抽出」または「クラウド抽出」のどちらかを選択します。クラウド抽出は有料版のみ利用可能です。
いずれかを選択すると、スクレイピング実行中の画面が表示されますので、完了するまでしばらく待ちましょう。
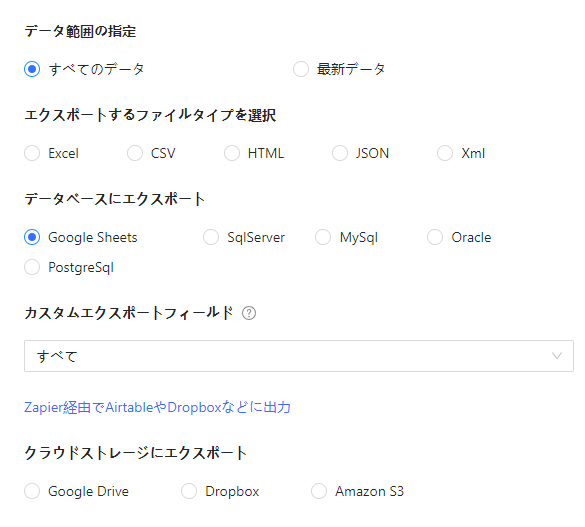
取得したデータは、そのままGoogleスプレッドシートへエクスポートすることが可能です。こちらでは、Google Sheetsへの書き出し方法をご案内します。また、ExcelやCSV形式でのエクスポートにも対応しています。Excelなどをご利用いただければ、抽出後のデータ加工も簡単に行えます。
Octoparseがスプレッドシート関数・GASより優れるポイント
動的サイトに対応: JavaScriptで生成されるコンテンツも取得可能。SPAサイトや無限スクロールにも対応できます。
ページネーション自動処理: 複数ページにまたがるデータも、自動でページ遷移しながら収集。スプレッドシートの関数では実現できない機能です。
スケジュール実行(クラウド): 有料プランでは、クラウド上でスクレイピングを定期実行できます。PCの電源が入っていなくても、データが自動で収集されます。
アンチブロック対策: IPローテーションなどの機能により、スクレイピングがブロックされにくい仕組みが備わっています。
人気テンプレートですぐに始められる
Octoparseでは、よく使われるWebサイト向けにスクレイピングテンプレートが用意されています。テンプレートを選ぶだけで、面倒な設定なしにデータ収集を開始できます。
https://www.octoparse.jp/template/google-search-scraper
https://www.octoparse.jp/template/google-maps-store-listing-scraper
テンプレートを使えば、スプレッドシートにそのままインポートできるCSVファイルが数分で手に入ります。
4つの方法を徹底比較!あなたに合った選び方
ここまで紹介した4つのスクレイピング方法を一覧で比較してみましょう。
| 項目 | IMPORTXML関数 | IMPORTHTML関数 | GAS | ノーコードツール(Octoparse) |
|---|---|---|---|---|
| 難易度 | ★☆☆ | ★☆☆ | ★★☆ | ★☆☆ |
| コスト | 無料 | 無料 | 無料 | 無料プランあり |
| プログラミング | 不要 | 不要 | 必要 | 不要 |
| 動的サイト対応 | ✕ | ✕ | △ | ○ |
| ページネーション | ✕ | ✕ | △ | ○ |
| 定期自動実行 | ✕(1時間自動更新のみ) | ✕ | ○ | ○ |
| 大量データ取得 | ✕(50セル制限) | ✕ | △(6分制限) | ○ |
| データ出力先 | スプレッドシート | スプレッドシート | スプレッドシート | スプレッドシート / CSV / Excel / API |
| 推奨ユースケース | 少量の静的データ | テーブル/リストの取り込み | 中規模の定期収集 | 大規模・複雑な収集 |
用途別のおすすめ
「週に1回、数十件のデータをチェックしたい」 → IMPORTXML関数 or IMPORTHTML関数で十分です。設定も5分で完了。
「毎日の価格データを自動で蓄積していきたい」 → GASのトリガー機能が便利。ただし、コードを書く必要があります。
「コードは書けないが、本格的にデータ収集を自動化したい」 → Octoparseがベストな選択肢。ノーコードでありながら、動的サイト対応やスケジュール実行など、プロ級の機能が使えます。
スプレッドシートでスクレイピングする際の注意点
スプレッドシートを使ったWebスクレイピングは便利ですが、実行前に必ず確認しておくべきポイントがあります。
robots.txtと利用規約を確認する
Webスクレイピングを行う前に、対象サイトのrobots.txtと利用規約を必ず確認しましょう。robots.txtは、サイトが検索エンジンやクローラーに対して「このページはアクセスしないで」と指示するためのファイルです。
確認方法は簡単で、対象サイトのドメインの末尾に/robots.txtを付けてアクセスするだけです(例:https://example.com/robots.txt)。
サーバーに負荷をかけすぎない
短時間に大量のリクエストを送ると、対象サイトのサーバーに過度な負荷をかけてしまいます。これはサービス妨害とみなされる可能性もあるため、リクエストの間隔は最低でも1秒以上空けることが推奨されます。
スプレッドシートの関数はGoogleのサーバーを経由してリクエストを送るため、50個を超えるIMPORT関数を同時に使用する場合は特に注意が必要です。
取得データの利用目的を意識する
スクレイピングで取得したデータの利用にも配慮が必要です。個人的な調査や分析目的であれば問題になるケースは少ないですが、取得データを商用目的で再配布する場合は、著作権法やデータベースの保護に関する法律に抵触する可能性があります。
スクレイピング自体は違法ではありませんが、「何を」「どのように」「何のために」取得するかによって判断が変わります。不安な場合は、対象サイトの運営者に事前確認を取ることをおすすめします。
参考:スクレイピングは違法?Webスクレイピングに関するよくある誤解
よくある質問(FAQ)
Q1. スプレッドシートでスクレイピングは無料でできますか?
はい、Googleスプレッドシートの標準関数(IMPORTXML、IMPORTHTML)は完全に無料で使えます。Googleアカウントさえあれば、追加のソフトウェアやサービス契約は不要です。ただし、関数には同時利用数や動的サイト非対応といった制限があるため、大規模な収集にはOctoparseの無料プランなど、専用ツールを併用するのが効率的です。
Q2. IMPORTXMLとIMPORTHTMLの違いは何ですか?
IMPORTXML関数は、XPathを使って任意の要素を指定して抽出する汎用的な関数です。見出し、リンク、画像URLなど、ページ内のあらゆる要素をターゲットにできます。一方、IMPORTHTML関数はテーブルやリストの取得に特化しており、XPathの知識がなくても簡単に表データを丸ごと取り込めます。
Q3. スプレッドシートのスクレイピングで取得できないデータはありますか?
はい、いくつかの制限があります。JavaScriptで動的に生成されるコンテンツ、ログインが必要なページ、画像やPDFの中のテキストは、スプレッドシートの関数だけでは取得できません。これらのデータを取得するには、GASや、Octoparseのようなノーコードスクレイピングツールの活用が有効です。
Q4. スクレイピングは違法ですか?
スクレイピング自体は違法ではありません。 ただし、対象サイトの利用規約やrobots.txtの指示に従う必要があります。また、取得したデータの利用目的によっては著作権法に抵触する場合もあります。個人的な調査や分析であれば問題になるケースは少ないですが、商用利用の場合は事前に確認を取ることが推奨されます。日本では、総務省が消費者物価指数の算出にスクレイピングを活用しているなど、正当な用途で広く利用されている技術です。
Q5. スプレッドシートのスクレイピングとPythonのスクレイピング、どちらがいいですか?
目的とスキルによって異なります。50件以下の静的データを手軽に取得したいなら、スプレッドシートの関数が最もシンプルです。数百件のデータを定期的に自動収集したいならGASが適しています。数千件以上のデータや動的サイトの処理が必要な場合はPythonが最適です。「プログラミングは書けないけど、大規模な収集がしたい」という方には、Octoparseのようなノーコードツールという選択肢もあります。
まとめ:迷ったらここだけ読めばOK
正直なところ、「スプレッドシートでスクレイピングしたい」と調べ始めた方の多くは、IMPORTXML関数を使ってみて「あれ、思ったより取れないな…」と壁にぶつかるパターンが多いです。
筆者自身も最初はIMPORTXML一択でやっていましたが、JavaScriptで動的に表示されるサイトには歯が立たないし、50個以上のセルに関数を入れるとシートが重くなって実用レベルではなくなりました。
そこで結論をまとめると、こんな感じになります。
「ちょっと試してみたい」レベル → IMPORTXML・IMPORTHTML関数で十分。無料だし5分で始められます。
「定期的にデータを自動収集したい」レベル → GASのトリガー機能を検討。ただしコードを書く必要あり。
「コードは書けないけど本格的にやりたい」レベル → Octoparseの自動識別機能が一番ラクです。設定もほぼ不要。
大事なのは、最初から完璧な方法を選ぼうとしないことです。まずIMPORTXML関数で試してみて、「これじゃ足りないな」と感じたタイミングでステップアップすれば、無駄なく最適な方法にたどり着けます。
スプレッドシートでのWebスクレイピングは、データ収集の第一歩として最適な方法です。ぜひ今日から試してみてください。
Octoparseを無料で試してみる → 無料ダウンロードはこちら




