Webサイト上の情報を自動で収集したいと考えたとき、よく使われる言語の一つがPythonです。Pythonには、Webページへアクセスするためのライブラリや、HTMLを解析するためのライブラリ、ブラウザ操作を自動化するためのライブラリがそろっており、Webクローラーの開発にも活用されています。
中でもSeleniumは、実際のブラウザを操作しながらページを開けるため、JavaScriptで内容が表示される動的ページや、クリック・スクロールなどの操作が必要なページにも対応しやすいのが特徴です。
本記事では、PythonとSeleniumを使ってWebクローラーを作る基本的な流れを、初心者向けに解説します。Pythonクローラーの仕組み、必要な開発環境、Selenium 4に対応したサンプルコード、CSVへの保存方法、運用時の注意点まで順番に見ていきましょう。
Pythonクローラーとは?
Pythonクローラーとは、Pythonで作成されたWebクローラーのことです。Webクローラーは、Webページを自動で巡回し、ページ内の情報やURLを収集するプログラムを指します。
たとえば、ニュース記事の一覧ページから記事タイトルとURLを取得したり、複数ページに分かれた商品一覧から商品名や価格を集めたりする処理が、Pythonクローラーの代表的な利用例です。
ただし、Webサイトにはそれぞれ利用規約やrobots.txtなどのルールがあります。クローラーを作成する際は、技術的に取得できるかだけでなく、そのデータ取得が許可されているか、対象サイトに過度な負荷をかけない設計になっているかも確認する必要があります。
クローリングとスクレイピングの違い
クローリングとスクレイピングは似た文脈で使われますが、厳密には役割が少し異なります。
クローリングは、Webページを巡回し、リンクをたどりながらページやURLを収集する処理を指します。一方、スクレイピングは、取得したページの中から必要なデータを抽出する処理を指します。
たとえば、ECサイトの商品一覧ページをたどって複数の商品ページにアクセスする部分がクローリング、各商品ページから商品名・価格・レビュー件数などを取り出す部分がスクレイピングです。実務では、この2つを組み合わせてWebデータ収集を行うことが多くあります。
Pythonクローラー開発でよく使われるライブラリ
PythonでWebクローラーを作る場合、目的に応じて使うライブラリが変わります。代表的なものは以下の通りです。
| ライブラリ | 主な用途 | 向いているケース |
| requests | WebページのHTMLやAPIレスポンスを取得する | 静的ページやAPIからデータを取得したい場合 |
| BeautifulSoup | HTMLを解析し、必要な要素を抽出する | 取得したHTMLからタイトル・URL・本文などを取り出したい場合 |
| Selenium | ブラウザ操作を自動化する | JavaScriptで表示される動的ページ、クリックやスクロールが必要なページ |
| Scrapy | 本格的なクローリング処理を構築する | 大量ページを効率よく巡回し、継続的にデータ取得したい場合 |
Seleniumとは?
Seleniumは、Webブラウザの操作を自動化するためのライブラリです。指定したURLを開く、入力欄に文字を入れる、ボタンをクリックする、ページが読み込まれるまで待つ、といった操作をPythonコードで実行できます。
通常のHTML取得ではデータが見えないページでも、Seleniumを使えば実際のブラウザ表示に近い状態でページを開けるため、動的ページの取得に役立ちます。
Seleniumが向いているケース
Seleniumは、以下のようなページで特に役立ちます。
- JavaScriptでコンテンツが後から表示されるページ
- ボタンをクリックするとデータが切り替わるページ
- スクロールによって追加データが読み込まれるページ
- ログインや検索条件の入力など、ブラウザ操作が必要なページ
一方で、Seleniumは実際のブラウザを起動するため、requestsでHTMLを取得する方法に比べると処理速度は遅くなりがちです。大量のページを高速に取得したい場合は、Seleniumだけに頼るのではなく、APIや静的HTMLの取得、Scrapyなどの選択肢も検討しましょう。
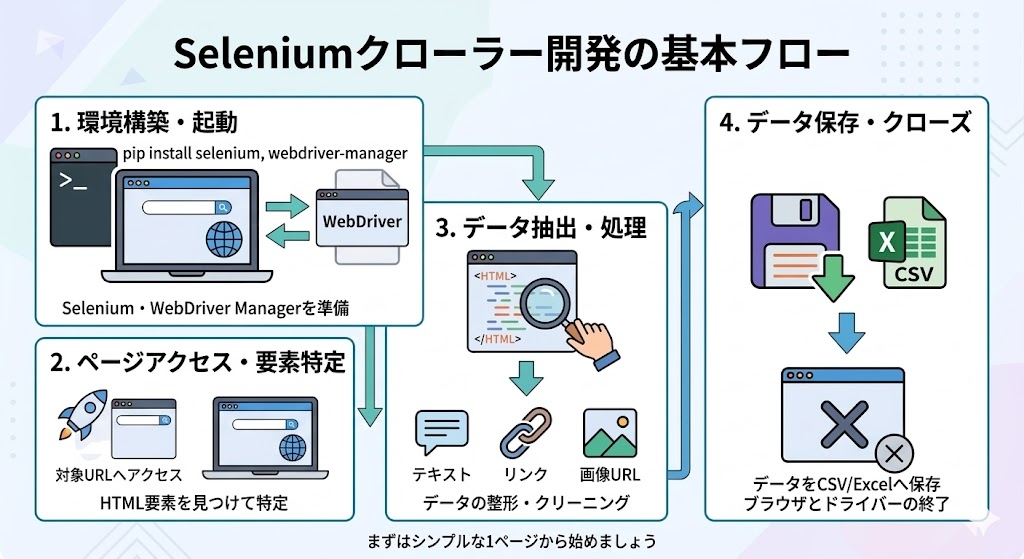
PythonとSeleniumでWebクローラーを作る準備
PythonでSeleniumを使うには、まずPython本体とSeleniumをインストールします。必要に応じて、HTML解析用のBeautifulSoupや、WebDriver管理を補助するwebdriver-managerを追加することもあります。
Selenium 4.6以降では、Selenium Managerによってブラウザドライバーの管理が自動化されているため、環境によってはChromeDriverを手動でダウンロードしなくても、以下のように簡単にChromeを起動できます。
必要に応じてwebdriver-managerを使う場合は、以下もインストールします。
Selenium Managerを使う基本例
# Selenium 4.6以降では、基本的にSelenium ManagerがWebDriverを自動管理します。
環境によってドライバーの自動管理がうまくいかない場合は、webdriver-managerを使って明示的にChromeDriverを指定する方法もあります。
webdriver-managerを使う場合の書き方
サンプルコード:ページ情報を取得してCSVに保存する
ここでは、Seleniumでページを開き、ページ内のリンクテキストとURLを取得してCSVファイルに保存する簡単な例を紹介します。
実際の記事一覧ページや商品一覧ページで利用する場合は、CSSセレクターを対象サイトの構造に合わせて調整してください。
このコードでは、まずChromeブラウザを起動し、指定したURLを開きます。その後、ページのbody要素が読み込まれるまで待機し、ページ内のaタグを取得します。最後に、リンクのテキストとURLをCSVファイルに保存します。
ポイントは、単にページを開くだけでなく、WebDriverWaitを使ってページの読み込みを待っている点です。動的ページでは、ページを開いた直後に要素を取得しようとすると、まだデータが表示されておらず、空白データやエラーになることがあります。
複数ページを巡回するPythonクローラーの考え方
「python クローラー」というキーワードで検索する読者は、1ページだけではなく、複数ページを自動で巡回する方法を知りたいケースが多いです。
複数ページを巡回する場合は、取得済みURLを記録し、同じページを何度も取得しないようにすることが重要です。また、対象サイトへの負荷を抑えるため、ページごとに待機時間を入れ、取得範囲を必要最小限に絞ることも大切です。
この例では、最初のURLからリンクを取得し、同じドメイン内のURLだけを順番に巡回します。実運用では、取得対象のURLパターンを絞り込んだり、robots.txtや利用規約を確認したり、エラー発生時のリトライ回数を制限したりする設計が必要です。
Pythonクローラーを作る際の注意点
1. 利用規約とrobots.txtを確認する
Webサイトによっては、自動取得やスクレイピングを制限している場合があります。クローラーを作成する前に、対象サイトの利用規約、robots.txt、APIの有無を確認しましょう。
robots.txtは法的な契約そのものではありませんが、クローラーに対するサイト側のクロール方針を示す重要な情報です。禁止されているパスやクロール頻度の指定がある場合は、それに従う設計にすることが望ましいです。
2. アクセス間隔を空ける
短時間に大量アクセスを行うと、対象サイトに負荷をかけるだけでなく、403エラー、429エラー、CAPTCHA表示などが発生する可能性があります。
クローラーを運用する際は、ページごとに待機時間を入れ、同時実行数を抑え、まずは小規模なテストから始めることが大切です。
3. 取得範囲を絞る
Webサイト全体を無差別に巡回するのではなく、目的に合ったページだけを対象にしましょう。たとえば、商品一覧、記事一覧、店舗詳細など、必要なURLパターンを事前に決めておくと、無駄なアクセスを減らせます。
取得範囲を絞ることは、処理時間の短縮だけでなく、サイトへの負荷軽減やデータ品質の向上にもつながります。
4. エラー時のリトライ設計を入れる
ネットワークの一時的な不安定さやページ読み込みの遅延により、クローラーが途中で失敗することがあります。
そのため、実運用では、一定回数だけリトライする、失敗したURLをログに残す、取得済みデータを途中保存する、といった設計を入れておくと安定性が高まります。
5. 動的ページではAjax通信も確認する
JavaScriptで表示されるページでは、画面上のデータがAjax通信によって取得されている場合があります。ブラウザの開発者ツールでNetworkタブを確認すると、実際にはAPIレスポンスとしてデータが取得されているケースもあります。
その場合、Seleniumで画面を操作するよりも、公式APIや許可されたデータ取得方法を使ったほうが安定することがあります。まずは対象サイトが提供しているAPIやデータ提供方法を確認しましょう。
よくあるつまずき
Pythonでクローラーを作り始めると、最初にぶつかりやすいポイントがいくつかあります。
| つまずき | 確認・対処ポイント |
| 要素が見つからない | ページ構造が変わっている、CSSセレクターが正しくない、iframe内の要素を取得しようとしている、ページ読み込み前に取得している、などが原因として考えられます。まずは開発者ツールで対象要素を確認し、必要に応じてWebDriverWaitを使いましょう。 |
| 空白データになる | JavaScriptによる表示が完了していない、スクロールしないとデータが表示されない、Ajax通信のレスポンスを待てていない、などが考えられます。待機処理やスクロール処理を見直しましょう。 |
| 403・429エラーが発生する | アクセス頻度が高すぎる、同時実行数が多い、対象サイトが自動アクセスを制限している、などの可能性があります。まずは取得範囲、待機時間、実行頻度を見直し、対象サイトのルールを確認しましょう。 |
| コードが急に動かなくなる | サイト側のHTML構造やclass名が変更されると、これまで動いていたコードが失敗することがあります。定期的なメンテナンスやセレクターの見直しを前提にしましょう。 |
Pythonでの開発が向いている人・向いていない人
Pythonでクローラーを作る方法は、細かい処理ロジックを自分で制御したい場合や、社内システム・データベース・分析基盤と連携したい場合に向いています。
たとえば、取得対象URLを独自ルールで制御したい、取得後にデータ加工や機械学習処理につなげたい、社内の既存ツールと組み合わせたい、といったケースではPython開発の自由度が役立ちます。
一方で、できるだけ早くデータ取得を始めたい場合や、非エンジニアが運用する場合、コードの保守に時間をかけられない場合は、Pythonで自作するよりもノーコードツールを使ったほうが効率的なこともあります。
| Python開発が向いているケース | ノーコードツールが向いているケース |
| 細かいロジックを自由に実装したい | できるだけ早くデータ収集を始めたい |
| 社内システムやDBと連携したい | 非エンジニアでも運用できる方法を探している |
| エンジニアが継続的に保守できる | コードの保守や環境構築に時間をかけたくない |
| 大規模・複雑な処理を自社仕様で組みたい | 営業リスト作成、価格調査、レビュー収集などをすぐ業務に使いたい |
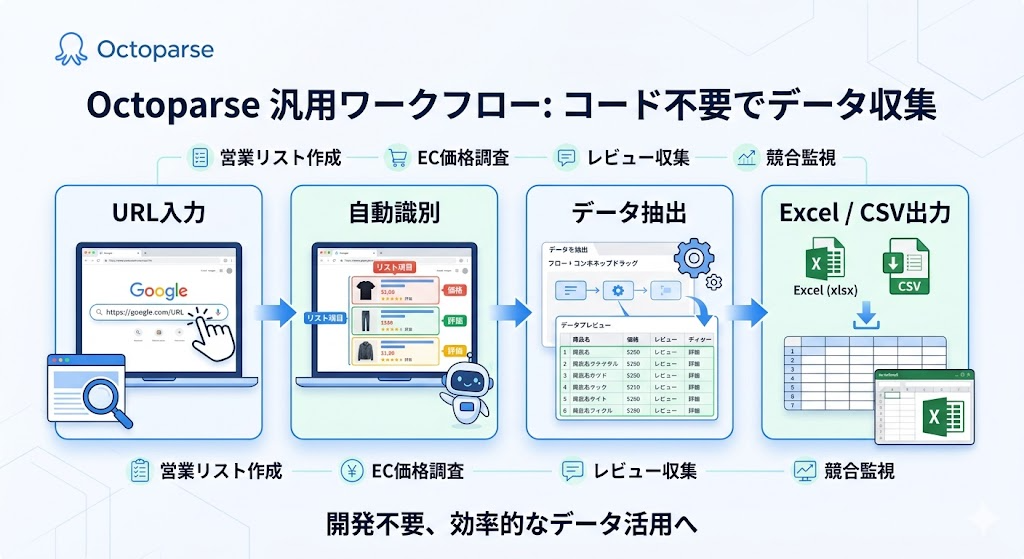
コード不要で始めたいなら、Octoparseという選択肢もある
もし「Pythonを書くのはハードルが高い」「まずは動く形で早く試したい」と感じる場合は、
ノーコードで使えるスクレイピングツールを選ぶ方法もあります。
Octoparse なら、取得したいページのURLを入力し、ページ上のデータを自動識別したうえで、そのまま抽出フローを作成できます。
クリックやページ送り、スクロールなども画面上で設定できるため、コードを書かずにデータ取得を始めたい方には使いやすい選択肢です。
特に、営業リスト作成、EC価格調査、レビュー収集、競合監視など、
「まずデータ収集を業務で回したい」ケースでは、開発よりも運用のしやすさが重要になることも多いでしょう。
その場合、最初からツールを使うほうが効率的です。
まとめ
PythonとSeleniumを使えば、Webページを開き、必要な要素を取得し、CSVに保存する基本的なWebクローラーを作成できます。特にSeleniumは、JavaScriptで表示される動的ページや、クリック・スクロールなどのブラウザ操作が必要なページで役立ちます。
ただし、実務で継続的に使う場合は、ページ構造の変更、待機処理、エラー時のリトライ、取得済みURLの管理、robots.txtや利用規約の確認など、運用面の設計も欠かせません。
柔軟性を重視するならPython、スピードと運用のしやすさを重視するならOctoparseのようなノーコードツール、という形で目的に合わせて選ぶのがおすすめです。まずは小規模なテストから始め、安定性を確認しながら取得範囲を広げていきましょう。

競合情報も営業リストも、ウェブデータをそのままExcel・CSV・Google Sheetsに出力
コード不要、誰でも今日から。クリック操作だけで必要な項目を自動抽出
Google Maps・食べログ・iタウンページ向けテンプレートで、リード獲得をすぐに開始
クラウドで毎日・毎週自動実行。大量取得でも安定して、競合動向を常に把握
MCP対応でAIエージェントと連携。収集データをAIに渡して分析・活用まで一気通貫
クレジットカード不要で無料スタート。世界600万人以上が選んだ信頼のツール



