Webサイト上のデータを表やリストにまとめる際に、手作業でコピー&ペーストをしていませんか。こうした手作業はデータ量が少ないときには最も手軽な方法かもしれません。しかし、データ量が多ければ多いほど、時間と手間が掛かるため非常に面倒な作業になります。
もしプログラミングの知識・技術があれば、Pythonなどを使ったWebスクレイピングで自動抽出できます。しかしプログラミングの知識がない方は、Web上のデータを効率的に取得するには、どうすればよいのでしょうか。
そこで本記事では、誰でも簡単に使えるWebデータの取得方法を2つ紹介します。
- Googleスプレッドシートでデータ入力を自動化する方法
- ノーコードツールでデータをスクレイピングする方
それぞれの手順をわかりやすく解説するので、早速試してみましょう!
Webスクレイピングとは
Webスクレイピングとは、Webサイトから特定の情報を自動的に抽出するコンピュータソフトウェア技術のことです。Webスクレイピングを使えば、インターネット上の特定のWebサイトやデータベースを探り、大量のデータの中から任意のデータだけを自動で抽出できます。
Webスクレイピングを行うためには、PythonやRubyなどのプログラミングによって、スクレイパーの作成が必要です。しかし、未経験からプログラミングを習得するのは容易ではありません。そこで役立つのが、スプレッドシートの関数や、Webスクレイピングツールの活用です。
Googleスプレッドシートとは
Googleスプレッドシートは、Googleが提供するクラウドベースの表計算ツールです。このツールは、Microsoft Excelと同様の多くの機能を提供していますが、主な違いはそのクラウドベースの性質にあります。ここでは、Googleスプレッドシートの主要な特徴と機能をいくつか紹介します。
| クラウドベース | Googleスプレッドシートはインターネット接続があればどこからでもアクセスでき、インストールする必要がありません。これにより、デバイス間での互換性とアクセスの容易さが保証されます。 |
| 共有とコラボレーション | スプレッドシートは簡単に共有でき、複数のユーザーが同時にドキュメントを編集できます。編集者ごとに異なる色で変更箇所が表示され、リアルタイムでのコラボレーションが可能です。 |
| 自動保存とバージョン履歴 | 編集内容は自動的に保存され、以前のバージョンに簡単に戻すことができます。これにより、誤ってデータを失うリスクが軽減されます。 |
| 統合されたGoogleサービス | GoogleスプレッドシートはGoogleドライブに保存され、GoogleフォームやGoogleドキュメントなど他のGoogleアプリケーションと簡単に統合できます。 |
| 拡張性とカスタマイズ | 様々なアドオンやスクリプトを使用して、機能を拡張したりカスタマイズすることが可能です。 |
| フォーマットと関数 | Excelと同様に、さまざまなフォーマットオプション、数式、関数が用意されており、複雑なデータ分析と計算が可能です。 |
IMPORTXML関数とは
IMPORTXML 関数は、Googleスプレッドシートで使用される機能で、XMLやHTMLなどのウェブページから特定のデータをインポートするために使われます。この関数は =IMPORTXML(URL, “XPathクエリ”) の形式で記述され、URLはデータを抽出したいウェブページのアドレス、XPathクエリはそのページ内で特定のデータを指定するためのパスです。
この機能は、ウェブからのデータ抽出や簡易的なウェブスクレイピングに便利で、多様なデータソースに対応しています。ただし、取り込むデータ量やセキュリティの観点から注意が必要です。
XPathとは何か
XPath(XML Path Language)は、XML文書内の特定の部分や情報を検索・選択するための言語です。XML文書の構造を利用して、特定の要素、属性、テキストなどを簡単に特定し、抽出することができます。XPathの表現は、ディレクトリ構造に似たパスの形式で、文書の階層をナビゲートすることで特定のデータにアクセスします。
この言語は、XML文書を操作するための他の技術(例えばXSLTやXQuery)と組み合わせて使用されることが多く、ウェブページから特定の情報を抽出するウェブスクレイピングなどにも利用されます。XPathは、その精確さと柔軟性から、XMLベースのデータを扱う際に広く使用されています。
Googleスプレッドシートでデータ入力を自動化する方法
ここでは、Googleスプレッドシートの「IMPORTXML関数」を活用した、簡単なWebクローラーを構築する手順を紹介します。データの取得先として、データ収集サイト「Octoparseブログ」を利用します。
ステップ1:新しいGoogleスプレッドシートを開きます。
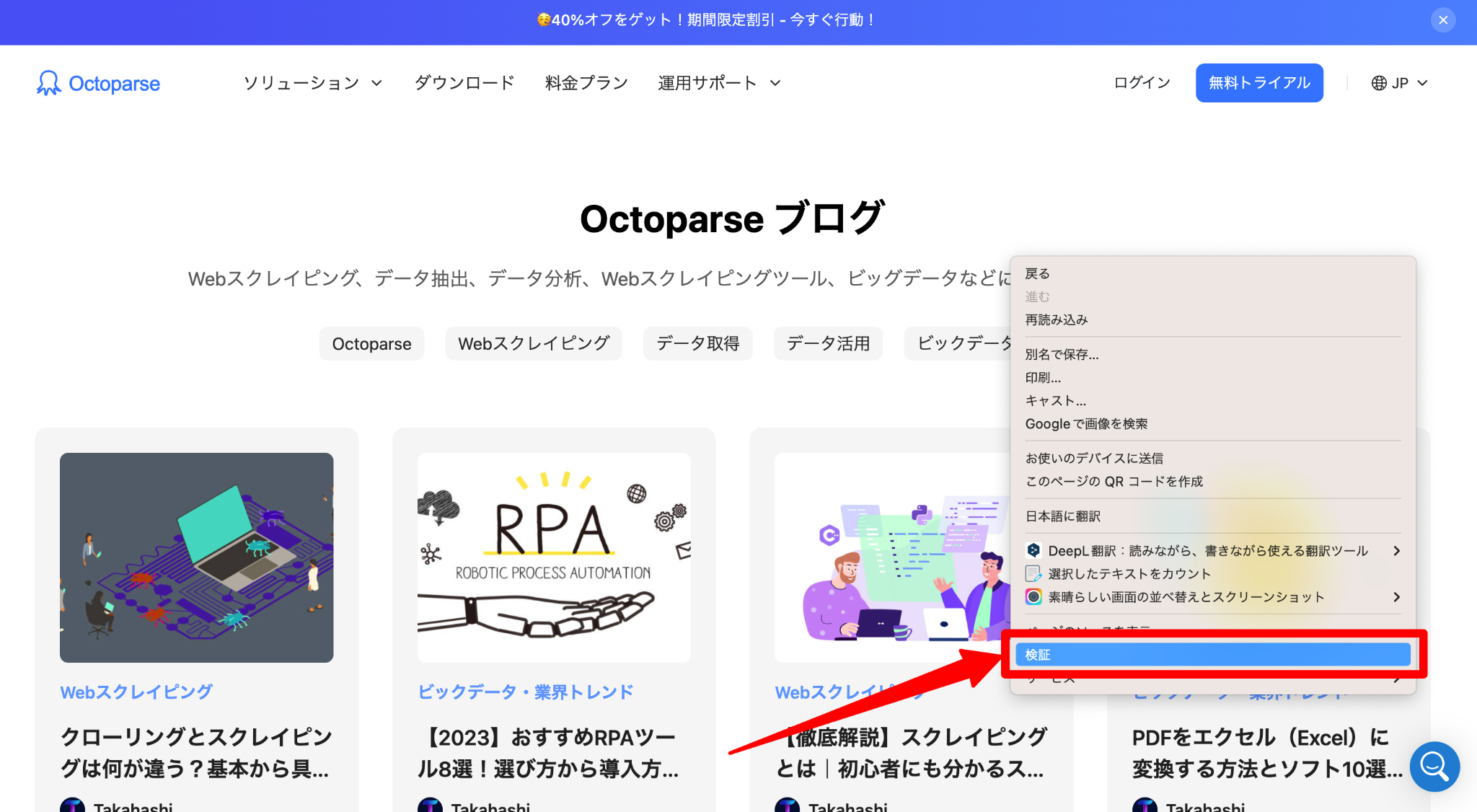
ステップ2:Chromeブラウザで「Octoparseブログ」を開き、ページを右クリックして、メニューの中から「検証」を選択します。
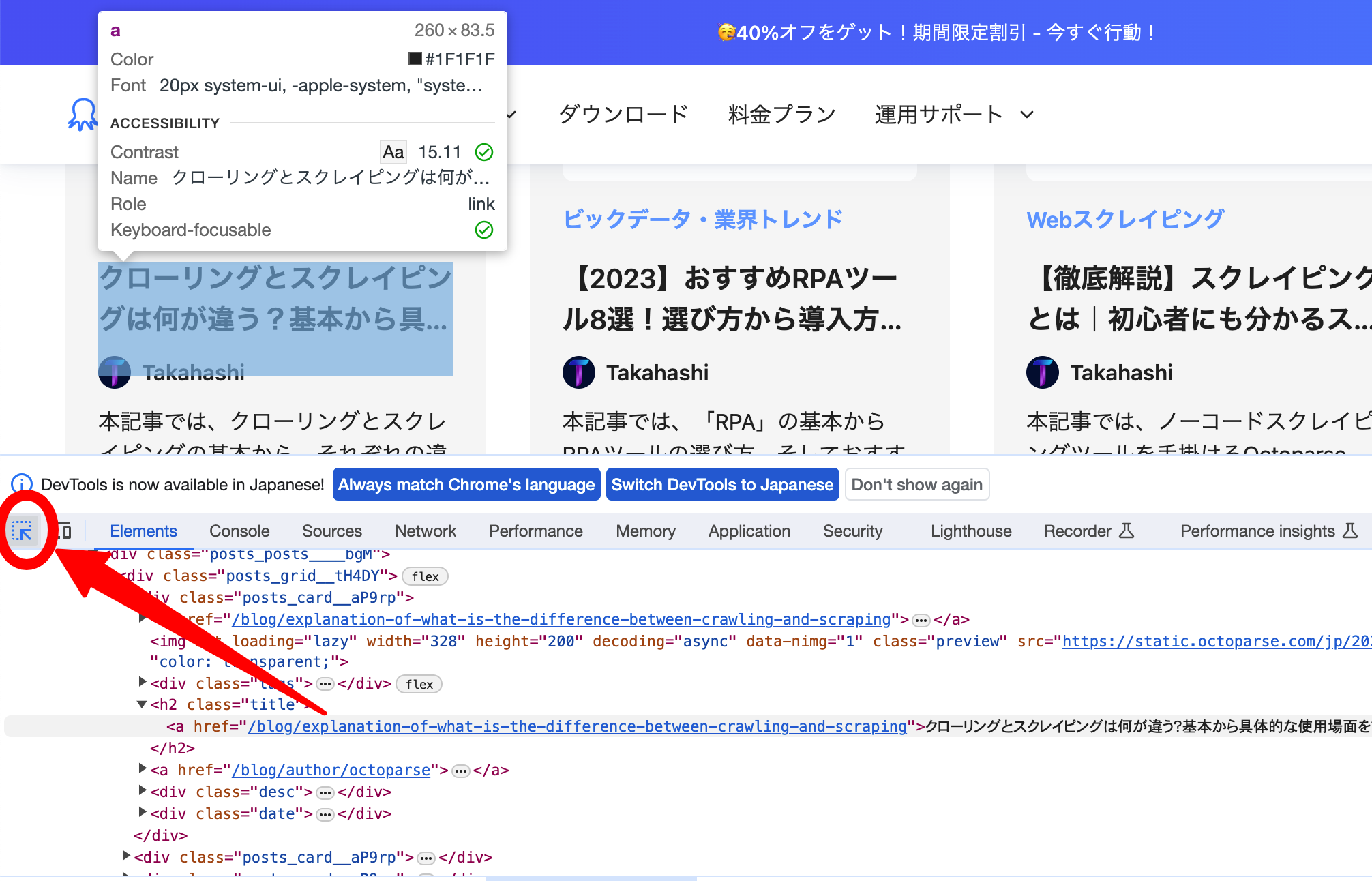
するとソースコードが表示されるので、「矢印アイコン」(画面左下の赤枠)をクリックし、セレクタを有効にします。
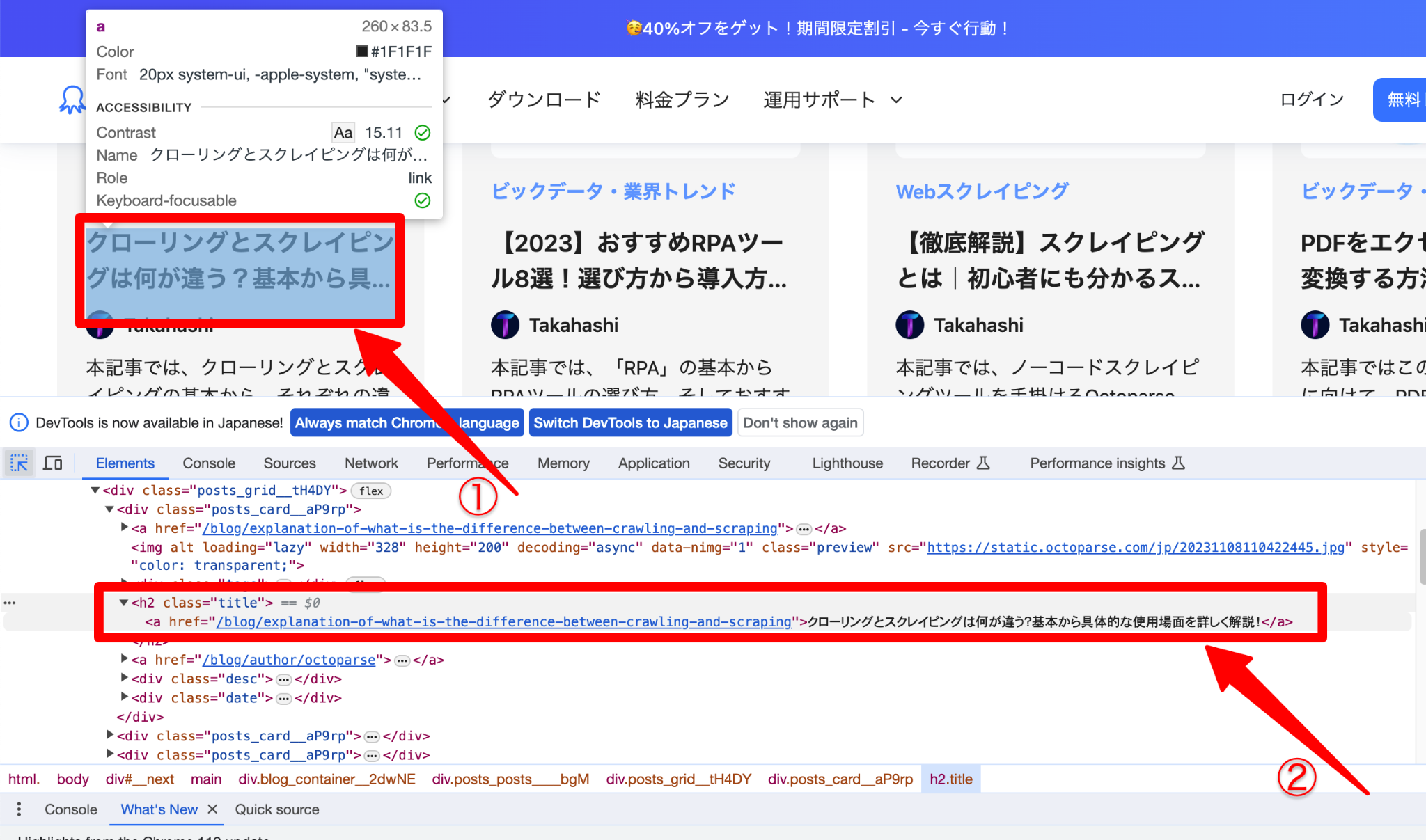
セレクタを有効にした状態で、必要な箇所にカーソルを置くと(①)、対応する情報が「検証パネル」に表示されます(②)。ここでは「タイトル」を選択します。
ステップ3:OctoparseブログのURLをスプレッドシートに貼り付けます。ここではA2セルを指定します。
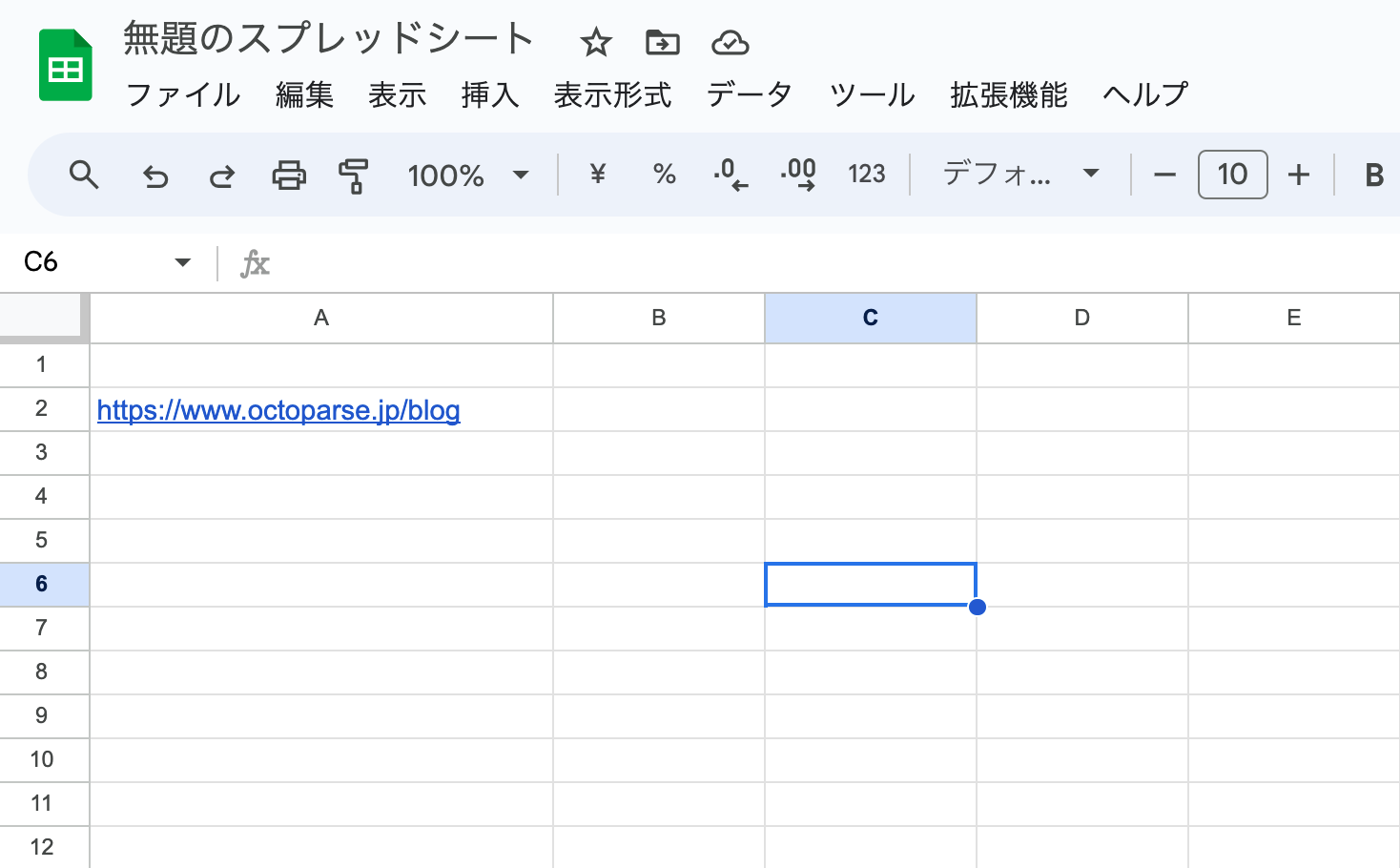
ステップ4:Xpathを取得する
今回は「IMPORTXML関数」を使って、ブログデータを自動で取得します。IMPORTXML関数とは、Webサイトから必要な情報を指定し、その情報をスプレッドシートに自動で出力できる関数のことです。
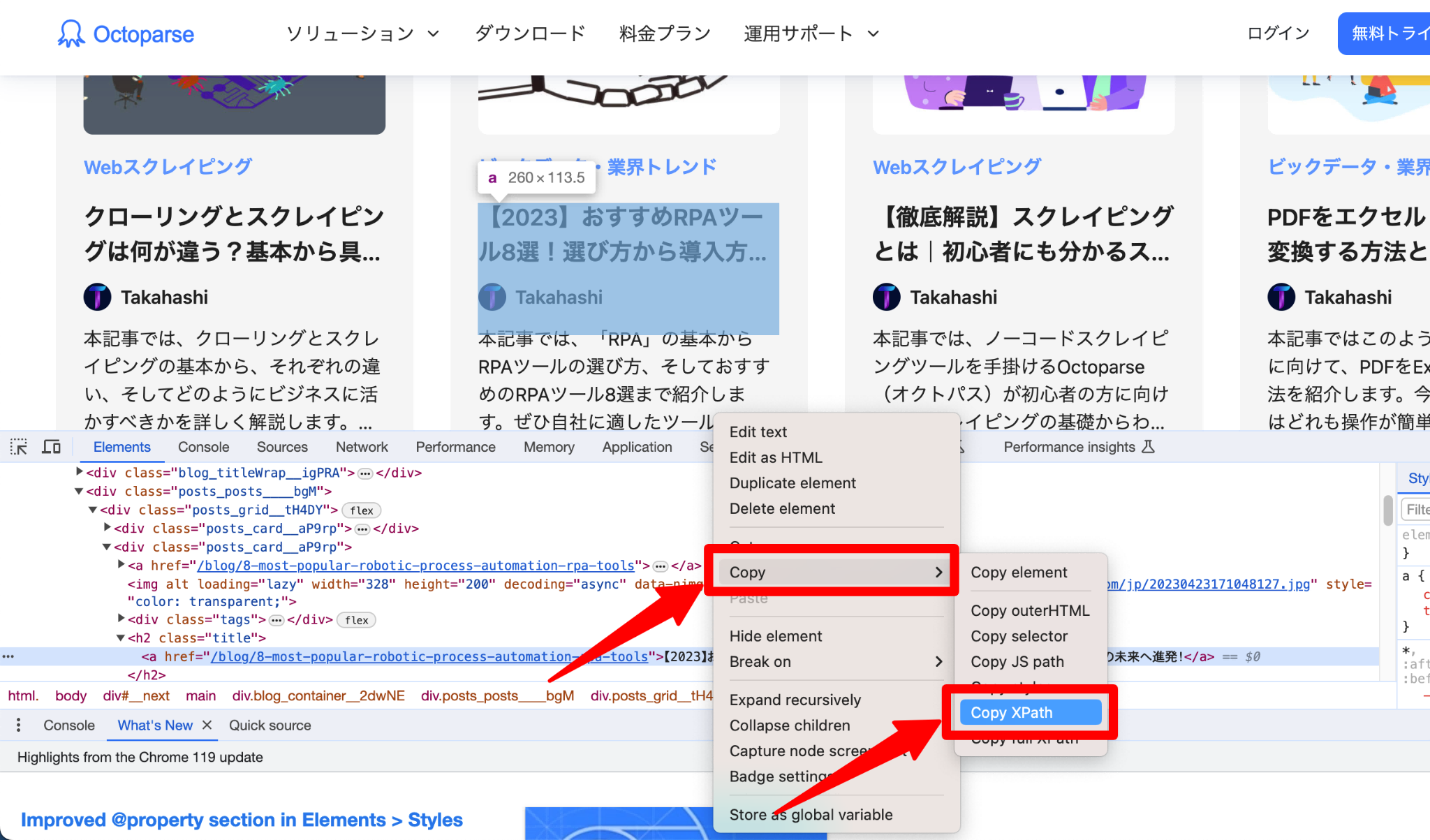
まず、要素となるXpathをコピーします。Xpathとは、マークアップ言語XMLに準拠した文書から特定の部分を指定する言語のことです。Xpathについて詳しく知りたい方は、以下の記事もご覧ください。
Xpathを取得するには、「タイトル> Copy > Copy XPath」の順にクリックします。
スプレッドシートなどに貼付けてもらえば、「//*[@id=”trendinggames”]/tbody/tr[1]/td[4]」というXpathが取得できていることがわかります。
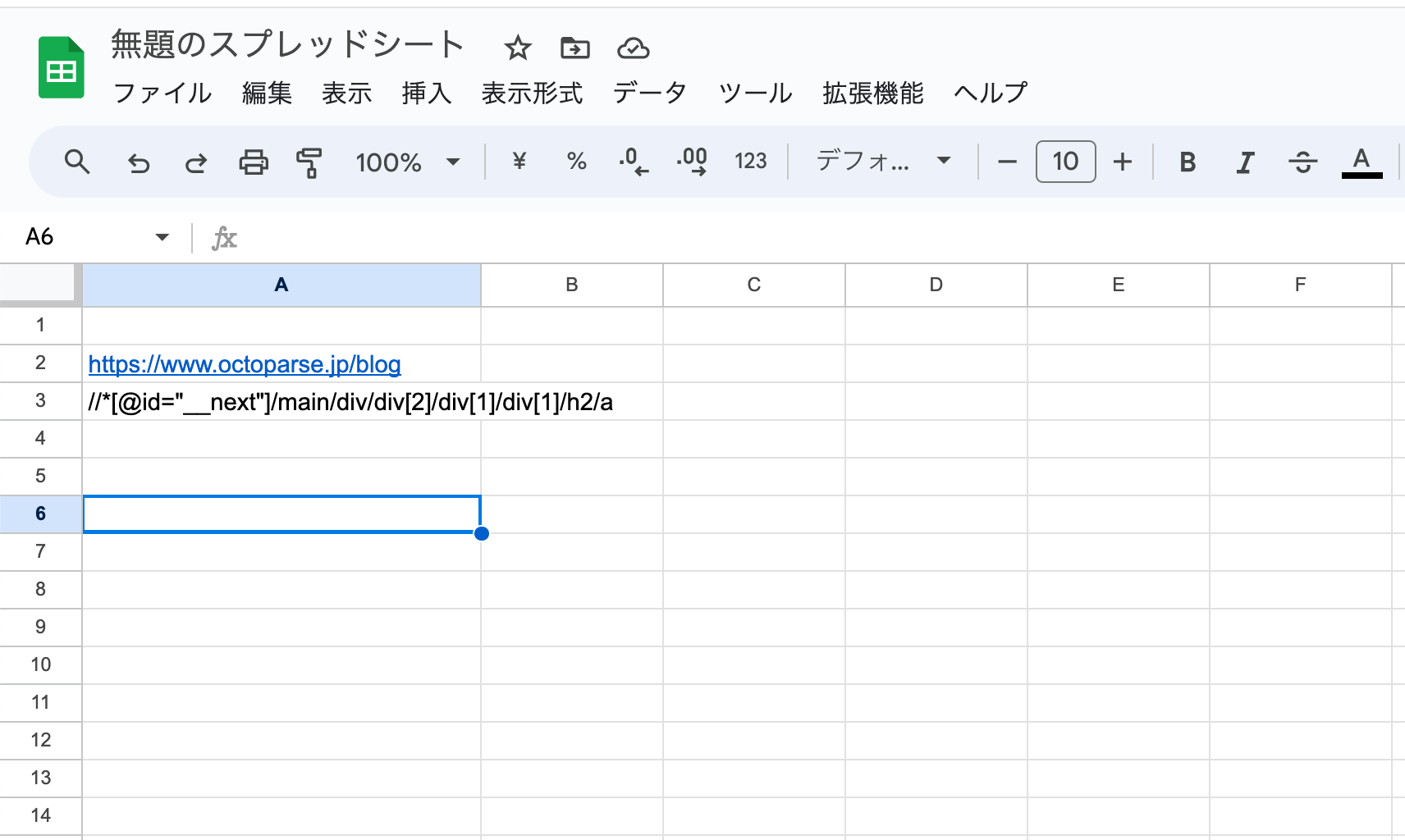
コピーしたXPathを、先程のスプレッドシート内(A3セル)に貼り付けます。
IMPORTXML関数の構文は以下の通りです。
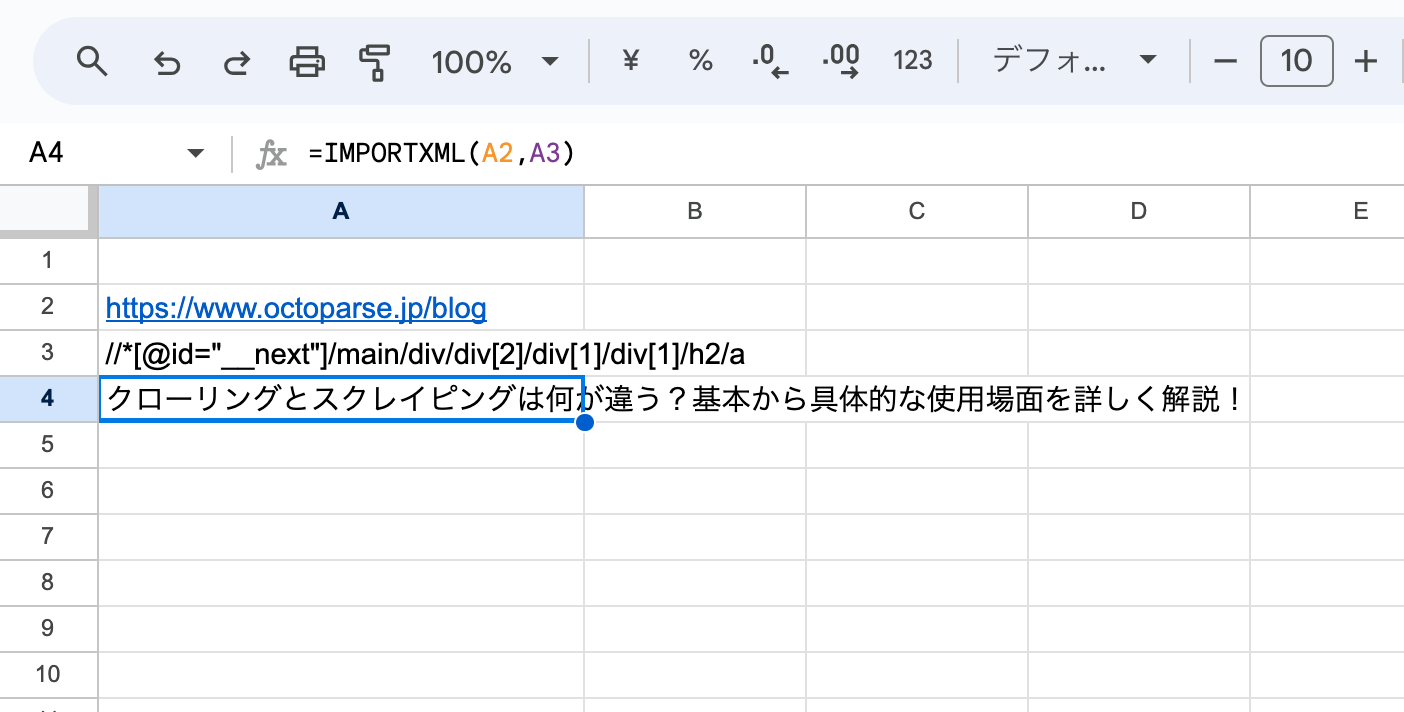
=IMPORTXML(URL, XPathクエリ)
したがって、A4に「=IMPORTXML(A2,A3)」と入力します。図のようにタイトルが表示されれば、成功です。
ノーコードツールでデータをスクレイピングする
次にWebスクレイピングツールのOctoparseを使って、同じ作業をどのように達成できるかを見てみましょう。
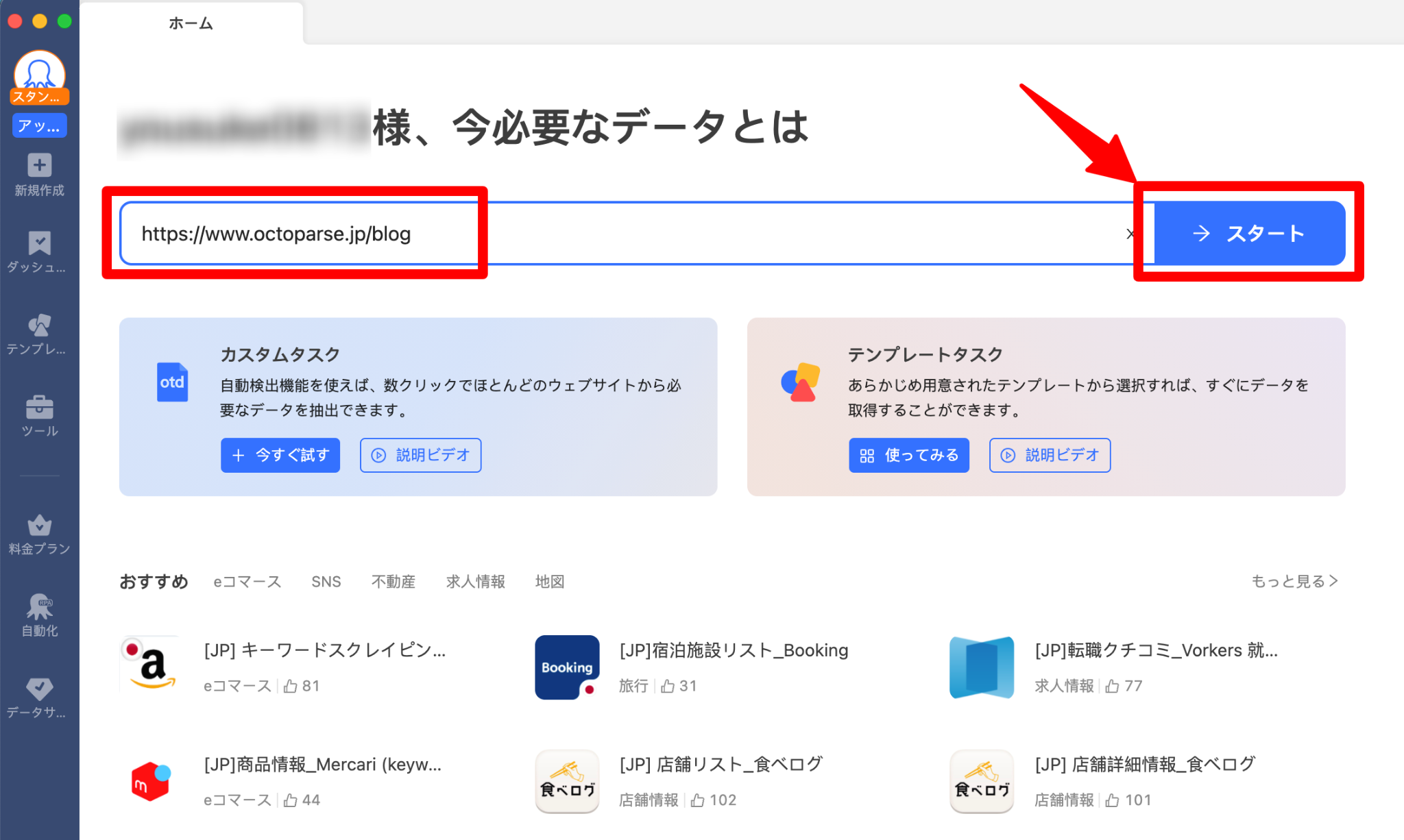
ステップ1:Octoparseでスクレイピングするサイトを開く
Octoparseを起動します。スクレイピングしたいWebページのURLを入力します。URLが検出されたら「抽出開始」 ボタンをクリックします。
ステップ2: Webページを識別する
画面が切り替わったら、操作ヒントのパネルから「Webページを自動識別する」をクリックします。すると、Webページの自動識別が始まるので、しばらく待ちましょう。
自動識別とは、自動的にページ上の必要なデータを検出して識別するという役立つ機能です。ポイント&クリックをする必要はなく、Octoparseは自動的に処理します。
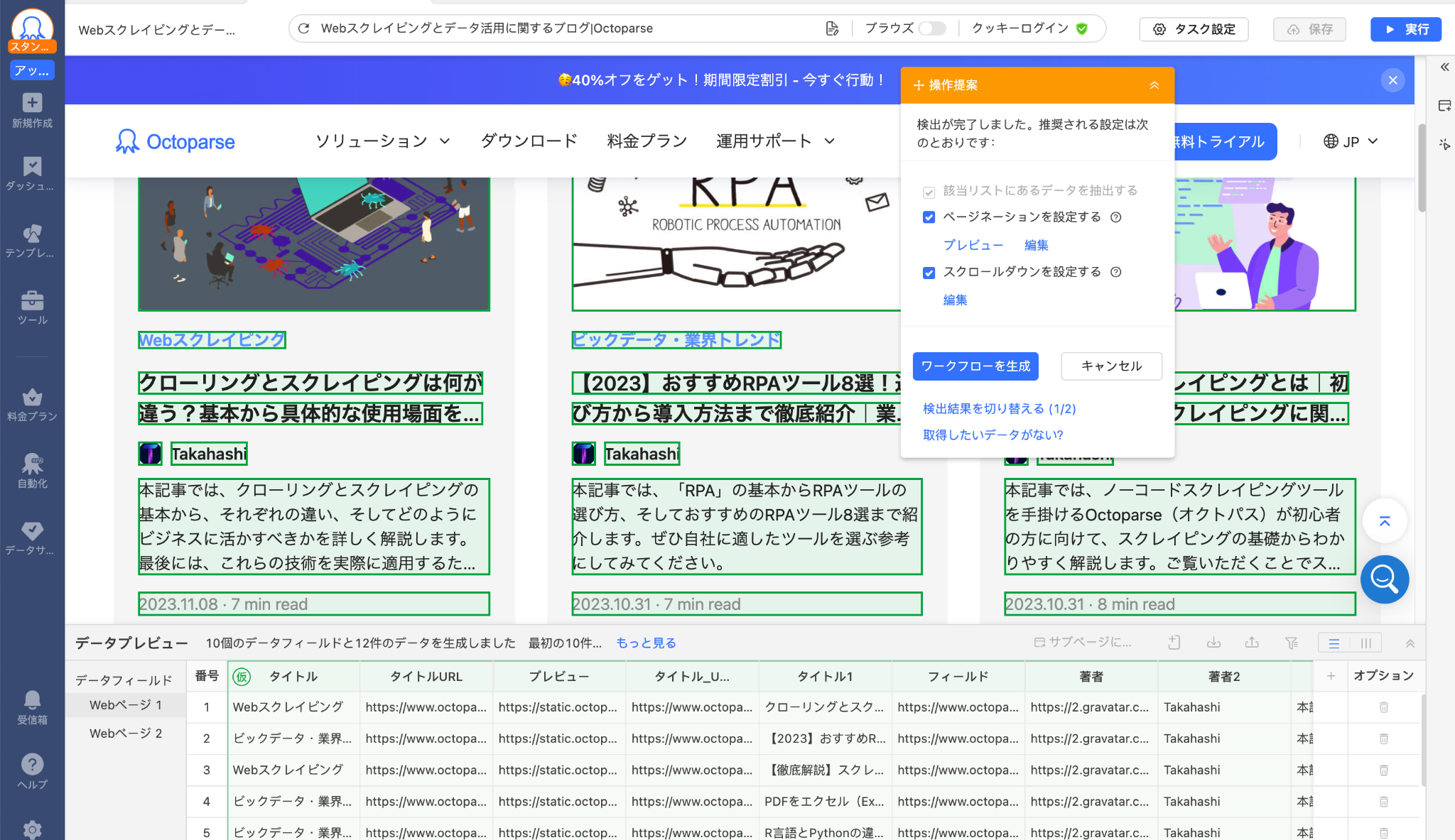
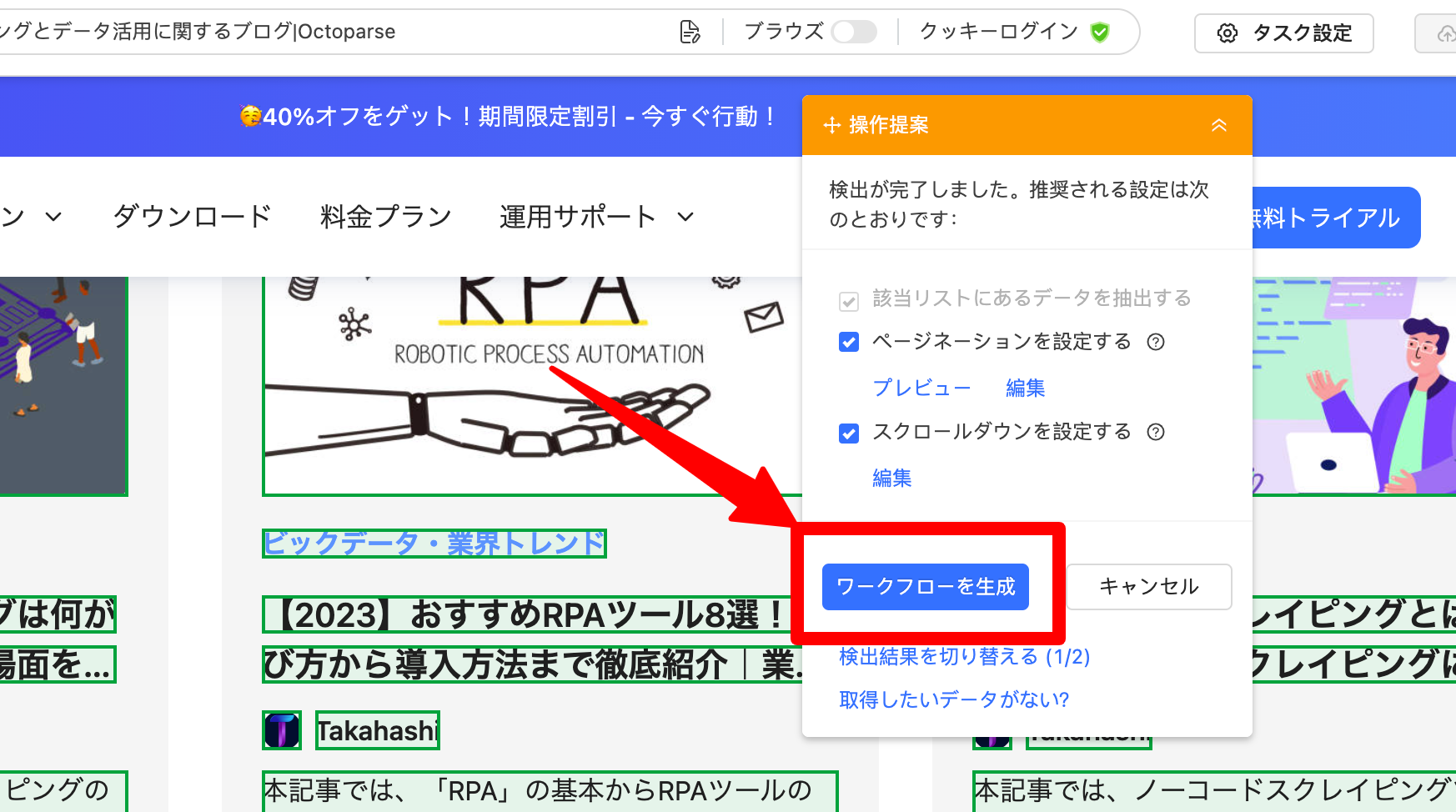
ステップ3:ワークフローを生成する
Webページの識別が完了すると、データプレビューで識別したデータが表示され、どのようなデータが取得されているか確認ができます。
抽出するデータに問題がなければ、「ワークフローを生成」のボタンをクリックして確認し、スクレイピングタスクを作成します。
ステップ4:タスクを実行する
ワークフローを確認して問題がなければ「実行」ボタンをクリックして、スクレイピングタスクを実行します。
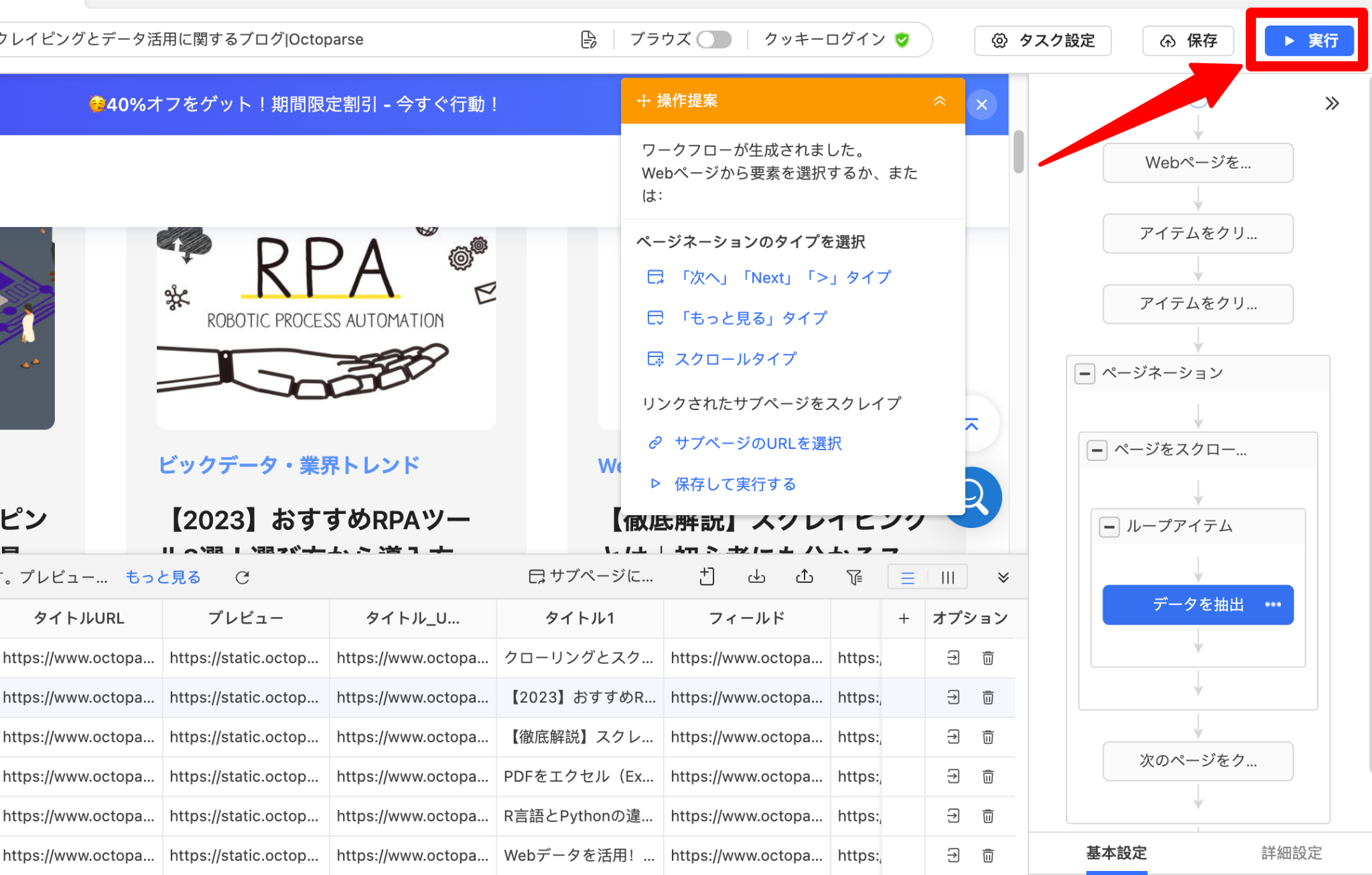
次にタスク実行方法の選択画面が表示されるので、「ローカル抽出」または「クラウド抽出」のどちらかを選択します。クラウド抽出は有料版のみ利用可能です。
いずれかを選択すると、スクレイピング実行中の画面が表示されますので、完了するまでしばらく待ちましょう。
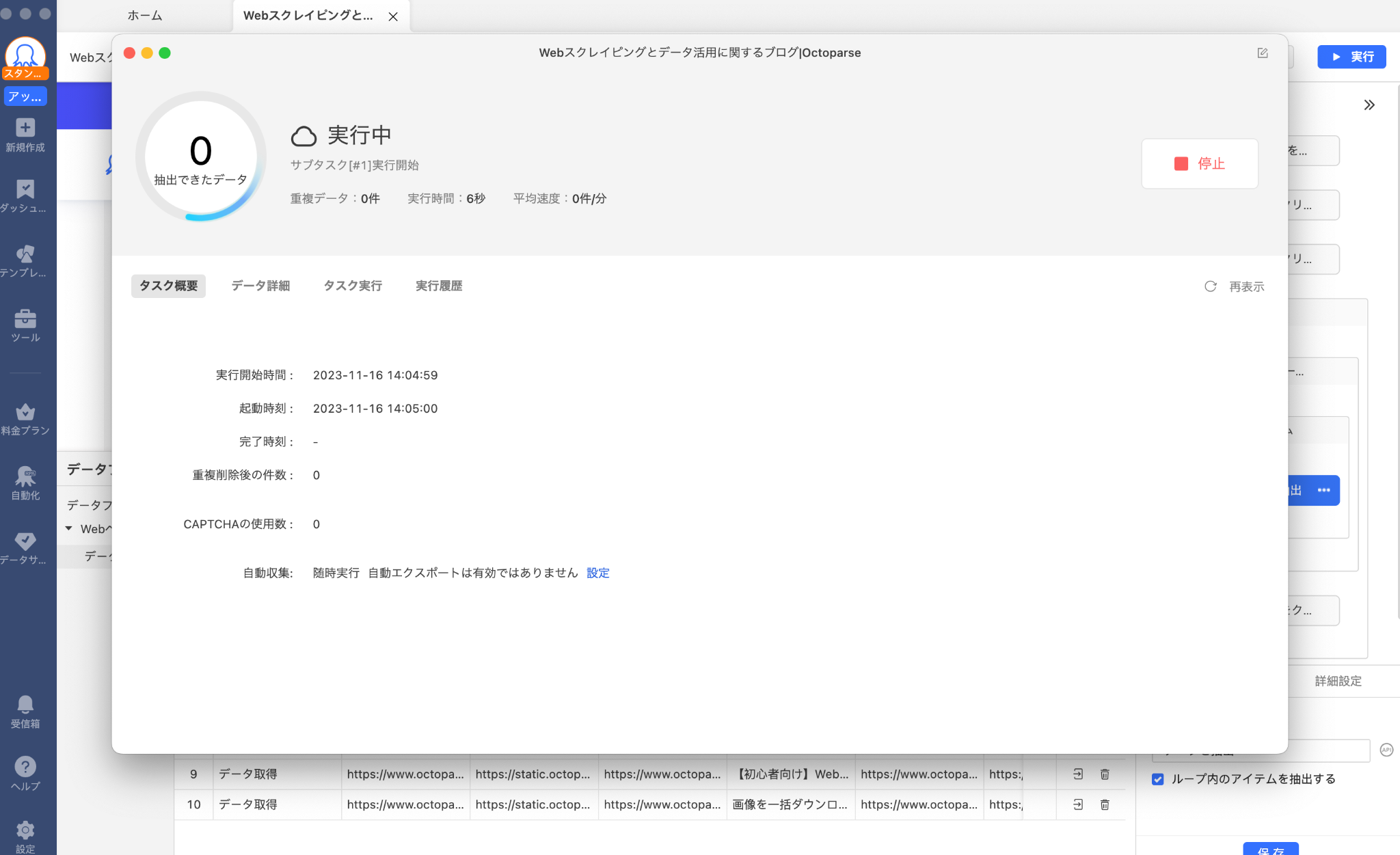
取得したデータは、xls、csvなどにエクスポートが可能です。Excelなどを使えば、抽出後のデータ加工も簡単にできます。
まとめ
今回は、WebページのデータをGoogleスプレッドシートで取得する方法と、Webスクレイピングで取得する方法をそれぞれ紹介しました。どちらの方法もPythonなどのプログラミングを使わずにかんたんにデータを取得できます。
ただし、近年ではWebページをスクレイピングできないように規制されていることも多く、IMPORTXML関数を使ったスクレイピングではデータを取得できない場合もあります。
その場合は、Webスクレイピングツールを使えば、Webスクレイピングを実行することができます。OctoparseではWebサイト側にスクレイピング と気づかれない機能が充実しています。
参考:スクレイピングテクニック – バレないようにする方法を解説
他にもスクレイピング未経験者がOctoparseを使うメリットはたくさんあります。
- 無料で使えるFreeプランを提供している
- ノーコード技術を使うためプログラミングの知識取得が不要
- 人気Webページのテンプレートが豊富ですぐに利用できる
https://www.octoparse.jp/template/google-search-scraper
https://www.octoparse.jp/template/google-maps-store-listing-scraper
興味がある方はぜひ使ってみてください。




